
ML Case-study Interview Question: Accelerating Grammatical Error Correction with Interpretable Sequence Tagging


Browse all the ML Case-Studies here.
Case-Study question
A global writing platform wants to improve grammatical error correction for millions of users. They have an existing system that translates erroneous sentences into corrected ones but it is slow and lacks interpretability (it cannot easily explain what was corrected). They need a faster, more transparent solution. Design a sequence-tagging approach that tags each word in a sentence with transformations describing how to fix mistakes, then iteratively applies those transformations until the sentence is corrected. Show how you would handle training (including any data augmentation), inference speed, and performance measurement. Propose a full architecture, explain how you would test it, and ensure it can run at scale in a production environment.
Detailed solution
The proposed solution replaces the encoder-decoder (translation-based) approach with a sequence-tagging model. It focuses on transforming tokens through specific tags rather than rewriting entire sentences. This significantly speeds up inference because the model can process tokens in parallel, reducing the complexity of generating text.
Model architecture
A BERT-like transformer encoder takes tokenized sentences as input. It outputs contextual embeddings for each token. Two linear layers follow:
One detects the presence of an error at each token.
One assigns a specific transformation tag to each token, such as $KEEP, $DELETE, $APPEND_{some_token}, $REPLACE_{some_token}, or advanced tags like $VERB_FORM and $NOUN_NUMBER.
Tagging process
Each token gets a single tag. If a token is deemed correct, the model assigns $KEEP. If a token is unnecessary, the model assigns $DELETE. If the token needs to be replaced, the model outputs $REPLACE_{replacement_word}. When morphological changes are needed, special tags like $VERB_FORM (switch from VB to VBZ) or $NOUN_NUMBER (singular to plural) are used. Some tags handle merges (e.g., $MERGE_HYPHEN) or splits.
Training strategy
Use three stages:
Pre-train on a large synthetic corpus of source/target sentence pairs with artificially induced errors.
Fine-tune on a mid-sized real-world data set with known corrections.
Fine-tune again on a smaller, clean data set that may include sentences without errors at all.
This multi-stage training ensures the model first learns broad error patterns, then aligns to real data distributions, and finally refines precision by seeing correct sentences.
Inference with iterative correction
Run the model on an input sentence. Apply the predicted tag transformations to each token. Re-tokenize or re-align if merges or splits occur. Re-run the model on the updated sentence for another pass. This iterative loop stops after a set number of passes or when no further edits occur. Most corrections happen by the second iteration.
Key performance metric
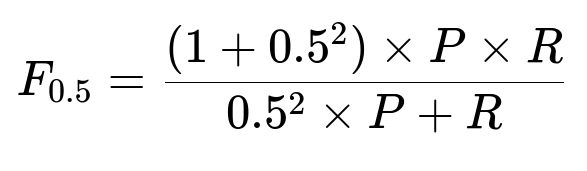
Here, P is precision and R is recall. F0.5 heavily weights precision. High precision is crucial because users dislike unnecessary or incorrect edits.
Hyperparameter tuning
Add a confidence bias to $KEEP so the system only changes tokens when it is confident. Then set a minimum error probability threshold. This yields better precision, though at a potential recall trade-off. Random search identifies optimal thresholds.
Speed benefits
Sequence tagging does not generate tokens autoregressively. The system can assign tags to all tokens in parallel. On large batches, a single pass can be up to 10x faster than a traditional transformer-based translation approach. A few short iterations often suffice, boosting throughput for production-scale requests.
Practical example
def iterative_tagging_pipeline(sentence, model, max_iterations=3):
for _ in range(max_iterations):
tags = model.predict_tags(sentence)
updated_sentence = apply_tags(sentence, tags)
if updated_sentence == sentence:
break
sentence = updated_sentence
return sentence
This pseudo-code repeatedly applies tags until no more changes occur or until reaching the maximum number of iterations. Each iteration updates the sentence. The function apply_tags() handles merges, splits, or replacements.
Testing and validation
Split data into development and test sets. Continuously monitor F0.5 on both sets. Compare the model’s speed and correction quality against a baseline translation-based system. Confirm that sentence-level improvements match real-world user needs, especially regarding clarity and correctness.
What if the training data is limited?
Small data sets can be expanded by artificially injecting errors into large corpora. Use heuristic or rule-based methods to mimic spelling errors, incorrect verb conjugations, or missing punctuation. This boosts coverage of diverse error types. The multi-stage fine-tuning strategy still applies.
How to handle domain-specific text?
Collect domain-specific language (technical, legal, etc.) and add it to training. Fine-tune the final model on a smaller set of specialized text. This tunes the transformation tags to domain vocabulary and style.
How to interpret the model’s suggestions?
Tokens receive interpretable tags like $REPLACE_went or $APPEND_,. This makes it possible to show humans precisely which fixes were made. For morphological tags ($VERB_FORM or $NOUN_NUMBER), store morphological change details (e.g., “past tense to past participle”).
How to ensure real-time performance?
Optimize parallel inference with GPUs or specialized accelerators. Use mini-batches to process multiple sentences simultaneously. Limit the iteration count to balance speed vs. accuracy. Monitor average latency in production.
How to debug incorrect corrections?
Log (token, predicted_tag) pairs for each iteration. Inspect whether misaligned tags or spurious merges occur. Adjust confidence thresholds or reduce iteration count if overcorrection is frequent. Evaluate each iteration’s outputs on hold-out examples.
What about ensemble methods?
Run multiple sequence-tagging models (possibly with different hyperparameters) in parallel. Average their outputs (i.e., probabilities for each tag) to form final predictions. This improves F0.5 by combining strengths of diverse models at some extra computational cost.
How to keep pace with new language usage?
Continuously retrain or fine-tune with fresh error data. If user input patterns shift, gather these new examples and incorporate them into the synthetic or real fine-tuning sets. Update morphological tag dictionaries if new slang or neologisms appear.