
ML Case-study Interview Question: Designing a Scalable Machine Learning Pipeline for Data-Driven Stock Selection.


Browse all the ML Case-Studies here.
Case-Study question
You are hired as a Senior Data Scientist at a financial technology company. They aim to improve stock selection using a Machine Learning-based engine. The existing system ingests daily market data, fundamental data, and text-based corporate disclosures. They want accurate weekly stock picks that beat market benchmarks. You must design a full data-to-deployment plan with details on data ingestion, feature engineering, model training, model explanations, and system monitoring. You must ensure scalability and resilience in volatile market regimes. How would you approach this project?
Detailed Solution
Start with a systematic pipeline that moves from raw data to final predictions. Create separate layers for data ingestion, feature engineering, modeling, and monitoring.
Data Ingestion and Storage
Ingest data from multiple sources, such as price-volume, options chains, fundamentals, macro releases, and text-based filings. Cleanse the feeds by detecting anomalies like suspicious price jumps that might be caused by corporate actions or data errors. Store everything in a column-oriented system to facilitate bulk transformations. Use daily scheduling to pull new data, then run verifications before pushing data into a store. Archive the ingested data in a compressed format for quick restoration.
Feature Engineering
Generate features that capture price trends, volume changes, technical indicators, text-based sentiment, and macroeconomic signals. Compare each stock’s characteristics to sector or index cohorts. Add rolling statistics such as moving averages, skew, and percentiles. Encode fundamental data (like revenue or earnings) to produce ratios such as price-to-sales. Create feedback features that track the gap between past predictions and realized returns. Keep the design flexible so you can add new features without breaking older ones.
Modeling Approach
Build a supervised learning model that predicts forward risk-adjusted returns. Structure this as a classification approach where the target is whether a stock outperforms the market with acceptable downside risk. Train the model daily but only form stock picks weekly. Use a well-optimized library like XGBoost or a deep learning alternative if data size justifies it. Maintain a separate market regime model to track changes in volatility and economic cycles. Feed that regime signal into the main forecasting model.
Core Mathematical Expression
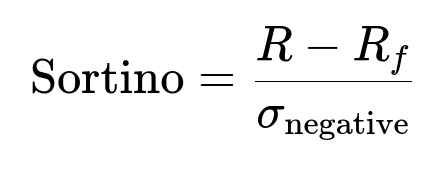
Here, R is the asset’s realized return, R_f is the risk-free rate, and sigma_negative is the standard deviation of negative returns only. Use this ratio inside your labeling or objective logic for classification, ensuring the model focuses on downside risk.
Model Explanations
Generate explanations so end-users know why the engine picks certain stocks. Employ SHAP-based methods to highlight important features each day. Convert those feature importances into short textual summaries. Summaries must reference numeric signals (such as volatility changes or strong fundamentals) that boosted or reduced each pick’s probability of outperformance.
Execution and Deployment
Orchestrate the pipeline with a job scheduler or DAG manager so each data-to-prediction run is reliable. Use powerful but cost-controlled cloud instances for heavy tasks like natural language processing on earnings calls. Parallelize feature calculations to reduce runtime. Cache intermediate outputs to skip repeated transformations.
Monitoring and Maintenance
Track daily run logs, watch for data feed failures or suspicious feature drifts, and keep separate dashboards for real-time performance. Compare the model’s current picks vs. realized returns to catch regime changes early. Maintain separate archival backups for data, models, and generated features. Retrain daily but only present picks at the end of each week, which reduces frequent portfolio turnover.
Example Python Snippet
import xgboost as xgb
import pandas as pd
import numpy as np
# Suppose df has columns [features...] + [target]
X = df.drop('target', axis=1)
y = df['target']
model = xgb.XGBClassifier(
max_depth=8,
n_estimators=300,
learning_rate=0.05
)
model.fit(X, y)
# Predict probabilities of outperformance
pred_probs = model.predict_proba(X)[:, 1]
# Sort stocks by predicted probability
df['score'] = pred_probs
df_sorted = df.sort_values('score', ascending=False)
final_picks = df_sorted.head(20)
print(final_picks)
This snippet trains a gradient-boosted model and selects top stocks by predicted probability of outperforming.
Follow-Up Questions
How would you handle incoming corporate actions that distort prices or fundamentals?
Track reference data to identify splits, ticker changes, or M&A deals. Validate large price jumps by cross-checking a corporate actions feed. If confirmed, recast historical prices and shares outstanding so time series remain smooth. Test each transformation’s effect on your features, especially rolling calculations like volatility or momentum. Maintain date-specific metadata to ensure old data aligns with the firm’s past state.
How do you handle regime shifts in the market?
Use a separate clustering or classification model that ingests index-level and macro signals. Output a numeric regime identifier each day. Feed that as an input feature to the main forecasting model. Regimes might be bullish expansions, bearish contractions, or more nuanced states. Retrain daily so newly emerged regimes are incorporated. Evaluate forward returns in each regime. Switch weighting or thresholds when the regime shifts.
Why do you retrain the model daily, even if picks are weekly?
Regimes can change midweek. Daily retraining updates feature distributions and reestimates parameters to reflect new conditions. Only publish picks weekly to reduce trading friction. This hybrid approach balances granularity (daily retraining) with usability (weekly picks). The daily model updates keep you prepared for a fast-moving market.
How do you ensure model performance remains stable when new features are added?
Run offline experiments comparing old vs. new feature sets using backtests and cross-validation. Track improvements in classification metrics and out-of-sample returns. Merge the new features only after verifying their stability. Keep modular feature engineering so you can disable any feature group if it adds noise or slows down runs.
What if the pipeline runtime expands and starts missing critical market windows?
Measure runtime carefully. Profile each stage to pinpoint bottlenecks (e.g. data ingestion, transformations, model inference). Swap slower libraries with faster ones such as Polars instead of Pandas. Integrate multiprocessing or vectorized operations. Migrate to more powerful instances or adopt distributed solutions if needed. Always keep pipeline speed below critical market deadlines for timely updates.