
ML Case-study Interview Question: Threshold-Based Email Classification Using Eventually Consistent Domain Aggregation


Browse all the ML Case-Studies here.
Case-Study question
A large organization built an email classification system to identify whether an entered email address belongs to an internal user or an external collaborator. They wanted to trigger one of two invite mechanisms: a direct workspace invite for internal employees and a collaborative channel invite for external partners. They used a database table that keeps track of how many users within each team share a specific domain, grouped by role (such as admin, member, owner, or guest). They applied a threshold-based approach to decide whether a domain is internal or external. They also maintained an eventually-consistent data model that uses asynchronous jobs to update counts in real time. They have a “healer” component that corrects data drift if inconsistencies arise, such as when multiple overlapping operations increment or decrement counters out of sequence.
They ask you to design and explain the entire system in detail. How would you approach this classification pipeline, design the domain-aggregation data store, and handle real-time consistency so that the system returns accurate results at scale?
Detailed In-Depth Solution
Overview of the Classification Approach
This system classifies an email address as either internal or external. When a user initiates an invite by providing one or more email addresses, the classification engine groups these addresses by domain. It then checks which domains are recognized as belonging to the same team (internal) versus external. If a domain exceeds a certain fraction of the entire team, the system flags it as an internal domain.
Threshold-Based Decision
The primary decision rule states that a domain is considered internal if its total user count on the team is above a configurable threshold multiplied by the total team size.
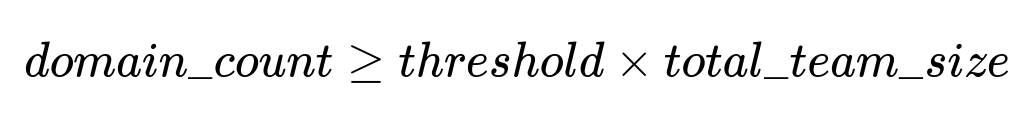
Where domain_count is how many users in the team share this domain, threshold is the fraction (for example 10%), and total_team_size is the count of all active users. When domain_count meets or exceeds threshold * total_team_size, the domain is marked as internal. Otherwise, it is external.
Data Storage and Sharding
They store these aggregates in a table keyed on team_id, domain, and role. For each team, there is a single shard that holds counts of how many users in each role have a specific domain. This makes lookups efficient since classification happens in the context of one team.
A typical table schema:
CREATE TABLE domains (
team_id bigint unsigned NOT NULL,
domain varchar NOT NULL,
count int NOT NULL DEFAULT '0',
date_update int unsigned NOT NULL,
role varchar NOT NULL,
PRIMARY KEY (team_id, domain, role)
);
Each row represents the total number of users matching a specific role and email domain within a particular team. The count column tracks how many people have that email domain. If it becomes negative, it signals data drift.
Real-Time Updates with Asynchronous Mutations
When a user joins, leaves, or changes roles, the system enqueues a background job that adjusts the table with simple relative additions or subtractions. These background workers update the count field via an atomic statement like:
UPDATE domains
SET count = count + 1
WHERE team_id = <team_id> AND domain = '<domain>' AND role = '<role>';
The same process handles decrements and role changes. By using row-level locks and local updates (count = count + 1 or count = count - 1), many simultaneous events remain mostly consistent, even if they occur out of order.
Eventually-Consistent Design
Due to the asynchronous nature of job queues, updates can arrive out of sequence. For a brief moment, the count values might show incorrect intermediate states. However, the system eventually converges because each update moves the value closer to a correct aggregate.
The Healer Component for Drift
If certain events fail or repeat, the system can drift away from actual counts. A healer job periodically scans the real users in a team and compares that to the stored count data. If it detects mismatches, it performs incremental arithmetic updates to bring the data in line. It does this in a way that still allows concurrent operations to proceed without losing new information. Negative counts trigger the healer immediately because that clearly indicates an error (nobody can have fewer than zero users).
