
ML Case-study Interview Question: Scalable Food Search Relevance Optimization with nDCG and ML Re-ranking.


Browse all the ML Case-Studies here.
Case-Study question
A large food ordering platform faces a challenge to improve the relevance of search results. There are more than a million daily orders, with close to half a million merchants. The company notices that users often abandon orders when relevant items are buried lower in the search results. The team hypothesizes that higher search relevance leads to better conversion, and wants to optimize relevance using a metric called nDCG. The platform tracks user clicks and orders to quantify relevance and uses these signals to train a re-ranking machine learning model. How would you design a system to measure nDCG at scale, integrate it with a search engine, and leverage the data to boost results quality?
Detailed Solution
Core Idea
The system must surface relevant restaurants or food items near the top of the search results. Relevance can be quantified by user actions like clicks and orders. The plan is to log interactions, compute nDCG for different versions of the search engine, and train personalization models on signals derived from historical user behavior.
Relevance Measurement with nDCG
Relevance levels can be 0 if the user did not interact, 1 if the user clicked, and 2 if the user placed an order. The position of the result in the list is penalized using a logarithmic discount factor. The main formula for Discounted Cumulative Gain (DCG) at position p is:
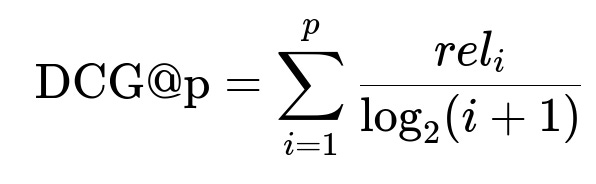
rel_i is the relevance score of the i-th result. The Ideal Discounted Cumulative Gain (IDCG) sorts results by descending relevance:
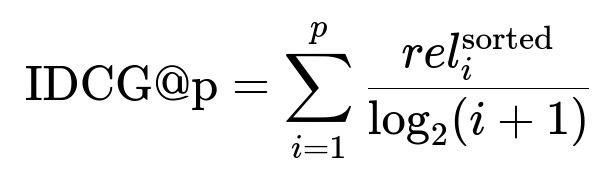
nDCG is the ratio of DCG to IDCG:
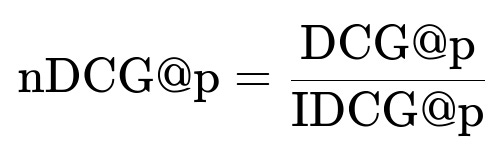
This value ranges from 0 to 1.
Logging and Data Pipeline
A logging mechanism must capture which search results the user saw, the position of each result, and whether the user clicked or ordered. This data is aggregated daily or hourly. A data pipeline processes logs, merges them with known merchant attributes, and calculates nDCG for each search session. The pipeline then computes overall nDCG averages, which serve as a leading indicator for performance.
Ranking Model
A search layer first retrieves results based on matching techniques (keyword, category, etc.). A ranking model reorders them. This model uses features like user cuisine preferences, merchant popularity, time of day, seasonality, and weather. A machine learning approach (e.g., gradient boosted decision trees) is trained to produce a relevance score for each result. During training, relevance labels come from user actions logged in previous sessions.
Example Code Snippet for Computing nDCG
import math
def dcg(relevances):
score = 0.0
for i, rel in enumerate(relevances, start=1):
score += rel / math.log2(i + 1)
return score
def ndcg(relevances):
ideal = sorted(relevances, reverse=True)
return dcg(relevances) / dcg(ideal)
# Example usage:
user_relevances = [2, 1, 0, 2, 1] # hypothetical data for 5 results
score_ndcg = ndcg(user_relevances)
print("nDCG score:", score_ndcg)
Conversion and Satisfaction
Relevance boosts the chance a user finds the desired item. This drives conversion. Higher conversion is hypothesized to correlate with higher user satisfaction. Tracking conversion complements nDCG as a metric, since conversion indicates actual ordering, but nDCG provides deeper insight into how well the top results match user intent.
