
ML Case-study Interview Question: Hybrid Deep Learning Static Analysis for Scalable Code Vulnerability Detection


Browse all the ML Case-Studies here.
Case-Study question
A large-scale platform handles thousands of repositories and wants to detect potential security vulnerabilities in source code before deployment. They built a static analysis pipeline that uses both manually written security rules and a deep learning classifier to identify unsafe patterns, especially those involving untrusted user data. They generated a training set by running the manual rules on a large code corpus and labeling any code snippet flagged by the old rules as a positive example, while everything else was labeled negative. They trained a deep neural network to find new cases the old rules missed, such as SQL injection paths in rarely used libraries. They now plan to deploy this pipeline in production. How would you design and implement a complete solution, ensuring high detection rates, minimal noise, and continuous improvements to the models? Describe your architectural choices, feature engineering strategies, labeling approach, handling of large datasets, runtime performance considerations, and how you would measure success.
Constraints and key requirements:
Must run on standard CI/CD runners within reasonable time.
Must handle public and private repositories with minimal manual rule maintenance.
Should automatically improve from real-world feedback on flagged alerts.
Detailed solution
Overview of the approach
Build a static analysis pipeline that combines rule-based techniques and machine learning classification. The rule-based component flags specific known patterns. The machine learning component generalizes to unseen libraries and code structures by learning from code snippets labeled by older rule-based outputs.
Data acquisition
Collect a large number of public repositories to generate training data. Infer positive and negative labels from older manual rules. Snippets matching these older rules become positive labels. Others become negatives by default. Acknowledge that this labeling is noisy. Mitigate noise by gathering huge volumes of data.
Feature extraction
Represent each code snippet with syntactic and semantic features. Extract function bodies, API names, data-flow paths, argument indices, and file-level metadata. Use sub-tokenization for long identifiers to capture partial matches (for example, "sqlQueryManager" -> ["sql", "query", "manager"]). Transform each token into an integer vocabulary index for the neural network. Concatenate features so the model learns from code structure, not just raw text.
Model training
Use a deep learning architecture with multiple embedding layers for different feature types. Concatenate them before final dense layers that output probabilities for each vulnerability type. Leverage cloud GPUs for large-scale training. After training, store the model so it can run inference on standard CPU machines.
Predictive inference in CI/CD
When new code is pushed, extract features for each snippet. Run them through the model to get probability scores. Use a threshold to surface alerts that are likely vulnerabilities. Label these as “Experimental” so developers can distinguish them from traditional rule-based alerts.
Measuring performance
Compare model predictions to known vulnerabilities flagged by up-to-date manual rules. Track recall as fraction of new vulnerabilities discovered. Track precision as fraction of reported vulnerabilities that are real. Evaluate runtime overhead by measuring how long the entire pipeline takes on a typical repository.
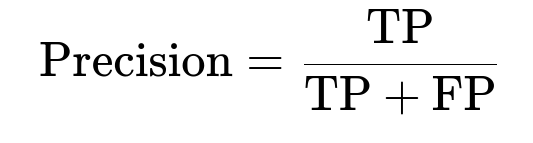
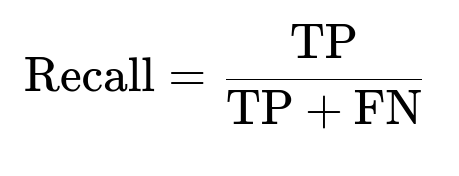
TP is true positives, FP is false positives, FN is false negatives. Higher precision means fewer false alarms. Higher recall means fewer missed vulnerabilities.
Model improvement loop
Expose alerts to developers. Let them mark valid or invalid. Feed these outcomes back into a retraining pipeline. Incorporate updated manual rules. Expand training data. Retrain and redeploy the model periodically.
Practical example
A custom framework might sanitize user data with a function not recognized by old rules. The model sees the new function name and context. It classifies the snippet as potentially unsafe if it resembles known SQL injection patterns. This alert then gets surfaced for the developer’s review.
Code snippet illustration
Below is a simplified example of extracting data-flow features in Python:
import ast
def extract_snippet_features(code):
tree = ast.parse(code)
features = {}
# Walk the AST, collecting tokens, function names, argument positions, etc.
for node in ast.walk(tree):
if isinstance(node, ast.Call):
func_name = getattr(node.func, 'id', None)
features['func_name'] = func_name
arg_list = []
for idx, arg in enumerate(node.args):
arg_type = type(arg).__name__
arg_list.append(f"arg{idx}_{arg_type}")
features['args'] = arg_list
return features
sample_code = "execute_db_query(user_input)"
feat = extract_snippet_features(sample_code)
print(feat)
This demonstration shows how to gather basic call-site features. A real system would be more thorough.
Possible follow-up questions
How do you address label noise caused by using older rule-based outputs as ground truth?
Label noise exists because some snippets not flagged by old rules might still be vulnerable. Train at scale with many repositories so random noise averages out. Apply data cleaning methods. Confirm suspicious outliers with partial manual inspection or improved rules. Use confidence-based weighting, giving uncertain labels lower weight. Retrain frequently with refined labels from user feedback.
How do you decide the threshold to classify a snippet as a vulnerability?
Examine precision-recall curves on validation data. Pick a threshold that balances desired recall with acceptable false positives. Some organizations might prefer higher recall, others might prioritize a low false-alarm rate. Potentially adopt dynamic thresholds based on code criticality or environment constraints. Monitor production results and adjust if developers see too many incorrect alerts.
How do you ensure the system scales for very large repositories?
Implement feature extraction in a streaming fashion, rather than loading the entire codebase into memory at once. Parallelize across multiple workers if allowed by the environment. Cache intermediate artifacts to skip reprocessing unchanged files. Optimize the neural network inference by using efficient batch operations. Profile each step to identify bottlenecks.
What techniques can handle code evolution over time?
Maintain versioned models and training sets. Periodically retrain on updated code samples that reflect newer patterns and libraries. Monitor drift in the distribution of code tokens. If there is a large mismatch, schedule a retraining cycle. Encourage developer feedback on false positives and missed vulnerabilities to get real-world updates on code changes. Keep older model references for rollback if needed.
How would you integrate user feedback into retraining?
Record each case where a developer dismisses an alert or marks it as valid. Store these outcomes in a feedback database. During retraining, treat validated alerts as strong positives and dismissed alerts as strong negatives. Possibly incorporate confidence scores so repeated confirmations weigh more. Retraining might be done periodically (for example, monthly) to ensure consistent updates while limiting overhead.
Why not rely solely on manual rules without machine learning?
Manual rules miss new frameworks, library calls, or evolving vulnerability patterns. Writing new rules for every obscure library is impractical. A machine learning model generalizes from large examples and helps catch patterns that rules did not explicitly encode. This hybrid system captures a broader range of issues, especially zero-day or lesser-known exploit paths.