
ML Case-study Interview Question: Efficient Visual Product Search Using Multitask Deep Learning Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A large online marketplace has millions of diverse products, each with unique images. Users want to upload photos taken on their phones to find visually similar products. The marketplace needs an end-to-end system that transforms product images into embeddings, indexes them, and returns top matches for a user’s query photo in real time. The candidate must propose a robust deep-learning-based solution, describe how to train and validate the model, outline how to handle issues of categorical accuracy and visual similarity, and design an efficient inference pipeline for serving millions of daily requests.
Detailed Solution
A convolutional neural network (CNN) serves as the core method for converting an image into a vector embedding. That embedding encodes both categorical and visual features. A pre-trained backbone such as EfficientNet often speeds up convergence. The early layers remain mostly frozen, while the last few layers and a new classification “head” are fine-tuned on the marketplace’s data. This approach leverages existing knowledge from large-scale image datasets while adapting to the marketplace’s domain.
Multitask classification improves categorical accuracy and visual coherence. Multiple classification heads branch from the shared CNN body. Each head corresponds to a different set of labels (broad category, fine-grained category, color, etc.). The network updates shared weights using data from all tasks, then calculates separate losses per task. Additional data from user-generated photos helps the model learn robust embeddings that handle messy, low-quality inputs.
Triplet loss is an alternative that pushes visually similar images together and dissimilar ones apart. The anchor and positive samples come from the same item, and the negative from a different item. That setup forces embeddings to reflect visual similarity. However, classification-based multitask learning was chosen for more transparent metrics and better categorical control.
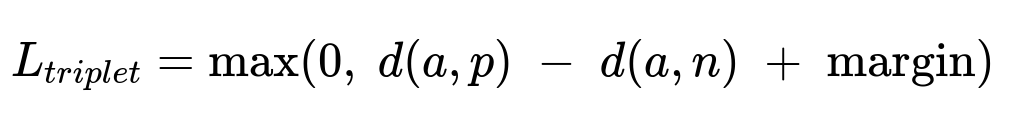
a is the anchor embedding, p is the positive embedding, n is the negative embedding, d() is the distance function, margin is a hyperparameter.
Classification heads optimize cross-entropy:
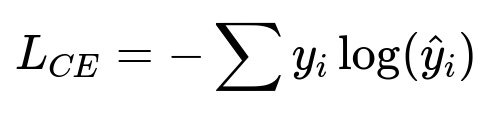
y is the ground truth distribution, hat{y} is the predicted probability distribution for each class.
These combined tasks produce a more balanced embedding that retains strong object-specific features and consistent color or pattern information.
An offline pipeline processes all listing images. The system computes embeddings for each image and constructs an approximate nearest neighbor (ANN) index. The inverted file approach (IVF) segments the embedding space into multiple clusters. The system references only the closest clusters to a given query embedding at runtime. This speeds up search by ignoring distant regions of the space.
Real-time inference uses GPUs for the query image. The user’s photo gets preprocessed, passed through the CNN, and turned into an embedding. That embedding is compared against the IVF clusters to find nearest neighbors. Results appear within milliseconds. The GPU solution is essential for large-scale, real-time use, since CNN inference on CPUs can be too slow for time-sensitive requests.
Multitask classification and large, diverse training data produce embeddings that handle both professional product photos and user-generated phone photos. This approach ensures that top retrieved items match the user’s query in color, pattern, and taxonomy.
Follow-up question 1
How should the training data be organized to avoid under-representing optional attributes like color or material?
Some attributes appear only for certain products. Splitting the training data into separate datasets for each attribute task, then drawing an equal number of samples from each dataset in each mini-batch, balances representation. Each task’s labels are specific to that dataset. The model processes all samples through the shared CNN, while only the relevant classification head computes loss for that specific dataset.
Follow-up question 2
How can the ANN index be updated if new product listings appear continuously?
Incremental index updates are possible if the system supports partial reindexing. After generating embeddings for newly arrived images, those vectors can be inserted into the IVF structure without a full rebuild. Periodic bulk rebuilds still help keep the index well-clustered.
Follow-up question 3
Why not train from scratch instead of using a pre-trained CNN?
Pre-trained CNN backbones provide strong low-level feature extractors. Training from scratch is expensive, especially with hundreds of millions of images. Fine-tuning a pre-trained backbone requires fewer epochs to converge, reduces computational costs, and avoids overfitting. It also benefits from the large-scale visual understanding the backbone already has.
Follow-up question 4
If user images differ drastically from the marketplace’s original product photos, what strategies improve retrieval quality?
Domain adaptation helps the model handle phone-captured images. Additional training on user-generated images corrects biases. Multitask classification on user-submitted photos of purchased items, combined with standard product images, gives the model exposure to varied backgrounds, lighting conditions, and resolutions. That improved distribution coverage makes it more robust to real-world queries.
Follow-up question 5
What are key considerations for production deployment under high traffic?
GPU resources must be provisioned to handle peak loads. A load balancer can route real-time inference requests to GPU-backed hosts. Keeping the model size manageable (for instance, using EfficientNet variants optimized for speed) also helps latency. Monitoring system performance ensures that response times stay within tight deadlines. Potential bottlenecks might arise in network communication with the ANN index, so caching frequently accessed embeddings or clustering them effectively can mitigate slow lookups.