Scaling the Approach
All computations must handle large volumes of data. A distributed architecture can compute partial nDCG aggregates and merge them. A streaming solution can handle near-real-time signals for rapid feedback on search adjustments. Periodically retraining the model ensures that fresh data patterns are reflected in the results.
How would you handle dynamic user preferences changing over time?
Users might shift preferences every few weeks. A rolling training window can ensure the ranking model learns these shifts. The pipeline must be scheduled to retrain on recent behavior, discarding stale logs past a cutoff. Hyperparameter tuning can be repeated at intervals to adapt the model quickly. Real-time scoring can incorporate session-based signals like recent clicks, if feasible, to handle short-term changes.
How do you address new merchants with no historical data?
The model might rely on popularity or user ratings, but new merchants lack such history. A fallback strategy can be introduced. The system can assign them a modest default relevance to ensure exposure. Over time, actual user interactions update the scores. A cold-start approach might use collaborative filtering or content-based recommendations, inferring possible matches based on cuisine type or geographical area. The key is to avoid penalizing new merchants too strongly, ensuring they get sufficient visibility.
How do you ensure the search engine does not ignore diversity in results?
The algorithm could re-rank by balancing relevance with diversity constraints. A post-processing step can ensure that the final set of results includes varied cuisines or merchant types. One approach is to penalize items with overly similar features, thereby promoting variety. Another approach is to enforce category-based diversity, ensuring users see a range of options if the query is broad. This helps capture users who have not formed a specific intent.
How do you manage online experiments to validate improvements?
A/B tests or multi-armed bandit frameworks can compare multiple ranking strategies. A fraction of traffic sees a new model or parameter tweak. The rest uses the baseline. Metrics like nDCG, conversion, and dwell time on merchant pages are tracked. Statistical tests check if improvements are significant. If performance is consistently better, the new approach is rolled out to all users.
How do you prevent the system from over-optimizing for clicks at the expense of orders?
Clicks alone might inflate perceived relevance. Incorporating order data is crucial. The labeling scheme can weight orders higher than clicks. The cost function for the ranking model can penalize high click-through with low order rates. Periodic manual audits and user feedback can further guard against superficial clicks. Logs of time spent on the menu or cart conversions also refine the definition of relevance.
How would you handle re-ranking latency concerns?
A fast re-ranking approach is needed. Precomputed embeddings or approximate nearest neighbor methods reduce candidate sets quickly. A final model re-rank step should be optimized with lightweight features. Caching common queries is a standard tactic. Parallelization across multiple servers or streaming inference with GPUs can also reduce latency. Monitoring and profiling help ensure sub-second response times.
How do you measure the model’s stability vs. novelty for recurring users?
The system must avoid excessive volatility in results. Drastic changes can confuse returning users. A rolling nDCG measure for returning users indicates how consistent the ranking remains for the same queries. The platform can track user dwell times across repeated sessions. Model constraints or smoothing factors can reduce swings. An exploration-exploitation trade-off is essential, introducing new items occasionally while keeping stable favorites near the top.
How do you handle partial relevance signals when only limited user interaction is tracked?
If many users do not click or order but only skim results, inference can be aided by dwell times or scroll events. Another technique is to track impression-level data and apply implicit feedback. The model can treat zero-interaction as mild negative feedback. The pipeline must distinguish user abandonment (unhappy) from user quick scanning (still uncertain). Analyzing session patterns can mitigate noise from missing or ambiguous signals.
How would you confirm nDCG remains the correct metric?
Periodically compare nDCG against actual conversion and user satisfaction surveys. If they move consistently in the same direction, nDCG is a good leading indicator. If they diverge, the model or the metric might need refinement. Large-scale user studies or controlled experiments can further validate nDCG’s alignment with real-world success metrics. Sometimes adjustments in the relevance scale or weighting might be necessary if user behavior changes or the platform’s priorities shift.