
ML Case-study Interview Question: Automating Merchant Identification and Categorization with Machine Learning Classification


Case-Study question
You are working at a financial technology startup building a corporate credit card. The leadership wants each transaction to display a clear “doing business as” name, a website, and an accurate expense category. Initially, support agents manually searched for each new merchant’s name and category. As transaction volume grew, this manual method became unsustainable. You must design an automated system to identify and classify new merchants. The company expects thousands of new merchants daily, many with ambiguous network descriptors like “TST* LITTLE SKIL,” “AMZN Mktp CA,” or partial references to card processors. How will you architect and implement a solution that can:
Straight away transform raw network descriptors into a recognized merchant name and website. Automatically categorize each identified merchant into one of several key business expense categories. Minimize human labor and costs while maintaining high accuracy. Continuously improve over time and adapt to new merchants.
Explain your proposed end-to-end pipeline. Include details on: Data ingestion and orchestration. Any external services or crowdsourcing platforms for merchant data lookups. One or more machine learning classifiers to handle categorization. Quality assurance mechanisms for monitoring and maintaining high accuracy. Strategies for retraining or updating models as new data arrives.
Detailed Solution
A system to classify and label credit card merchants requires two main steps: identification and categorization. Identification replaces cryptic descriptors with a clear merchant name and website. Categorization assigns each merchant to the correct expense category. The overall approach uses a workflow orchestrator (such as an interval-based job scheduler) to batch transactions and route each merchant through several components until the pipeline either completes automatically or flags any unresolved records for manual review.
Identification
Raw network data often contains partial descriptors with extra text. A typical descriptor might read “WPY* STOREX” or “SQ* MyCoffee.” The system removes these references (for example, “WPY*” or “SQ*”) and appends the city to help an external geolocation-based service find the correct merchant. The service returns a list of potential matches with location tags. If no match is found or confidence is too low, a crowdsourcing platform steps in. Workers on that platform see the descriptor and city, then search online to provide the best match.
Any final identified merchant name becomes the single source of truth. The system stores the website (if available) and proceeds to categorization. If both the external service and crowdsourcing platform cannot provide high-confidence matches, the pipeline sends the record to the internal support team.
Categorization
The next step is automatically assigning the expense category from a predefined set (for example, Travel, Dining, and others). This process includes two supervised machine learning classifiers.
One classifier handles merchants identified through the external service. It uses:
The identified merchant name.
The Merchant Category Code (MCC), a four-digit indicator in the network data.
A set of tags returned by the external service that describes the merchant type (for example, “restaurant,” “bakery,” “gym,” etc.).
A second classifier handles merchants identified by the crowdsourcing platform. It does not rely on tags (since only a manually found name might be available). Both classifiers follow a multi-class logistic regression approach.
Feature Representation
MCC is one-hot encoded because it is categorical. Merchant names are transformed into vector representations. An effective strategy is to use a pre-trained language model that produces sentence embeddings. Another simpler method is to tokenize words and apply count vectorization, although pre-trained embeddings can capture similarities in synonyms or rarely seen phrases.
Core Formula for Multi-Class Logistic Regression
Below is a core formula for multi-class logistic regression in big font, using latex in its own line and centered:
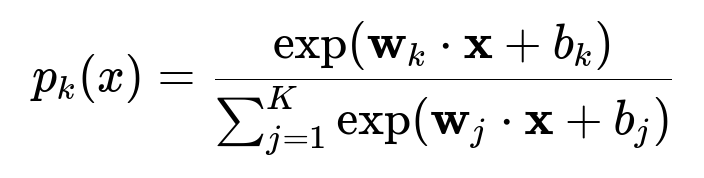
Here, p_{k}(x) is the probability that feature vector x belongs to category k. Each category k has its own weight vector w_{k} and bias b_{k}. The model predicts the category with the highest p_{k}(x). Training involves finding weight vectors that minimize a loss function (typically cross-entropy) over the labeled examples.
