
ML Case-study Interview Question: Accurate Food Delivery Time Breakdown Using MIMO Deep Learning and Entity Embeddings.


Browse all the ML Case-Studies here.
Case-Study question
A platform running a large-scale food delivery business wants to improve the accuracy of its delivery time predictions displayed to customers at the checkout page. The delivery time is influenced by restaurant preparation, availability of delivery executives, and expected travel durations. The platform faces severe business impact if deliveries miss the promised timeline or if the promise is too conservative and discourages orders. The task is to propose a machine learning solution that outputs a granular breakdown of time forecasts for each leg of the delivery journey, then aggregates these to produce a final estimate. Focus on handling high-cardinality restaurant and location variables, real-time system constraints (time-series effects, recency, rush hours), and the interplay between assignment and travel time predictions. Propose an approach that integrates historical data, near real-time updates, and advanced modeling. Show how your method would measure accuracy and ensure minimal prediction error for diverse cohorts. Outline the data pipelines, modeling strategy, hyperparameter choices, evaluation metrics, and how you would handle sparse data segments.
Proposed Solution
A multi-leg approach is required. Restaurant preparation time, assignment time, first mile (travel to the restaurant), wait time, and last mile (travel to the customer) must be modeled carefully. A multi-input, multi-output neural network (MIMO) handles these jointly. Entity embeddings represent high-cardinality features like restaurant IDs and geohash locations. The aggregated output forms the final predicted delivery time. Historical data and live signals power the model inputs. Recency-based moving averages capture spikes during peak hours. Incorporating a dedicated sub-network for each of the target outputs helps capture the interplay between legs. Sharing hidden layers across these sub-networks enforces better generalization by letting the model learn cross-leg relationships.
Model Architecture
A MIMO deep learning network ingests categorical (restaurants, location geohashes) and numerical (distance, time windows, near real-time system load) features. The categorical variables map to entity embeddings. These embeddings are learned simultaneously with the rest of the network, maintaining a manageable dimensionality for thousands of restaurants and locations. The hidden layers process these embedded vectors along with numerical signals, then branch out to multiple output heads: one for assignment time, one for first mile, one for wait time, and one for last mile. A separate output node aggregates total order-to-reached time. The network is trained with a combined loss that considers each leg’s error and the total order-to-reached error.
Data and Feature Engineering
Historical logs of travel speeds, assignment patterns, and restaurant preparation durations feed into the model as moving averages with time-series context. Current load at the restaurant (number of active orders) and system-level stress (active delivery executives vs active orders) provide near real-time signals for fine-tuning the assignment and travel forecasts. The food preparation time for the given item mix (number of items, item type) is passed as an input from a separate module that estimates dish-level prep durations. Handling sparse data segments for new restaurants or rarely ordered items involves fallback to city or zone-level averages, with the embeddings learning broad patterns.
Key Mathematical Formulas
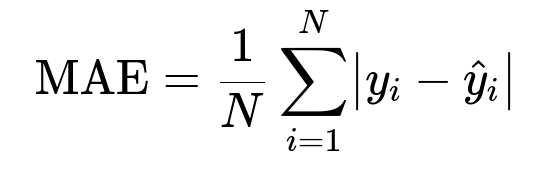
MAE measures average absolute deviation. y_i is the observed delivery time for an order, and hat{y}_i is the predicted delivery time for that order. N is the total number of orders in a test set. Lower MAE indicates better overall accuracy.
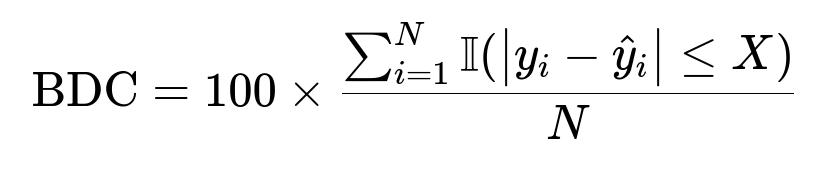
BDC is the bi-directional compliance. It shows the percentage of predictions within a chosen threshold +/- X. A higher BDC reflects better reliability.
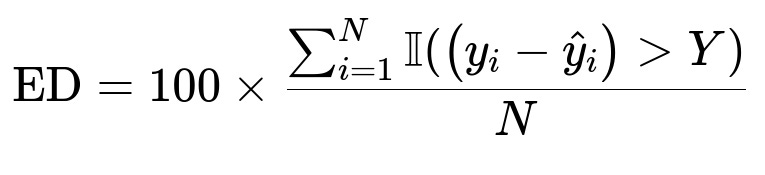
ED measures egregious delays. y_i - hat{y}_i is the delay beyond the predicted timeline. Y is a chosen threshold for severe lateness. Lower ED means fewer extreme delays.
