
ML Case-study Interview Question: Detecting Implicit Design Groups with Vision Transformers and Polygon Overlap


Case-Study question
A large online design platform wants to automatically detect and preserve logical groupings of shapes and text (tables, diagrams, charts) that users build manually. Some users use ready-made design elements, while others create their own configurations (like a table drawn with lines). The company wants a system that treats these configurations as a single unit during layout transformations or design conversions. How would you build this system to recognize such implicit groups in user designs, maintain low latency, and keep detection accuracy high? Propose an end-to-end approach: from input data to detection model, to the final user experience. Outline potential trade-offs and optimization steps.
Detailed Solution
Overview
The system needs to detect coherent, meaningful units (like implicit tables or diagrams) in a design where users may create these units through multiple basic elements. The design platform represents each page as a collection of positioned elements, but also as a raster image for computer vision tasks. Recognizing objects in the raster and mapping them back to the element space is the core challenge.
Design Rasterization
The system rasterizes user designs into images. Each design can be large (such as 1920x1080), so downsampling is crucial to reduce file size and network latency. The raster is sent to a detection model. The model processes the image, identifies bounding boxes for tables, diagrams, or charts, and then returns these bounding boxes.
Object Detection Model
A Vision Transformer model, pre-trained and fine-tuned on annotated data, detects the bounding boxes of each implicit group. This model has a moderate parameter size (around 30M), which helps keep inference time manageable (about 70ms on typical hardware).
Bounding Box Decoding
The system must map each detected bounding box in the raster back to the original design elements. Using naive element bounding boxes might cause mismatches because elements often have extra whitespace. A more precise method uses polygons that wrap only the non-transparent pixels of each element. The system checks if these polygons overlap significantly with the detected bounding box. If they do, the element is included in that group.
Core Formula for Bounding-Box Overlap
When deciding if an element polygon or bounding box belongs to the detected group, the system computes the overlap ratio between the detected region and the element polygon or bounding box.
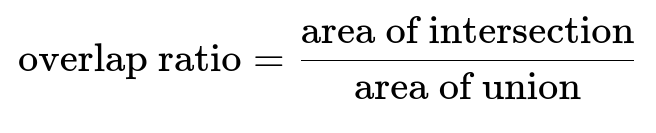
Here:
area of intersection is the region that both the detected bounding box (or polygon) and the element polygon share.
area of union is the combined region covered by both.
A threshold (for example, 0.7) is used. If the overlap ratio is above the threshold, the element is assigned to the group.
Compression and Latency
Uploading raster images can cause high network usage. Reducing the raster to JPEG with moderate quality and resizing to one-quarter scale (or smaller) helps control file size. The model is trained on similarly compressed images so it is robust to artifacts. The bounding boxes from the model output are then upscaled to match the original design's dimensions.
Data Augmentation
Training data is enriched with:
Rotation, cropping, zooming, flipping.
Template-fusion, where pre-labeled implicit groups are placed in random templates to vary the background, context, and arrangement.
These augmentations increase model robustness to diverse compositions.
Implementation Example (Python Pseudocode)
import torch
import torchvision.transforms as T
from PIL import Image
# Load trained model (Vision Transformer)
model = ...
model.eval()
def detect_implicit_groups(image, element_polygons):
# Preprocess image
transform = T.Compose([
T.Resize((desired_h, desired_w)),
T.ToTensor()
])
input_tensor = transform(image).unsqueeze(0)
with torch.no_grad():
# Model predicts bounding boxes
detections = model(input_tensor)
# For each detection, decode the bounding box
results = []
for det in detections:
bbox = det["bbox"] # [x1, y1, x2, y2] in resized coords
# Upscale to original dimensions
scaled_bbox = upscale_bbox(bbox, original_h, original_w, desired_h, desired_w)
# Check overlap with element polygons
included_elements = []
for e_poly in element_polygons:
overlap = compute_overlap_ratio(scaled_bbox, e_poly)
if overlap > 0.7:
included_elements.append(e_poly)
results.append({"bbox": scaled_bbox, "elements": included_elements})
return results
Explanations:
detect_implicit_groupsfunction rasterizes the design, feeds the image to the model, then translates each detection back to the original coordinate system.compute_overlap_ratiocalculates the intersection-over-union area between the bounding box and the element polygon.resultsprovide the final groups.
Final User Experience
Users transform or resize designs, and these groups remain intact. The system ensures a table or diagram is moved or resized as a cohesive unit.
How would you handle dense designs where whitespace cues are insufficient?
Dense designs with minimal whitespace are best handled by computer vision because it interprets the visual composition rather than spacing rules alone. Reliance on spacing thresholds would merge elements incorrectly or separate logically grouped elements. The vision approach learns from actual appearances of tables and diagrams, so it remains effective on designs lacking whitespace-based structure.
How do you ensure the detection model remains lightweight but still accurate?
Choosing a moderate-sized Vision Transformer with around 30M parameters strikes a balance. Reducing the input image size keeps memory usage manageable. Using augmentations like template-fusion and adjusting compression quality during training ensures the model adapts to real-world scenarios. This allows the system to run quickly while maintaining acceptable accuracy.
What about false positives or partial coverage in bounding boxes?
Object detection with axis-aligned bounding boxes can sometimes include extra elements that are visually in the bounding box but semantically separate. The element-polygon overlap step helps filter out those false inclusions by only including elements that actually overlap the detected region. Some false positives remain possible. Refining the model with instance segmentation could reduce this, but that often increases model size and latency.
How would you test and validate this approach?
Collect a representative dataset of real user designs and label all implicit groups. Include designs with dense layouts, varied element types, and random decorations. Split this dataset into training, validation, and test sets. Measure:
Intersection-over-Union between model detections and ground truth groups.
Recall and precision for each type (table, diagram, chart).
Latency from client side image upload to detection response. Compare results against baseline approaches (like whitespace-based grouping). Verify that user experience remains smooth on slower networks.
How do you handle scalability if design usage grows significantly?
A well-optimized model can still struggle under high traffic. Strategies include:
GPU or specialized accelerators for inference.
Micro-batching to process multiple images at once if feasible.
Model quantization or distillation to reduce inference load.
Potential caching of detection results for repeated design queries.
How would you address security and privacy?
Rasterizing user designs on the client means sensitive graphics are transmitted. For security:
Use secure HTTPS connections.
Encrypt requests if needed.
Only send minimal compressed images.
Adhere to legal and privacy requirements around storing user-generated content. Ensure the detection process only stores short-lived data unless it's essential.
Conclusion
The key steps involve rasterizing designs, detecting implicit groups with a Vision Transformer, refining with polygon-based overlap to decode detected boxes into elements, and carefully balancing compression against model performance. This creates a fast, reliable system that keeps logically grouped elements intact for any layout transformation.