
ML Case-study Interview Question: Stabilizing Search Ranks: Using Layered Systems, Twiddlers, and User Feedback Loops.


Browse all the ML Case-Studies here.
Case-Study question
You are leading a search-ranking platform at a large tech organization. The platform indexes vast web documents and assigns each document a unique identifier. A complex pipeline moves documents from raw data ingestion into a sophisticated ranking system. Components include a scheduling system for crawl frequency, an indexing layer storing old content versions, re-ranking filters called “twiddlers,” a navigation-driven booster, and various machine-learning models. Newly published content may rank poorly or be boosted by certain signals such as commercial intent or brand authority. Some filters demote suspicious or outdated pages. A user-interaction system measures clicks, bounce rates, and dwell time. When real-time events spike demand for specific information, re-ranking rules prioritize freshness or official domains. This pipeline can significantly shift ranks even if the underlying content does not change. Explain how you would address inconsistent rankings, incorporate user-feedback loops, and ensure relevant results for different query intents in a maintainable way.
Detailed solution
System Overview
The first step is building a layered system to handle document ingestion and ranking. Documents enter via sitemaps, backlinks, or direct submissions. A scheduling module decides how often to revisit known documents. A data store layer indexes each document, preserving multiple versions for historical tracking and potential reversals of spam. A distributed cluster moves high-value documents to fast storage for quicker ranking.
Core Ranking and Initial Signals
The initial sort uses information retrieval scoring. The system extracts term occurrences, heading structures, and domain-level authority. It merges them into an inverted index for retrieving relevant documents. The top 1000 or so documents form a short-list. Additional modules then refine their scores.
Role of Twiddlers
Each twiddler is a self-contained re-ranking plugin that modifies document scores based on specialized criteria. Some twiddlers detect content freshness. Others measure domain relevance. Another may limit over-representation of similar content. Twiddlers are easier to create than editing a monolithic ranking system.
Navigational Signals
A navigation-based booster (NavBoost) reads user behavior to adjust rank positions. The platform records the difference between expected clicks and actual clicks. If a snippet’s click rate is higher than the norm, the document’s rank rises. If the snippet underperforms, it may move down. Internal data from the browser helps measure dwell time, identifying which domains truly satisfy visitors.
CTR and User Feedback
The system normalizes clicks over time to offset anomalies. For new pages, the platform seeds approximate signals from the domain’s history. This way, a new page on a strong domain can rank sooner, while repeated short-bounce visits can demote it rapidly. Quality raters also provide input by labeling sample documents. Those ratings train machine-learning models that extrapolate signals to many unseen pages.
Handling Real-Time Events
When external events or media references drive large bursts of queries, the system detects changing user intent. A freshness module can demote purely transactional pages when users seek breaking news. Once traffic stabilizes, the module reverts to normal ranking. The system might exploit fast re-rankers (InstantNavBoost) that swap out results near the final assembly of the search page.
PageRank Core
The platform computes a connectivity-based metric similar to PageRank. The well-known formula:
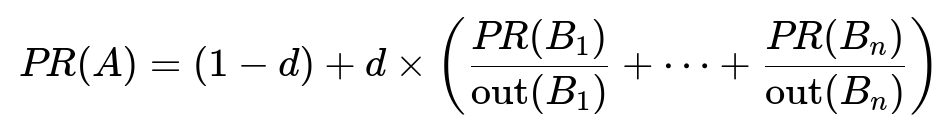
PR(A) is the rank score of page A. d is the damping factor, usually around 0.85. PR(B_i) is the rank of page B_i. out(B_i) is the number of outbound links from B_i. Each link’s contribution is fractionally allocated by out(B_i). Higher inbound links from authoritative pages increase PR(A).
Implementation Example
A minimal Python snippet for user-behavior-based re-ranking could look like this:
import numpy as np
def re_rank_with_clicks(candidate_docs, global_ctr_map):
# candidate_docs is a list of (doc_id, base_score)
# global_ctr_map holds (doc_id -> observed_ctr) from historical data
updated_docs = []
for doc_id, base_score in candidate_docs:
observed_ctr = global_ctr_map.get(doc_id, 0.0)
# Example: scale rank by a CTR factor
new_score = base_score * (1 + observed_ctr)
updated_docs.append((doc_id, new_score))
# Sort by new_score descending
updated_docs.sort(key=lambda x: x[1], reverse=True)
return updated_docs
This simplistic approach multiplies a base score by (1 + observed_ctr). Real production code uses more sophisticated weighting, time decay, and query-specific CTR data.
Maintaining Quality and Relevance
A strong brand presence or a domain with many loyal visitors can lift new pages. If the document cluster is low quality, the system’s re-ranking penalizes all those pages. Continuous assessment of bounce rates reveals whether visitors actually find what they want.
Continuous Testing
Live tests run daily. Some documents are “promoted” temporarily to see how users interact. If click patterns show promise, the system keeps them in higher ranks. If not, they fall back. This iterative approach leverages real-time engagement signals, ensuring the final result set remains aligned with user needs.
How do you detect and neutralize spam pages?
Twiddlers may identify unnatural backlink structures or suspiciously high keyword density. A separate classifier can analyze repeating patterns in text and anchor text. If these patterns match spam profiles, the system sets a demotion flag. These demotions sometimes limit maximum rank positions, ignoring normal signals. A few spam pages are still retained for analysis, but they are quarantined and do not propagate negative signals beyond.
Machine-learning models trained on rater feedback also detect disguised spam. Repeated down-votes by raters or high bounce rates from real searches can trigger stronger demotions.
How do you safeguard user signals from manipulation?
User interaction signals become reliable when aggregated over time and large sample sizes. The system identifies sudden spikes in clicks from abnormal regions or automated scripts. Recurrent short visits from the same source are ignored. The platform employs domain-level IP analysis, browser fingerprinting, and hidden validation steps. This helps discount suspected click fraud. Trust increases when real users from diverse devices sustain consistent engagement patterns.
How do you handle event-driven spikes in queries?
A real-time layer monitors trending queries. When an unusual jump occurs, a freshness or timeliness twiddler inspects the top 1000 documents. The system temporarily lifts results from official or expert sources, matching the emergent user intent. It downgrades purely commercial or off-topic pages. Once interest subsides, re-ranking reverts to long-standing signals. This approach ensures swift adaptation while preserving stable behavior for regular queries.
How do you assess performance and model accuracy?
The organization collects metrics on user engagement, click-through rates, dwell times, and final search endpoints. A specialized RankLab environment tests new filters or twiddlers against a holdout data set. Analysts measure changes in user satisfaction, looking at whether queries end on the displayed results or if follow-up searches are needed. If an experimental feature consistently boosts good outcomes, it is promoted. If not, it is refined or rolled back.
How do you refine the model for different query intents?
Embedding-based classifiers characterize each query’s intent: transactional, informational, or navigational. The ranking pipeline adjusts weighting accordingly. Transactional queries favor commercial or product pages. Informational queries lift tutorial or research-oriented pages. Model training uses rater feedback plus session data revealing which result types solve the query. Continuous re-runs on new queries yield refined embeddings, improving alignment with actual user goals.