Example Code Snippet
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
numeric_inputs = keras.Input(shape=(numeric_feature_count,))
cat_inputs = keras.Input(shape=(categorical_feature_count,))
# Example embedding for high-cardinality categorical inputs
embedding_layer = layers.Embedding(input_dim=vocab_size, output_dim=embedding_dim)
embedded_cat = embedding_layer(cat_inputs)
flattened_cat = layers.Flatten()(embedded_cat)
# Combine numeric + embedded features
merged = layers.Concatenate()([numeric_inputs, flattened_cat])
# Shared hidden layers
dense1 = layers.Dense(256, activation='relu')(merged)
dense2 = layers.Dense(128, activation='relu')(dense1)
# Multiple output heads
o2a_output = layers.Dense(1, name='o2a')(dense2)
fm_output = layers.Dense(1, name='fm')(dense2)
wt_output = layers.Dense(1, name='wt')(dense2)
lm_output = layers.Dense(1, name='lm')(dense2)
o2r_output = layers.Dense(1, name='o2r')(dense2)
model = keras.Model(inputs=[numeric_inputs, cat_inputs],
outputs=[o2a_output, fm_output, wt_output, lm_output, o2r_output])
model.compile(optimizer='adam', loss='mae')
Practical Considerations
Training uses a large historical dataset. The platform often retrains or updates embeddings when new restaurants or geolocations appear. Real-time features depend on a streaming system collecting metrics on assignment latencies, restaurant stress, and traffic conditions. The final predictions populate the checkout page, and the same breakdown can feed downstream modules. A fallback logic handles unusual spikes or data outages, ensuring the system remains robust.
Follow-Up Question 1
How should the model handle situations where many orders cluster around a few restaurants or geographies while others remain sparse?
Answer
Partition the dataset by location, cuisine, or time windows to pinpoint areas with insufficient data. For those segments, rely on fallback logic or hierarchical methods that aggregate at a zone or city level. Entity embeddings help generalize across sparse categories by learning shared weights. A multi-task approach also distributes learned patterns from well-populated segments to sparse ones. Training with regularization prevents overfitting on data-rich zones. The system also refreshes embeddings on a schedule to incorporate new observations from emerging restaurants or geographies.
Follow-Up Question 2
How does the assignment engine’s timing logic affect first mile and wait time predictions, and what happens if the system logic changes?
Answer
The assignment engine often delays a delivery executive’s assignment if the restaurant’s preparation time is long, to reduce idle wait at the restaurant. This directly links assignment time to first mile travel. The MIMO setup integrates these outputs in one model, allowing deeper layers to learn the correlation: when predicted first mile is long, assignment might happen earlier, and vice versa. If system logic changes, the correlation between assignment time and first mile shifts. An updated dataset reflecting the new rules must be fed into retraining. A frequent retraining schedule or an online learning framework captures these shifts quickly.
Follow-Up Question 3
Why use a combined network approach instead of multiple isolated models for each leg?
Answer
Separate models waste synergy between related predictions and complicate maintenance. MIMO networks share features and hidden layers, forcing the model to learn relationships between the legs. Assignment and first mile have interdependent system rules. Combining them saves training and inference resources by reusing embeddings and shared dense layers. The joint approach achieves lower overall mean absolute error and handles cross-dependencies more naturally. A single model architecture reduces complexity in production and avoids consistency mismatches across multiple model outputs.
Follow-Up Question 4
How do you ensure on-time updates for near real-time signals, and what if there are delays in streaming data?
Answer
A message queue or streaming system pushes the latest metrics (restaurant load, region traffic speed) into in-memory storage at frequent intervals. The model inference pipeline queries this store to retrieve the latest features before generating predictions. If updates lag, the pipeline reverts to stale but valid values. The system monitors data freshness and falls back to rolled averages if the streaming layer fails. A re-initialization step triggers alarms when updates are stale beyond a threshold, prompting quick fixes to restore real-time inputs.
Follow-Up Question 5
How can you explain and justify the deep learning approach to stakeholders who prefer classic tree-based models?
Answer
Tree-based methods are intuitive but may struggle with high-dimensional sparse categorical variables, especially at the scale of thousands of restaurants. One-hot or other encodings can explode feature space. Entity embeddings in neural networks reduce dimensionality and learn latent patterns across sparse classes more efficiently. The MIMO architecture shares hidden representation across multiple outputs, capturing their interdependence. Empirical experiments demonstrate lower error metrics. Show that mean absolute error and extreme delays diminish with the neural network approach compared to tree-based baselines. Stakeholders see tangible benefits in fewer missed promises and more satisfied customers.
Follow-Up Question 6
Why is measuring ED critical, and how do you balance ED with other metrics like MAE and BDC?
Answer
ED captures the worst delays, which are detrimental to user trust and satisfaction. A low average error might still hide large outliers. The model’s training objective may combine MAE for overall accuracy and a penalty for severe misses. A custom loss function or a weighted approach can reduce average error while minimizing outliers. Fine-tuning hyperparameters ensures the model keeps ED low without sacrificing BDC or MAE. Balancing these metrics requires iterative tuning, guided by real-world feedback on customer satisfaction and operational constraints.