
ML Case-study Interview Question: CRNN for Overlapping Frame-Level Speech and Music Detection in Audio


Browse all the ML Case-Studies here.
Case-Study question
You are a Senior Data Scientist at a large streaming platform. The product engineering team wants an automated system to identify speech and music in TV and film audio tracks. They have limited resources for manually labeling data, and most of their audio is in 5.1 surround format with multilingual content. They require frame-level classification of speech and music, allowing overlaps where both speech and music occur simultaneously. They also want this solution integrated into various downstream tasks such as dataset curation, dialogue analysis, and loudness normalization. How would you design and implement such a system from end to end, including data collection, model training, deployment, and performance evaluation?
Detailed Solution
Using a catalog of existing audio sources is useful for collecting data at scale. The labeling might be noisy, but the volume of data can offset the inaccuracy. The audio typically arrives as 5.1 surround at 48 kHz. First downmix to a single-channel wave (for example using an ITU-standard downmix) and downsample to 16 kHz. Normalize to a consistent loudness range (e.g., −27 LKFS ± 2 LU) to avoid volume-based bias. Split each file into segments of about 20 seconds for training. Map approximate speech/music intervals to these segments from available subtitle/metadata, accepting the imperfection in timecodes to expand the dataset. Retain segments with language variety to generalize better.
Model Architecture
A Convolutional Recurrent Neural Network (CRNN) suits this task. Convolutional layers capture local patterns in spectrograms. Recurrent layers preserve temporal context. A feasible configuration is three convolutional layers (with increasing channel depth), followed by two bi-directional recurrent layers and a fully connected output layer producing frame-level probabilities for speech and music. Use log-Mel or per-channel energy normalization (PCEN) features. Train with frame-level binary cross-entropy loss.
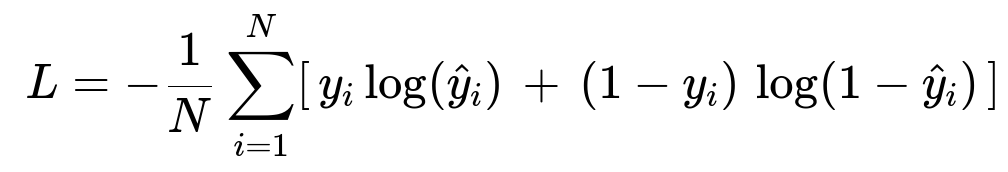
N is the batch size of frames in a segment. y_i is the ground-truth (0 or 1), and hat{y}_i is the predicted probability for a class (speech or music).
After training, the model outputs continuous probabilities at about 5 frames per second. Threshold these outputs (e.g., 0.5) to obtain binary classification of speech and music. Overlapping output indicates the frame has both speech and music.
Example PyTorch Snippet
import torch
import torch.nn as nn
class CRNNModel(nn.Module):
def __init__(self, input_dim=64, conv_channels=[32, 64, 128], rnn_units=128):
super(CRNNModel, self).__init__()
self.conv1 = nn.Conv2d(1, conv_channels[0], kernel_size=(3,3), padding=1)
self.conv2 = nn.Conv2d(conv_channels[0], conv_channels[1], kernel_size=(3,3), padding=1)
self.conv3 = nn.Conv2d(conv_channels[1], conv_channels[2], kernel_size=(3,3), padding=1)
self.pool = nn.MaxPool2d((2,2))
self.relu = nn.ReLU()
self.rnn = nn.GRU(conv_channels[2]* (input_dim//8), rnn_units, num_layers=2,
bidirectional=True, batch_first=True)
self.fc = nn.Linear(2*rnn_units, 2)
def forward(self, x):
# x shape: (batch_size, 1, freq_bins, time_steps)
out = self.relu(self.conv1(x))
out = self.pool(out)
out = self.relu(self.conv2(out))
out = self.pool(out)
out = self.relu(self.conv3(out))
out = self.pool(out)
# Flatten freq dimension
b, c, f, t = out.shape
out = out.view(b, c*f, t).transpose(1,2)
# out shape: (batch_size, time_steps, c*f)
out, _ = self.rnn(out)
# out shape: (batch_size, time_steps, 2*rnn_units)
out = self.fc(out)
# out shape: (batch_size, time_steps, 2) -> 2 classes: speech, music
return out
Evaluation
Use a manually annotated test set of various shows and languages. Compare frame-level predictions vs. ground truth. Measure F-score and error rate, defined by the sum of false-negative and false-positive rates for each class. Inspect insertion (false detection) vs. deletion (missed detection) of speech or music. Ensure that singing regions are labeled as both speech and music.
Deployment
Embed the CRNN inference in the post-production or content processing pipeline. Batch-process the audio tracks, store speech/music frame predictions, and supply the results to loudness normalization, audio description mixing, or subtitling tasks. Real-time inference is optional but often unnecessary in typical content workflows. Containerize the model for reproducibility. Integrate automated checks for memory and GPU/CPU usage.
Scalability and Maintenance
Use a data pipeline that continuously updates with new training examples. Rely on operational logging to identify mislabeled segments. Re-label challenging or ambiguous regions if false positives or negatives recur. Retrain periodically with more diverse content to handle new languages or audio mastering trends.
Possible Follow-up Questions
How do you handle ambiguous scenarios where singing voices overlap with background music?
Label singing as both speech and music. In the model output, the speech node and the music node both activate if the network detects melodic singing and spoken content. This approach aligns with how closed-captions often treat song lyrics.
Why is it better to train with a large but noisy-labeled dataset rather than a small precise-labeled dataset?
Large, diverse data increases generalization. The model learns robust patterns across multiple genres and languages. Minor label noise often becomes less significant when training with sufficiently large data. Small, perfectly labeled datasets might overfit or fail to capture variations.
How do you ensure the model is language-agnostic?
Use raw acoustic features like log-Mel or PCEN that capture timbral and rhythmic aspects, not language-specific cues. Train on a broad mix of languages. This approach focuses on general spectral/temporal differences between speech and music, rather than lexical content.
How would you extend this model to detect other classes like environmental sounds?
Add more output nodes for each new class. Collect new training samples with bounding intervals for those sounds. Retrain with a multi-label approach so that environmental sounds can also overlap with speech or music.
What considerations are there for real-time inference if the workflow demands it?
Optimize the model size by reducing layers or channels. Use a streaming-capable implementation of the recurrent layers. Ensure minimal latency by processing frames in smaller batches. Monitor memory usage and move to GPU inference only if it significantly reduces end-to-end latency.