Example Role Change
If a user changes from a member to an owner, the system performs:
Decrement of the member row for their domain
Increment of the owner row for their domain
If a user is deactivated at the same time, another decrement occurs on the member row. Because these events may not arrive in the exact order, a temporary mismatch might appear. Eventually, all increments and decrements are applied, and the healer corrects any residual offsets.
Example Code Snippet
Below is a simple pattern in Python that represents how the system might apply mutations for an event. It assumes a background job that processes user changes:
def process_role_change(db_connection, team_id, old_role, new_role, domain):
decrement_query = (
"UPDATE domains "
"SET count = count - 1 "
"WHERE team_id = %s AND domain = %s AND role = %s"
)
increment_query = (
"UPDATE domains "
"SET count = count + 1 "
"WHERE team_id = %s AND domain = %s AND role = %s"
)
with db_connection.cursor() as cursor:
cursor.execute(decrement_query, (team_id, domain, old_role))
cursor.execute(increment_query, (team_id, domain, new_role))
db_connection.commit()
This style of atomic updates ensures that each event modifies only the affected row, which helps the aggregator maintain near-real-time accuracy.
Putting It All Together
When a user types several email addresses, the system:
Extracts domains
Checks quick context (claimed domains, relationship to inviter) if available
Pulls the domain counts from the aggregated table for the relevant team
Compares them against
total_team_sizeApplies a threshold rule
Recommends the invite mechanism
This yields suggestions: if the email belongs to an internal domain, invite them directly to the workspace; otherwise, send them a collaborative channel invite. The system is efficient since each domain triggers just one database lookup, and updates to the table are done in an asynchronous, eventually-consistent manner.
What if Different Teams Share the Same Domains?
Teams can claim the same domains. The system stores the counts in separate rows per team_id, so a domain might be internal for one team but external for another. This model ensures each team sees accurate classification even if they share domain names with another team.
How Does the Threshold Handle Rare or Edge Cases?
When new domains appear, they may have low user counts. The threshold-based approach quickly marks them external, unless they grow beyond the threshold. If false negatives or positives occur in corner cases, the system can rely on additional logic (such as user-specific overrides or domain claiming in team settings) to override or reclassify certain domains.
How Does the Healer Avoid Overwriting New Data During Large Discrepancies?
The healer scans all users in a team, constructing an in-memory tally of (domain, role) counts. It compares that tally with the database table. It calculates the difference and issues the arithmetic increments or decrements. While it is running, new updates might arrive, but the arithmetic approach (count = count +/- N) only shifts the existing value by the necessary margin. This keeps new updates intact, because it does not overwrite absolute values.
What If the System Needs to Scale Further?
Sharding is done by team_id, so each team's data is on one shard. For extremely large teams, further partitioning might be necessary, but many real-world workloads fit into a single shard for each team. Additionally, caching and read replicas can lighten the primary database load.
Why Not Use a Periodic Full Backfill Instead?
A daily backfill for millions of users is expensive and would produce stale information between runs. The eventual-consistency approach delivers near-real-time results, since each event quickly updates the counts. The healer corrects any drifting errors without needing a full backfill for each domain.
How Would You Extend This to Deep Learning?
After reaching scale and stability, a more advanced system might incorporate a learned representation of domains, user behaviors, or organization relationships. Deep learning could help identify unknown domains, suspicious patterns, or typical external partners. This could be done alongside the threshold-based approach for an even smarter classification engine.
Why Use an Eventually-Consistent Model Instead of a Strictly Consistent One?
Strict consistency at large scale can be costly in terms of real-time computations. By allowing short-lived inconsistencies, the system finishes updates faster and handles spikes in events more gracefully. The minimal overhead ensures every new user or role change triggers only a simple increment or decrement, while the healer corrects any mismatches in the background.
How Would You Test This System?
Testing covers:
Mutation correctness: ensuring increments and decrements match user states
Race conditions: verifying simultaneous events do not crash or corrupt data
Negative counts: forcing scenarios that trigger the healer and checking final correctness
Performance: measuring how many classification checks per second are possible when thousands of users join or leave simultaneously
A robust test suite verifies normal flows, stress conditions, and partial failures.