
ML Case-study Interview Question: Improving Streaming Video Quality and Efficiency with Deep Learning Downscaling


Browse all the ML Case-Studies here.
Case-Study question
A leading streaming provider wants to improve video quality for users across all devices and network conditions. They have a standard encoding pipeline that downsamples high-resolution videos to multiple lower resolutions before encoding. They tried a neural network-based approach to replace the traditional downscaling filter (like Lanczos) with a learned deep downscaler. They observed that this model gave sharper details at the same bitrate and improved objective metrics such as VMAF and Bjøntegaard-Delta (BD) rate. They also integrated this neural network into their large-scale cloud infrastructure by running it inside a serverless layer that performs encoding jobs on CPU or GPU environments. You are asked to outline how to design, train, and deploy such a model, validate its performance both objectively and through human subjective tests, and ensure it runs efficiently at scale. Provide your complete solution approach.
Detailed solution
Overview of the deep downscaling model
The system replaces the conventional downscaling filter with a neural network architecture that has two blocks: a preprocessing block and a resizing block. The preprocessing block handles visual artifacts before the resizing. The resizing block then downsamples the frames to the target resolution. A conventional video codec (for example, AV1 or VP9) encodes these downscaled frames afterward.
The training process involves minimizing the mean squared error between a high-quality reference and the upscaled version of the network’s downscaled frames. Compression is not explicitly modeled during training. The trained network can be used as a drop-in replacement in production, without changes on the playback devices.
Objective metrics and BD rate calculation
Engineers assessed quality gains through metrics like VMAF and Bjøntegaard-Delta (BD) rate. BD rate quantifies bitrate savings or quality improvements over a range of rate-distortion points. One commonly used integral form for BD rate is shown below.
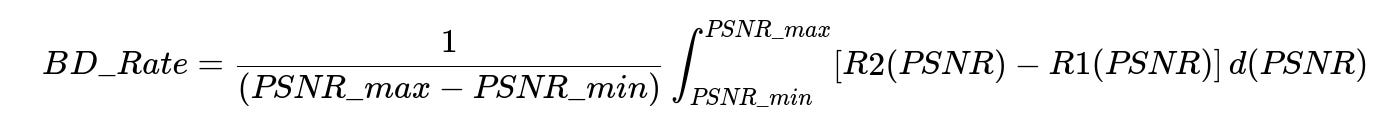
Here, PSNR_min and PSNR_max are the minimum and maximum peak signal-to-noise ratio values over which measurements are taken. R1(PSNR) and R2(PSNR) are rate functions as a function of PSNR for the two methods being compared. A negative BD rate typically indicates a reduction in bitrate for the same quality or an improvement in quality at the same bitrate.
Subjective evaluation
They performed preference-based tests where participants compared the output of the neural network approach against the conventional Lanczos-based downscaling, at the same bitrate. Test subjects favored the neural network version in most cases, citing sharper and more detailed images. This subjective study confirmed objective improvements.
Implementation details
They integrated the deep downscaler into an FFmpeg-based filter that combines format conversions and neural network inference in one step. To keep computational costs low:
The model has few layers.
Only the luma channel uses the neural network, with chroma scaled by a traditional filter.
CPU inference uses optimized libraries (for example, oneDnn).
GPU inference is also supported, depending on available hardware.
Large-scale deployment with a cloud platform
They used an encoding microservice architecture. Each microservice runs within a serverless layer (Stratum) that executes the deep downscaler prior to encoding. This design is flexible for different workflows like complexity analysis or final video encoding. The system seamlessly scales with multi-CPU or GPU environments.
Future possibilities
They intend to expand neural network usage to other parts of the video preprocessing pipeline, like denoising. They also consider combining deep learning techniques with next-generation codecs for further compression efficiency. Continuous research refines the model architecture, training data, and real-time inference optimizations.
How to handle potential follow-up questions
How would you refine the neural network architecture if it introduced artifacts?
Train the model with a perceptual loss function or a combination of mean squared error and perceptual metrics (for example, a feature-based distance computed on a pretrained vision network). Adjust the network’s capacity and apply light regularization or smaller kernel sizes if artifacts appear. Conduct new subjective tests to confirm improvements.
How do you control overfitting when training the model on varied content?
Collect a diverse dataset with many genres, lighting conditions, and motion patterns. Apply data augmentation strategies such as random cropping, random noise injection, and color jitter. Monitor performance on a held-out validation set that reflects typical production content to avoid overfitting.
How do you ensure consistent performance across multiple device types?
Profile and stress-test both CPU and GPU inference paths with real user workloads. Use hardware-specific optimizations in libraries like oneDnn or CUDA-based frameworks. Set up monitoring for inference time and memory usage to catch regressions quickly.
How would you extend this approach to next-generation codecs?
Train the same downscaler with an upscaling operator that matches the final playback pipeline for that codec. Run experiments across multiple bitrates to confirm BD rate benefits. Add more advanced layers or domain-specific blocks if new codecs allow advanced prediction or transformation features.
How do you validate that the model does not cause playback failures at scale?
Deploy a gradual rollout across a small percentage of the encoding jobs. Compare error logs, streaming reliability metrics (for example, startup time, rebuffer rate), and user sessions. Expand the rollout incrementally while ensuring stable performance. A/B test major changes to check for unexpected issues.
How do you handle real-time or live content encoding with this approach?
Use a lighter network with smaller input sizes or fewer channels. Minimize latency by batching frames or employing a custom low-latency inference pipeline on GPUs. Scale hardware resources horizontally and employ concurrency. Ensure consistent end-to-end latency fits within live streaming budgets.
How do you see the performance evolving over time with codebase changes?
Use automated performance regression checks in continuous integration pipelines. Run a fixed set of standard sequences through the encoder with the deep downscaler, compare key metrics (latency, memory usage, BD rate improvements) against a known baseline, and fail the build if metrics degrade significantly.