
ML Case-study Interview Question: ML Classification for Detecting Outdated Browsers and Recommending Personalized Upgrades


Case-Study question
A large online platform noticed a significant segment of users browsing with outdated software. The platform has a massive dataset of user-device interactions, engagement logs, and retention metrics. The goal is to build a Machine Learning system to identify outdated browsers in real time, recommend an appropriate upgrade path, and track the resulting impact on user engagement and retention. Propose a complete approach to design and implement this system at scale. Cover data ingestion and feature engineering pipelines, model selection, model training, personalization strategies for recommendations, and the experimental setup for measuring key metrics like retention. Also consider fairness and any potential system bottlenecks or biases. Propose both offline experiments and potential online testing frameworks.
Detailed solution
Data ingestion and feature engineering involve collecting logs of user interactions, device specifications, operating system information, and historical engagement metrics. Distributed systems ingest these logs. Transformations clean and normalize the raw input. Outdated browsers have distinct signatures in their user-agent strings, which feed into the model as categorical features. Engagement-level features include total session time, video-watch patterns, and frequency of interactions like likes or comments. This consolidated feature set is joined with label data indicating whether the browser was updated in the subsequent sessions.
Model selection can start with a classification approach. A supervised model is trained on historical logs indicating whether a user eventually updated or continued using the old browser. The objective is to learn patterns that predict the likelihood of an update if prompted. Training data can be large, so distributed training on Spark or a parameter server setup for GPU clusters is common. Model candidates include gradient boosted trees or neural networks. Hyperparameter tuning focuses on accuracy, recall, and precision for update prediction. The system triggers a recommendation strategy when the model detects high-likelihood updaters.
Recommendation strategies revolve around personalizing the upgrade prompt. The system might use a multi-armed bandit approach to adapt and show different prompts. The bandit algorithm selects from various prompt types and optimizes for click-through rate or update completions. The platform controls for confounding effects via a randomized online experiment. Exposed groups see the recommended prompts, while control groups see either a simpler prompt or no prompt. A/B testing solutions integrate with the platform’s back-end. Lift in update rate and changes in user engagement after updating measure success.
The data pipeline must handle the sheer scale of logs (possibly billions of daily events). Batch processing with scheduled jobs can build daily or hourly snapshots for feature generation. Real-time streaming frameworks like Apache Kafka push updates to an online scoring model. A low-latency service hosts the trained model for scoring. A microservices architecture decouples the scoring service from the application front-end. The front-end checks with the model service for a user’s likelihood of update, then renders the recommended prompt.
Ethical considerations include ensuring that the prompts do not unfairly pressure or discriminate. Many users with older machines have constraints that prevent updates. The system must handle language localization and accessibility. Fairness metrics examine if certain demographic segments are over-targeted or incorrectly flagged.
Model performance evaluation involves standard metrics. Accuracy checks how well the system identifies outdated browsers. Precision and recall evaluate how effectively the prompts lead to real updates. A true positive is a user who receives a prompt and upgrades soon after. A false positive is a user who receives a prompt but never upgrades. Model calibration helps ensure probability outputs align with real-world likelihoods. Over time, the platform retrains the model on evolving browser usage patterns.
Logistic regression example
Sometimes logistic regression is used for interpretable modeling of whether a user will upgrade after a prompt. The cost function for training logistic regression is often given by:
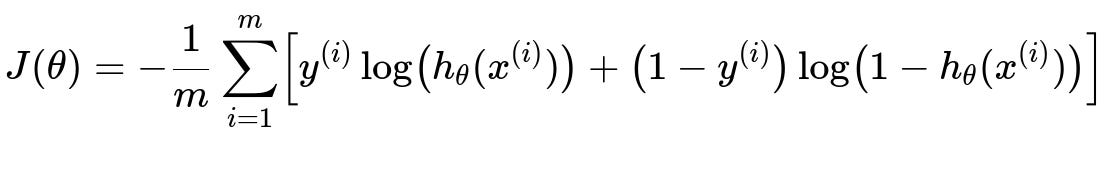
J(theta) is the overall cost function measuring how far predictions are from actual labels. m is the number of training examples. y^(i) is the true label for example i (1 if the user eventually upgrades, 0 otherwise). h_theta(x^(i)) is the predicted probability of upgrade for example i. Minimizing this cost function with gradient descent helps the model learn parameters that maximize correct upgrade predictions.
Implementation details involve building training pipelines to extract user logs, labeling them based on upgrade events, and feeding them into a logistic regression or other chosen model. Hyperparameter tuning adjusts regularization strength to handle overfitting. Coefficients reveal which signals influence upgrade likelihood most. Interpretability can guide prompt design if certain features like “number of plugin crashes” or “severe performance issues” correlate strongly with successful upgrades.