Acceptance Criteria and Retraining
Predictions above certain probability thresholds are accepted automatically. Each category might have its own threshold to guarantee high precision. Any predictions below those thresholds are routed to the crowdsourcing platform. If the crowdsourced results also appear ambiguous (for instance, conflicting answers among multiple workers), the merchant is flagged for final resolution by the support team. The model retrains monthly on fresh labeled data to adapt to changes in real-world merchant distributions.
Workflow Orchestration
A workflow tool runs every few hours and: Pulls new merchant descriptors and deduplicates them. Cleans the descriptors to remove known prefixes. Queries the external service. If identification is confident, it proceeds to the classification model. Otherwise it triggers tasks on the crowdsourcing platform. Classifies the merchant using logistic regression. If probability thresholds are not met, it requests manual help for classification. Performs final validation and stores the result in the database.
Human Oversight and Quality Assurance
A small random sample of automatically processed merchants is always rechecked by the support team. This ensures ongoing performance monitoring. If the error rate surpasses a set threshold, the pipeline triggers an alert for immediate investigation.
Example of a Simple Code Snippet
In Python, the part that converts merchant names to embeddings (for example, using a library) might look like this:
import numpy as np
def encode_merchant_name(name, embedding_model):
vector = embedding_model.encode(name)
return vector
def prepare_training_data(samples, embedding_model):
X = []
y = []
for sample in samples:
vector = encode_merchant_name(sample['merchant_name'], embedding_model)
mcc_vec = one_hot_encode_mcc(sample['mcc'])
full_vec = np.concatenate([vector, mcc_vec])
X.append(full_vec)
y.append(sample['category_label'])
return np.array(X), np.array(y)
This code converts names to numerical embeddings, concatenates MCC features, and prepares training arrays for logistic regression.
Follow Up Question 1
Why not use just the Merchant Category Code (MCC) to classify the merchant?
Answer and Explanation: MCC sometimes mismatches actual business categories. A hotel gift shop might share the same MCC as lodging. Some small businesses register under general codes. The system needs additional signals to improve accuracy, especially merchant name text. MCC alone fails when the code is too generic or unreliable, so combining MCC with text-based and external tagging features yields better predictions.
Follow Up Question 2
How do you ensure consistent quality when using crowdsourcing workers for identification and categorization?
Answer and Explanation: The system implements several controls. It displays clear step-by-step instructions and examples to workers. It administers short qualification tests, promoting only those who pass. It enforces agreement checks by assigning multiple workers per task. When at least two out of three workers match, the system accepts that result. Conflicts trigger another assignment or escalate to the support team. Offering performance-based incentives and restricting tasks to a high-quality pool further ensures reliable responses.
Follow Up Question 3
What if a newly identified merchant frequently changes business categories, such as a cafe that also functions as a co-working space?
Answer and Explanation: A periodic retraining pipeline allows the model to learn new patterns. When certain merchants exhibit variable patterns, the system sees contradictory labels over time. The training dataset updates monthly, capturing these new examples. If a merchant is flagged with conflicting categories, a temporary fallback can rely on a final human check. The model eventually learns from updated labels that reflect the actual distribution of categories. The system might also maintain a versioned approach, merging older data with new data in retraining.
Follow Up Question 4
How do you handle ambiguous descriptors that external services or crowdsourcing platforms cannot resolve?
Answer and Explanation: Any unresolved descriptors go straight to the internal support team, which performs deeper research. The pipeline maintains logs of repeated failures to identify or classify so support can make specialized decisions (for instance, looking at the transaction history or contacting the user who made the purchase). This feedback data enters the labeled dataset for future training cycles.
Follow Up Question 5
How do you monitor this system in production to detect drifting performance?
Answer and Explanation: The system continuously samples a portion of automatically processed merchants for manual review. Internal dashboards track metrics such as acceptance rates, classification confidence, error rates, and distribution of categories. If the error rate climbs or the distribution shifts significantly, an alert notifies the data science team. They can examine performance logs, re-check the model’s feature drift, and, if needed, retrain the model or adjust acceptance thresholds. A monthly retraining schedule also helps in catching and correcting drift early.
That is the complete case study, solution, and discussion of possible follow-up questions with in-depth explanations of the reasoning and practical implementation details.