
ML Case-study Interview Question: Optimizing App Store Ad Bids with Contextual Bandits and Survival Analysis


Case-Study question
You are a Senior Data Scientist at a large product-based organization that advertises in a major app store platform. The marketing team manages tens of thousands of keywords with daily bid updates to drive user acquisition at an optimal cost. The platform uses a second-price auction model and charges on a per-tap basis. The company wants an automated bidding system that:
Maximizes return (for example, number of new active users or some internal metric)
Respects a weekly or monthly budget constraint
Adapts to competitor bid changes and explores potentially lucrative keywords
Design a strategy to handle this. Present your end-to-end solution. Provide details on data ingestion, modeling approaches, exploration-exploitation tradeoffs, and how you would maintain or improve the system over time.
Detailed Solution
Bid Optimization Context
The app store platform charges for taps rather than impressions. This means a bid only generates cost if someone taps on the ad. The platform uses a second-price auction, so the winning advertiser pays the second-highest bid plus one cent. This encourages bidding close to the true value of the impression. A system must handle a large volume of keywords, each with unique performance.
Traditional Rule-Based Limitations
Initial rule-based systems, often SQL-driven, adjust bids up or down based on simplistic signals (for example, up if return meets a threshold). This quickly reduces cost for poorly performing keywords. It fails to discover potential gains when a competitor outbids you. There is no insight into outbid impressions or how high a bid must go to recapture them. This leads to limited exploration.
Contextual Multi-Armed Bandit Approach
A contextual multi-armed bandit framework addresses exploration versus exploitation. Keywords can be seen as arms in a bandit. Each arm has different performance characteristics. The system learns which arms (keywords) to favor (exploit) while occasionally trying new or uncertain arms (explore). Daily data feedback refines these strategies.
Bid-to-Spend Modeling
Competitors’ exact bids are unknown. Observed impressions, taps, and spend reveal partial clues about where your bid stands relative to others. Modeling this requires survival analysis methods that handle left and right censoring. When you lose an auction, it implies your bid is lower than the second-highest competitor, but you do not know by how much. When you win but see no taps, there is no spend, yet you still outbid others. Recency weighting ensures the system adapts quickly to changing competitor bids.
Spend-to-Return Modeling
Each keyword’s spend-to-return relationship often follows a curve with diminishing returns. Parametric curves like a Hill function can capture this behavior.
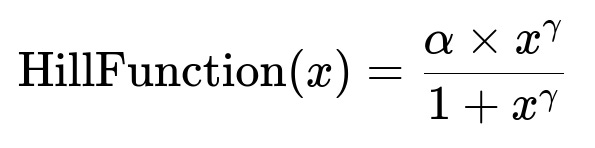
Here x is the spend amount. alpha and gamma shape the curve. alpha is related to maximum possible return, gamma controls how sharply returns increase then saturate. Adding synthetic data from a global model helps when a keyword has little or no historical spend variety.
Solving the Optimization
A solver finds how much to spend on each keyword to maximize the sum of returns, subject to a budget constraint. One can formulate it as:
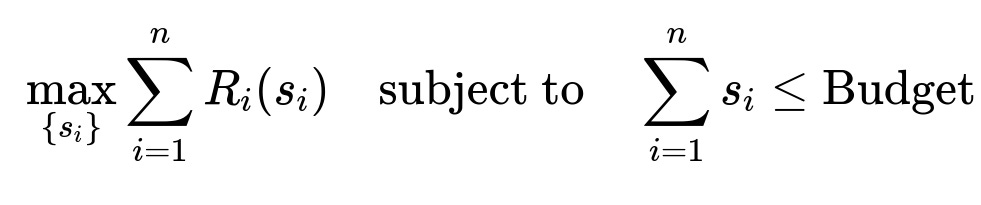
Here s_i is the spend on keyword i, R_i(s_i) is the return function for keyword i, and Budget is the total daily (or weekly) limit. A gradient-based solver (for example, L-BFGS) quickly finds the solution if R_i(s_i) is differentiable. Soft constraints allow small over- or under-shoot of the budget, which still converges over daily iterations.
