
ML Case-study Interview Question: Retriever-Ranker Architecture with Vector Databases for Real-Time Service Matching.


Browse all the ML Case-Studies here.
Case-Study question
You lead a data science team at a large platform that connects service providers with clients. The existing recommendation system relies on a single monolithic model, but the firm wants a faster, more flexible approach. They propose a two-step “retriever-ranker” design that can handle 700,000+ service provider profiles and new client requests in near real-time. They also plan to store high-dimensional embeddings in a vector database. How would you design and implement this system end to end? What models and data structures would you use, how would you handle filtering, and how would you ensure low latency at scale?
Detailed solution
Overview of the retriever-ranker architecture
A bi-encoder (retriever) encodes both projects and provider profiles separately into embeddings. The system computes the embedding for a new project, then performs a nearest-neighbor search against the precomputed provider embeddings. This reduces the pool to a smaller subset for final ranking.
A cross-encoder (ranker) processes each project-provider pair directly for more precise scoring. This second step only deals with the subset returned by the retriever, which keeps runtime manageable.
Bi-encoder logic
Two transformer-based models generate embeddings: one for project text, one for provider profiles. Each vector captures contextual information about skills, experience, and relevant keywords. The project embedding is computed at request time. Provider embeddings are computed offline and updated regularly.
Approximate nearest neighbor (ANN) search
ANN algorithms accelerate similarity queries. Instead of checking every vector, ANN uses structures like graphs or trees to find the top K matches quickly. This cuts down lookup times dramatically even with large datasets.
Core similarity formula
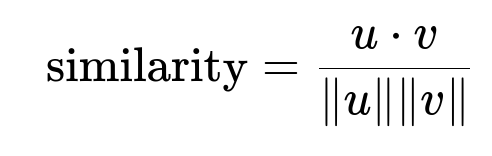
u is the embedding of the project. v is the embedding of a provider profile. The dot product of u and v is divided by the product of their magnitudes to compute the cosine similarity.
Vector database choice
A vector database streamlines ANN search, filtering, and embedding updates. The firm tests multiple solutions for speed, approximate nearest neighbor quality, and filtering on attributes such as location or availability. A specialized vector database with good spatial filtering support (for example, geo-based constraints) is chosen to handle large-scale queries and updates without high latency.
Deployment and scaling
Multiple nodes in a Kubernetes cluster manage the database shards. Each shard holds part of the embedding set. Replication ensures availability if a node goes down. Metrics from each node are collected with Prometheus for real-time monitoring of query throughput, latency, and system health. A robust setup avoids single points of failure.
Handling filters
Filtering occurs inside the vector database to exclude ineligible profiles based on location or other constraints. Some solutions apply filters after retrieving candidates, but that can hurt performance if the filters are strong. Others apply them before, but that might require large payloads to mask data. A database that natively supports filtering on embeddings plus standard attributes is best.
Example Python code
import qdrant_client
import numpy as np
client = qdrant_client.QdrantClient(host="my_vector_db_host")
def embed_project(project_text, embed_model):
return embed_model.encode(project_text)
def search_providers(project_vector, top_k=100):
search_result = client.search(
collection_name="providers",
query_vector=project_vector,
limit=top_k,
filter={
"must": [
{ "key": "location", "match": { "value": "desired_location" } }
]
}
)
return search_result
# Real-time embedding for the project
project_vector = embed_project("Need an experienced Java developer", my_embed_model)
# Retrieve top providers
candidates = search_providers(project_vector, top_k=100)
# Next: pass these candidates to the cross-encoder ranker for final sorting
This snippet shows how a project request is transformed into an embedding and used to query top matches from a vector database collection. The retrieved candidates then go to the cross-encoder ranker for precise scoring.
Ranker phase
The cross-encoder combines project text and each candidate’s profile in the same forward pass of a transformer. This captures higher-order dependencies missed by the retriever. The output is a relevance score. The system sorts candidates and returns the top few.
Ensuring low latency
Precomputing provider embeddings removes heavy computation from the live inference path. Storing embeddings in a specialized vector database speeds up top-K retrieval. The cross-encoder only runs on a small subset of candidates, limiting total inference time.
Observed performance gains
Latency can drop from tens of seconds to a few seconds. The two-step system preserves accuracy by using a fast, broad retriever and a slower, precise ranker only on the short list. This approach also supports real-time recommendation scenarios.
Possible follow-up questions
1) How do you periodically update embeddings for provider profiles?
They can be refreshed offline if providers change their information. A cron job or streaming pipeline recalculates embeddings and upserts them into the vector database. This can happen nightly or incrementally in near real-time.
2) Why not apply only a cross-encoder for all profiles?
Cross-encoders are computationally heavy. Scoring hundreds of thousands of profiles for each new project would cause long response times. The bi-encoder’s fast narrowing ensures the cross-encoder only sees a small candidate set.
3) How do you handle out-of-vocabulary skills or new technologies?
Transformer-based encoders generalize from context. If they see “Kotlin for Android apps,” they align the embedding with related frameworks even if “Kotlin” is rare. Periodically retraining on fresh data further refines this.
4) What if some queries need classic keyword search?
Hybrid approaches combine semantic retrieval with standard keyword indexing. The vector DB or a text-search engine can merge both results. This captures exact keyword matches and semantically related profiles.
5) How can you tune ANN parameters for best performance?
You can vary graph connectivity or tree structures and measure recall vs. latency. More robust structures give higher recall but require more memory. Fewer layers or edges can reduce recall but speed queries. Empirical tests balance these trade-offs.
6) How do you assure filters do not degrade the ANN algorithm?
Large masks or aggressive filtering can lead to poor recall. A tight integration in the database ensures that neighbor-finding is optimized with awareness of filters. Proper indexing and data partitioning help maintain speed and accuracy.
7) What metrics do you track post-deployment?
Latency distributions (p50, p95, p99) ensure the system scales under load. Conversion rates measure if users hire recommended providers. Embedding drift is checked by comparing historical vs. current embeddings to see if the model still matches real-world data.
8) How do you validate the quality of the final ranked list?
Collect ground truth matches where projects hired certain providers. Compare model-recommended lists vs. actual hires. Measure ranking metrics like mean reciprocal rank (MRR) or normalized discounted cumulative gain (nDCG) to see how high correct profiles appear.