
ML Case-study Interview Question: Enhanced RAG and Vector Search for Reliable Multi-Turn Documentation Chatbots


Browse all the ML Case-Studies here.
Case-Study question
A large technology organization wants to build a generative AI chatbot for its product documentation. They have extensive reference material spanning multiple products and versions. They want the chatbot to answer user questions in natural language and provide accurate links to relevant documentation sections. They initially tried a simple retrieval augmented generation (RAG) approach with basic text-chunking and embedding into a vector-search engine. However, they found that it returned inconsistent responses, irrelevant links, and failed to handle user follow-up queries. They want you, as a senior data scientist, to propose a scalable production solution to address these shortcomings, keep information updated as documentation changes, and handle multi-turn conversations in a user-friendly way. How would you structure this system, what improvements would you make, and how would you ensure relevant answers grounded in the latest product documentation?
In-Depth Solution
Overview
Design a pipeline that ingests documentation data in a reliable, automated process and uses a refined retrieval augmented generation approach. Split the documentation into vector-embedded chunks, store them in a cloud-based NoSQL database with native vector indexing, and leverage a large language model (LLM) to generate responses with relevant references. Maintain multi-turn context and incorporate query preprocessing for better results.
Data Ingestion
Create a script that fetches all product documentation pages regularly. Convert each page into raw text or Markdown. Store these raw pages in a collection (for example, pages). Run a second step that splits large pages into smaller chunks, each annotated with metadata such as page title, tags, product name, and date updated. Filter out chunks under a minimal length to avoid meaningless matches. Generate embeddings for each chunk using an LLM embedding service. Store the final chunks in another collection (for example, embedded_content), together with their vectors indexed for approximate similarity search.
Vector Search
Use a built-in vector similarity operator in the NoSQL database. This operator takes a user query embedding and returns chunks ordered by highest similarity. The system relies on cosine similarity:
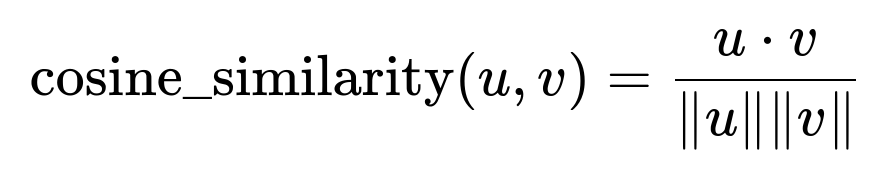
u and v are vector embeddings of dimension d. u dot v is the dot product of u and v. ||u|| and ||v|| are their Euclidean norms.
Query Preprocessing
Implement a query preprocessor that enriches short or ambiguous user messages. For instance, if the user says “$filter,” transform it to a question with added metadata: “What is the syntax for filtering data?” and specify relevant tags or product names if you can infer them from context. This step boosts the semantic fidelity of the vector search and helps the language model formulate clearer answers.
Multi-turn Conversation
Store user messages and bot responses in a conversations collection. On each new user message, retrieve past conversation context. Supply the last few message pairs to the LLM so it can maintain continuity. Restrict chunk retrieval to the relevant products or versions inferred from the conversation. Generate the final answer based on the top chunks, and include relevant URLs at the end.
Example Server Logic
Use a lightweight Node.js Express server that:
Receives the user message and conversation ID.
Runs a query preprocessor step to refine or block inappropriate requests.
Retrieves the top n chunks from the vector search index.
Calls the LLM completion endpoint with a prompt that includes the conversation context and the retrieved chunks.
Streams or returns the final text response to the user.
Persists the user message and AI response in the conversation log.
Keeping Embeddings Updated
Schedule a cron job that checks for changes in documentation. If a page changed significantly (new headings, added text, or large revisions), re-chunk and re-embed that page. If only a trivial change happened (like a minor typo), you might skip re-embedding or queue it for low-priority update to control costs.
Practical Considerations
Maintain robust logging for each user query, vector search results, and final LLM response. Flag any low-confidence answers with a fallback message or a clarifying question. Continuously monitor overall quality by sampling user sessions for correctness. Iterate often to refine chunking, metadata annotations, and query preprocessing.
Possible Follow-Up Questions
How would you handle the multi-product scenario where different products have overlapping concepts?
Partition the content by product line and inject product tags into both chunk metadata and user queries. Keep them aligned so the vector search narrows down to the right subset. If the user’s question references multiple products, store that context in the conversation. Restrict top matches to chunks sharing any of the product tags. Return an answer that merges relevant sections without repeating the same product’s details.
How do you handle hallucinations where the LLM fabricates explanations or links?
Implement answer verification. Limit the LLM’s temperature parameter to reduce creative speculation. Only allow references to appear if they come from top retrieved chunks. Post-process the final answer to confirm any cited URLs appear in the chunk metadata. If an LLM references something absent from retrieved chunks, remove or correct it before returning the final answer.
How do you address performance and latency at scale when user traffic is high?
Pre-warm embeddings for frequent queries, especially for popular pages. Keep an efficient indexing strategy, possibly with approximate nearest neighbor search to reduce query time. Parallelize the chunk retrieval process if the database supports concurrency. Cache results of common queries at the application layer. Use streaming responses from the LLM so the user sees the answer being generated incrementally, improving perceived performance.
How would you test and iterate this system before production?
Run red-team exercises with internal experts. Have them try complex queries, incomplete questions, or ambiguous prompts. Collect logs of failures or substandard answers. Tweak chunk sizes, metadata fields, or query-preprocessing prompts. Retest in short feedback cycles. Measure improvements in retrieval accuracy, conversation continuity, and link relevance.
What if the user’s query is too vague or fails to match any chunk with sufficient similarity?
Return a clarifying question. For instance, “Which feature or product version are you interested in?” This approach ensures users refine their query. Set a minimum similarity threshold. If no result exceeds that threshold, prompt the user to provide more context. If they do not, offer a fallback option to browse an FAQ or official docs index.
How would you integrate code examples in the chatbot’s replies?
Include code snippets in the stored documentation chunks. Detect code blocks during chunking. Merge them into a single chunk if it makes sense semantically. When these chunks appear in the top vector search results, the LLM can incorporate the code snippet. Confirm the snippet’s correctness by storing version or language tags in the metadata, ensuring the snippet applies to the user’s environment.