
ML Case-study Interview Question: Scaling Personalized Video Recommendations: Two-Tower Embeddings & ANN Retrieval.


Browse all the ML Case-Studies here.
Case-Study question
A short-video platform with a massive user base and an extensive video catalog needs to improve recommendation efficiency and personalization. The naive approach of scoring every possible video for each user is too slow. Traditional text-based retrieval is also insufficient due to the limited textual metadata. How would you design an embedding-based retrieval system that can handle this scale, incorporate personalization signals, generate embeddings for both users and videos, and achieve low latency in an online setting? Propose a complete architecture covering training, inference, negative sampling, index building, and system deployment. Include details about how you would ensure fresh embeddings for new videos, update embeddings for existing users, and handle large-scale similarity searches in real time.
Detailed Solution
Model Architecture
Two-tower networks generate user and video embeddings in parallel. Each tower processes only features relevant to its entity. This separation ensures user and video embeddings do not leak features from each other. The user tower ingests features such as demographic data, user engagement history, and aggregated signals from recently watched videos. The video tower encodes available attributes from the video, creator metadata, and content-based embeddings. Both towers employ a ResNet-style neural network plus a 4-layer deep cross network. Dense features are normalized before being concatenated with sparse features. An Adam optimizer with cosine annealing gradually adjusts the learning rate, starting with a warm-up period to stabilize early training. The final output embeddings on each tower are 128-dimensional vectors.
Objective Function
The primary training target is to predict a positive user-video interaction (long view, favorite, or other engagement actions). The model uses a binary cross-entropy loss. The dot product of user embedding u and video embedding v goes through a sigmoid function to get the probability of user engagement. The core computation can be expressed as
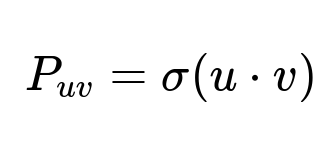
where P_{uv} is the predicted probability of engagement, u is the user embedding, and v is the video embedding. The model then applies the cross-entropy loss to compare P_{uv} with the actual engagement label.
Negative Sampling
In-batch negative sampling improves training efficiency. The system treats each user’s positive video as a positive label while all other user-video pairs in the same batch are negative samples. This provides a broader set of negative pairs and helps the model learn to distinguish which videos are most relevant to each user’s interests.
Offline Embedding Generation
A recurring batch job computes user embeddings by feeding user features into the trained user tower. Another batch job computes video embeddings via the video tower. The jobs run on a schedule to keep embeddings fresh. For user embeddings, the pipeline collects recent user activities and transforms them into the correct input format. For new videos, the pipeline fetches all relevant features from the database and generates updated embeddings to reflect fresh content.
Approximate Nearest Neighbor Index
A Hierarchical Navigable Small World (HNSW) index stores all video embeddings to support large-scale nearest neighbor searches. The offline pipeline builds the index and writes it to cloud storage for serving. The HNSW structure allows sub-millisecond approximate nearest neighbor queries even with millions of videos.
Online Serving
The user profile service holds each user’s embedding. When a device requests new short-video content, the feed processing service fetches the user embedding and sends it to the retrieval service alongside a search request. The retrieval service queries the HNSW index to find nearest video embeddings and returns the top candidates. Those candidates go to a downstream ranking stage for additional fine-tuning. Separating feed processing logic from retrieval service logic provides scalability by allowing each service to scale independently.
Observed Impact
The approach significantly improves watch time and video views. Two-tower retrieval enables real-time personalized video recommendations using dense representations. The system can add new retrieval sources such as user-creator embeddings or user-video embeddings, unify them in a single approximate nearest neighbor retrieval layer, and meet stringent latency requirements.
Example Code Snippet (Two-Tower Model Training)
import tensorflow as tf
class TwoTowerModel(tf.keras.Model):
def __init__(self, embedding_dim=128):
super(TwoTowerModel, self).__init__()
self.user_dense = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(embedding_dim)
])
self.video_dense = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(embedding_dim)
])
def call(self, user_inputs, video_inputs):
user_emb = self.user_dense(user_inputs)
video_emb = self.video_dense(video_inputs)
user_emb = tf.math.l2_normalize(user_emb, axis=1)
video_emb = tf.math.l2_normalize(video_emb, axis=1)
dot_product = tf.reduce_sum(user_emb * video_emb, axis=1, keepdims=True)
logits = dot_product # used with sigmoid for binary cross-entropy
return logits
user_inputs = tf.random.normal((32, 100)) # example batch of user features
video_inputs = tf.random.normal((32, 100)) # example batch of video features
model = TwoTowerModel()
logits = model(user_inputs, video_inputs)
The user_emb and video_emb vectors can be stored for offline use or used on the fly for tasks like nearest neighbor searches.
How would you handle cold-start scenarios for new videos and new users?
New videos lack historical engagement data. The system bootstraps embeddings with available metadata and content signals, such as the creator’s embedding or features extracted from the video itself. New users lack personalized viewing history. The model initializes their embeddings from demographic or regional features. The system refines these embeddings rapidly as soon as the user accumulates enough actions.
How would you justify the two-tower architecture instead of a single-tower approach?
The two-tower architecture simplifies embedding generation by cleanly separating user and video features. Each tower remains independent, enabling batch embedding generation for users and videos. A single-tower approach concatenating user and video features would require direct interaction features for inference, complicating large-scale retrieval. Two-tower embeddings are more manageable to store, retrieve, and index in an approximate nearest neighbor structure.
How does in-batch negative sampling help with scalability and convergence?
In-batch negative sampling reuses video embeddings from all user-positive pairs in the batch to act as negatives for each other. This increases the number of negative examples without additional sampling overhead, speeding convergence. The model quickly learns which user-video interactions are most likely and penalizes mismatches on many negative pairs in each mini-batch.
What strategies reduce serving latency at high request volumes?
The system separates the feed processing service from the retrieval service. This design avoids coupling heavy business logic with the vector search process. HNSW indexes loaded into memory on retrieval servers accelerate nearest neighbor lookups. Embeddings are precomputed offline, limiting on-the-fly computation. Horizontal scaling of retrieval shards handles the largest queries per second.
How would you adapt this system for future enhancements?
Switching to a Transformer-based user tower could capture longer user histories in more detail. Training on larger datasets would encode deeper signals about user interests. Merging multiple retrieval sources into a unified embedding-based pipeline would simplify maintenance and reduce operational overhead. Tracking how embeddings evolve and comparing retrieval performance across versions would guide incremental improvements.