Exploration Mechanism
Purely deterministic bids can lock into a suboptimal strategy. Thompson sampling addresses this by sampling a plausible spend-to-return curve from a distribution for each keyword. A keyword lacking data gets a broader distribution, prompting more exploration. A high-confidence keyword sees narrower distributions around known performance, focusing on exploitation.
Operational Details
Implementation involves:
Nightly or daily data pull on impressions, taps, and spend per keyword
Survival analysis to refine the bid-to-spend estimates
Hill function fitting (plus synthetic data points) to model spend-to-return
Numerical solver to allocate daily budget across all keywords
Daily or frequent bid updates back to the ad platform
Monitoring for changes in competitor behavior or campaign strategy
Maintenance and Improvements
System flexibility allows each piece (bid model, spend-return model, solver) to be improved independently. A user interface showing predicted performance or offering override possibilities builds trust with marketing teams.
Follow-up Questions
How do you handle the cold start problem for new keywords or keywords with few data points?
Use a global model trained on all other keywords to generate synthetic data for that new keyword. Blend these synthetic points with the small real dataset to shape an initial spend-to-return curve. This approach allows the optimizer to explore a new keyword at rational spend levels. Over time, real data from the new keyword overrides or refines these priors.
Why not just rely on the rule-based system with domain knowledge overrides?
Such a system is overly dependent on manual insight. It fails to recover from competitor bid shifts or other market changes without constant re-tuning by humans. A model-based bandit approach leverages probabilistic estimates to explore automatically. It also scales better across thousands of keywords.
How do you ensure the model updates do not overshoot or undershoot the budget?
Soft constraints in the objective function permit small deviations. The model sees the effect of these deviations the next day. If daily spend is below budget for multiple days, the system discovers missed opportunities and increases bids. If spend surges above budget, the system reduces bids in subsequent updates. This feedback loop converges smoothly, whereas a hard constraint can cause solver inefficiencies or oscillations.
What if a specific event or holiday suddenly changes user behavior?
Incorporate temporal or event-based features into the global model. Weigh more recent data more strongly to respond quickly. If an event is large enough, historical data alone might not suffice. Scheduling an explicit budget or separate campaign for the event can give the model data that reflects the new dynamics more reliably.
How do you interpret survival analysis in this context?
You approximate the distribution of the second-highest competitor bids by seeing whether you won impressions (implying your bid was higher) or missed them (implying your bid was lower). Each day’s aggregated taps and spend get translated into intervals of possible competitor bid ranges. Turnbull’s EM algorithm fits this interval-censored dataset. This yields a function that estimates the probability of winning at various bid levels, crucial for linking bid size to potential spend.
How do you ensure you maintain transparency and stakeholder trust?
Provide a dashboard showing:
Projected bids versus actual bids
Predicted returns versus actual returns
Key metrics (cost per tap, new users) at daily or weekly intervals Offer marketing teams the ability to temporarily override or manually set certain keyword bids. Document each pipeline step (bid-to-spend, spend-to-return, budget solver). This visibility reduces confusion and builds confidence in data-driven decisions.
How do you reduce training time for such a system when scaling to thousands of keywords?
Train each keyword’s bid-to-spend model in parallel. Cache or memoize partial results. Provide the solver with precomputed gradients to avoid repeated computations. Simplify the constraints by using soft constraints, letting the solver converge faster. These techniques cut overhead significantly, especially on a modern cloud-based infrastructure that supports distributed training tasks.
How do you measure success or failure when you roll out this system?
Compare key performance indicators like cost per new active user, daily or weekly spend tracking error, and total return on ad spend before and after rollout. Validate if daily spend is close to the budget target. Validate if the total conversions or returns meet or exceed previous benchmarks. Examine how quickly bids adapt to competitor changes. Watch for anomalies in day-of-week or seasonal shifts to confirm the system’s responsiveness.
(End of solution)