Online deployment requires a service that receives a user’s features in real time. The service computes the score or classification label. The front-end then decides how to present the upgrade prompt. A separate microservice records outcomes. If the user updates, the system logs the time from prompt to upgrade. Analytics dashboards track key metrics.
System bottlenecks might appear when the feature store fails to update in a timely manner, leading to stale user profiles. Solutions include caching or partial real-time updates. Biases might arise if older devices are overrepresented among certain demographic segments. Fairness evaluations measure whether these users are systematically targeted. Mitigation strategies might adapt thresholds or reweigh samples.
Example Python snippet
import pyspark.sql.functions as F
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import GBTClassifier
from pyspark.ml import Pipeline
# Load user-browser logs into a Spark DataFrame
df_logs = spark.read.parquet("user_logs.parquet")
# Feature engineering
df_features = df_logs.withColumn("browser_outdated", F.when(F.col("browser_version") < 80, 1).otherwise(0))
df_features = df_features.withColumn("engagement_score", F.col("session_time") * F.col("actions"))
assembler = VectorAssembler(inputCols=["browser_outdated", "engagement_score"], outputCol="features")
df_final = assembler.transform(df_features)
# Train model
gbt = GBTClassifier(labelCol="label", featuresCol="features", maxIter=50)
pipeline = Pipeline(stages=[assembler, gbt])
model = pipeline.fit(df_final)
# Predict
predictions = model.transform(df_final)
This example loads logs into Spark, creates features, fits a gradient boosted tree classifier, and generates predictions. Production setups require better model governance and more sophisticated feature engineering.
Potential follow-up questions
What if the update prompt itself introduces bias in how certain user groups respond?
The model might be predicting that a specific demographic is more likely to upgrade and may over-target them with prompts, which could be unfair. Addressing this involves monitoring model outputs across different segments. If there is systematic over-targeting, adjusting thresholds or adding fairness constraints can help. Collecting more representative training data and carefully analyzing upgrade rates by user segment also helps.
How do we ensure that the system remains reliable as browser usage evolves?
Regularly retraining or fine-tuning the model captures new browser versions and changing user behaviors. Automated checks watch for data drift by comparing recent distributions of features and predictions against historical baselines. Feature engineering must stay current, since new browser versions or changes to operating systems can alter user logs. Continuous integration pipelines rebuild and retest models on updated data.
What if users receive too many prompts and get annoyed?
Over-prompting might hurt user experience. Tracking negative outcomes like increased bounce rates after repeated prompts helps identify saturation. This can be mitigated by a recommendation policy that controls frequency of prompts per user. Reinforcement learning or multi-armed bandits can incorporate penalties for churn when deciding whether to prompt. A well-tuned frequency capping strategy preserves engagement while encouraging essential updates.
How do we handle cases where users cannot upgrade due to hardware limitations?
The model might classify them as prime candidates, but they fail to complete the update. This can inflate false positives. Solutions involve robust device-level checks that factor in hardware constraints. The system can route users on legacy hardware to alternative solutions or a more lightweight version of the platform. The labeling process should account for a user’s device eligibility to avoid spurious prompts.
Why might a gradient boosted tree or ensemble method be more suitable than logistic regression here?
Gradient boosting handles complex, nonlinear interactions, especially with high-dimensional browser and engagement data. It often yields higher predictive performance. Logistic regression is simpler and more interpretable but might not capture intricate correlations and feature interactions as effectively. Ensemble methods can combine interpretability methods such as feature importance with higher accuracy, making them valuable for large-scale classification.
How do we measure success beyond upgrade rates?
Engagement metrics like average session duration, watch frequency, and retention can reflect improved experiences. Reduced error rates and crash events can also show if updates enhanced user satisfaction. Longitudinal analysis tracks engagement before and after browser updates to confirm improvements. These metrics determine whether the system’s interventions produce real business impact.
What steps do we take to deploy this solution globally?
A microservices architecture scales across regions. Each region has local data processing and a model service for faster latency. Region-specific guidelines ensure compliance with data protection laws. The pipeline accommodates multiple languages and variations in common browser usage by geography. Monitoring dashboards compare model performance across regions to identify anomalies. Automatic retraining or updates are scheduled for each region’s data streams.
This end-to-end setup addresses the question of building a Machine Learning system that detects outdated browsers, recommends upgrades, and measures user engagement impact. The approach integrates data ingestion, feature engineering, model training, evaluation, and an online experimentation framework in a distributed environment.