
ML Case-study Interview Question: Real-Time ETA Prediction using Multi-Model Architecture for On-Demand Services


Browse all the ML Case-Studies here.
Case-Study question
You are leading a data science team at a major on-demand service platform. You need to build an Estimated Time of Arrival model for multiple stages in the order lifecycle. The business wants dynamic, real-time estimates shown to the customer. The solution must consume real-time signals such as delivery executive availability, live location pings, restaurant stress, and item-based preparation times. Propose your end-to-end approach, covering data sourcing, feature engineering, modeling pipeline, and final integration with the tracking system. Explain how you would handle errors, delays due to external factors (weather, traffic, rejections), and scaling across thousands of restaurants. Suggest an architecture that breaks down the overall ETA into different segments (order placement, assignment, pickup wait, last-mile). Show how each segment’s predictions get updated dynamically in real-time with new signals.
Detailed Solution
Overview of the Multi-Model Architecture
A robust ETA system uses separate models for each leg of the order’s journey. Separating the journey into distinct segments allows specialized features and more accurate predictions. Each segment processes unique signals tied to that stage.
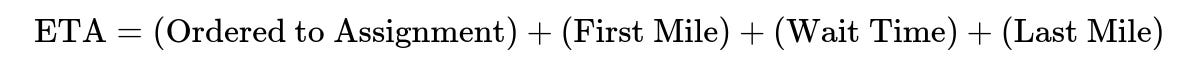
The first leg estimates time from order placement until the Delivery Executive is assigned. The second leg estimates travel time for the Delivery Executive to arrive at the restaurant. The third leg estimates the waiting duration at the restaurant. The final leg estimates travel time from pickup to drop-off.
Ordered to Assignment Model
This model starts predicting right after the order is created in the system. It integrates:
Restaurant-level preparation times (based on historical data, menu items, current load).
Delivery Executive availability around the restaurant’s vicinity.
System-level signals like rejections, overall traffic, or any spike in orders.
It also updates predictions when new signals come in, for instance if many Delivery Executives are near the restaurant and available sooner.
First Mile Model
This model starts once an order is assigned to a Delivery Executive. It enriches its predictions with:
Historical travel speeds for that particular Delivery Executive or the typical speed in that region.
Real-time location pings, verifying speed, heading, and distance to the restaurant.
Mode of transportation, because bicycles or certain vehicles have different speed profiles.
It continuously refines the arrival estimate at the restaurant as pings update.
Wait Time Model
This model becomes active once the Delivery Executive arrives at the restaurant. It looks at:
Real-time kitchen load, factoring in item complexity and number of orders in queue.
Time elapsed since the restaurant began preparing the food.
External factors like weekend rush or staff capacity changes.
It outputs how long it takes for the Delivery Executive to receive the order.
Last Mile Model
This model takes over at pickup. It relies on:
Travel distance to the customer’s address and typical route conditions.
Delivery Executive’s real-time speed (taken from pings).
Traffic conditions, weather, and region-specific patterns.
It generates the final time to delivery completion.
Implementation Notes
A real-time system triggers each model periodically or on key events (order assignment, arrival at restaurant, pickup). Predictions overwrite the previous estimate so customers see updated ETA whenever circumstances change. An internal data pipeline streams relevant signals (e.g., location pings, restaurant load, item details) into a feature store. The service layer fetches new features at each model call.
Example Python skeleton for a streaming data pipeline might look like:
import time
def fetch_realtime_signals(order_id, stage):
# Connect to streaming system or feature store
signals = get_features(order_id, stage)
return signals
def predict_eta(model, signals):
prediction = model.predict(signals)
return prediction
def update_order_eta(order_id, new_eta):
# Write back to database
save_eta(order_id, new_eta)
while True:
orders_in_flight = get_active_orders()
for order_id, current_stage in orders_in_flight:
signals = fetch_realtime_signals(order_id, current_stage)
stage_model = load_model_for_stage(current_stage)
eta_prediction = predict_eta(stage_model, signals)
update_order_eta(order_id, eta_prediction)
time.sleep(10) # wait a short interval
How to Handle Follow-up Questions
What if the data distribution changes with new restaurant partners?
Models should be retrained or fine-tuned as the platform grows. Periodic data refresh ensures coverage of new geographies, new restaurant behaviors, and updated travel patterns.
How do you measure the quality of the ETA predictions?
Time-based metrics measure the deviation from actual delivery time. One approach is Mean Absolute Error, comparing predicted minus actual times. Time-window accuracy can also be measured (e.g., percentage of deliveries finishing within X minutes of the forecast).
How do you handle unexpected surge or special cases like rain?
Real-time signals detect new conditions. Features such as weather status or region-level activity feed into the model. If there is a sudden spike in order volume, the system notes an elevated average waiting time or fewer available Delivery Executives.
How do you address potential overfitting for each leg’s model?
Regular cross-validation with hold-out sets ensures generalization. Feature importance checks prevent the model from over-relying on ephemeral signals. Online learning or incremental retraining can adapt to shifting distributions.
Why separate the ETA into four distinct models instead of a single monolithic model?
Features differ for each stage. For instance, a restaurant wait stage does not require Delivery Executive location. Splitting them out yields more specialized features and higher accuracy because each model optimizes for the signals relevant to that stage.
How is the final ETA updated to the user in near real-time?
A microservice architecture polls each model on triggers or short time intervals. The front-end refreshes once the new estimate arrives. This event-based approach gives minimal latency between updated signals and displayed ETA changes.
What if no Delivery Executive is available or repeated rejections occur?
The Ordered to Assignment model has signals for local staff shortage and rejections. It inflates the estimate accordingly. If continued rejections occur, the system can escalate or re-route to a different zone of Delivery Executives.
How could you extend this approach to other on-demand use cases?
Similar multi-leg breakdown can serve different verticals. Retail deliveries, logistics, or ride-hailing can adopt the framework by tailoring features (vehicle type, package size, distance, route constraints) and integrating real-time tracking signals.