
ML Case-study Interview Question: Robust Rideshare Fraud Detection: Implementing GBDTs/DNNs & Scalable Pipelines.


Browse all the ML Case-Studies here.
Case-Study question
You have a growing rideshare platform that faces sophisticated fraudulent activities. There is an existing rule-based system with a logistic regression model for user-risk classification. In production, the system is monolithic, fragile, and difficult to maintain. Propose how you would design and implement a robust pipeline with stronger classification models (for example, Gradient Boosted Decision Trees and deep neural networks), reliable serialization for production, and flexible infrastructure that allows easy integration of new features.
Detailed Solution
Overview of the Challenge
Fraud detection needs accurate and scalable classification methods. A company once relied on a hand-coded logistic regression model. That model broke in subtle ways because feature definitions were duplicated and frequently mismatched between prototype and production. As fraud schemes grew more advanced, linear models became insufficient. The company needed more expressive models, plus a cleaner prototype-to-production pipeline.
Transition from Simple to More Expressive Models
Logistic regression is interpretable, but it struggles to capture complex interactions without heavy feature engineering. Gradient Boosted Decision Trees (GBDT) capture nonlinear interactions automatically. eXtreme Gradient Boosting (XGBoost) is a popular GBDT implementation. Deep neural networks can consume complex data, such as user behavior sequences, with less manual engineering.
Logistic Regression Formula
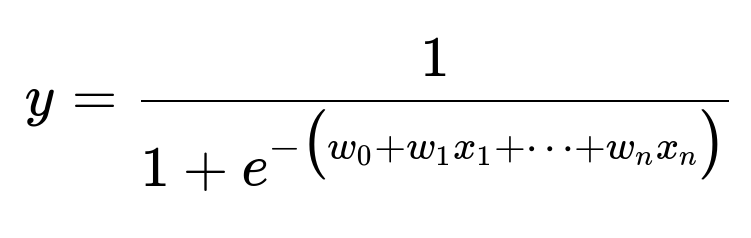
y is the predicted probability of fraud. w_0 ... w_n are learned weights. x_1 ... x_n are feature values. This model linearly combines features, then applies a logistic transform. Nonlinear patterns require additional handcrafted features.
GBDT Conceptual Formula
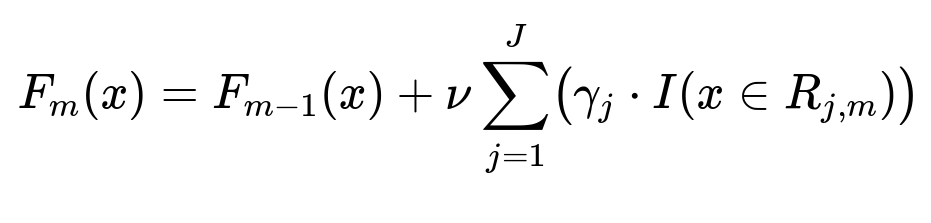
F_m(x) is the boosted model at iteration m. F_{m-1}(x) is the model from the previous iteration, and x is the feature vector. nu is the learning rate. R_{j,m} are the leaf regions for tree m, and gamma_j is the region-specific weight. I(...) is an indicator function. This additive approach creates more expressive boundaries over the feature space.
Serialization and Productionization
Serious production issues arise if models or features are manually coded in a monolithic service. A safer approach is to:
Train the model in an offline environment (for example, Jupyter Notebook environment).
Serialize the trained model. Python’s pickling is standard, but it can cause version conflicts, so container-based approaches often help isolate dependencies.
Deploy the model in a dedicated microservice that loads the model at runtime.
Infrastructure Improvements
Separating feature engineering, model scoring, and business logic is critical. One service can handle feature collection and store raw or partially processed features. Another service can run the serialized model. Results flow to a central decision layer. This modular design reduces friction when adding new features or retraining models on modern frameworks like Tensorflow (a deep learning library).
Example Code Snippet for Model Serialization
import xgboost as xgb
import pickle
# Train model
data = xgb.DMatrix(X_train, label=y_train)
params = {"objective": "binary:logistic", "eta": 0.1, "max_depth": 5}
model = xgb.train(params, data, num_boost_round=100)
# Serialize model
with open("gbdt_model.pkl", "wb") as f:
pickle.dump(model, f)
# In production, load and predict
with open("gbdt_model.pkl", "rb") as f:
production_model = pickle.load(f)
After loading, the production service scores incoming requests with the same feature transformations used during training.
Avoiding Misalignment Between Prototype and Production
Teams must standardize feature definitions. A unified feature library ensures that offline definitions match online code. Automating feature extraction from historical data helps produce consistent training datasets. When a new model is ready, you can trust the same transformation logic in production.
Deep Learning for Sequential Features
Deep neural networks can analyze user activity sequences without excessive manual feature engineering. A typical approach is to embed event histories in vector form, then pass them through recurrent or attention-based layers. This captures context across time. Because this approach depends on specialized frameworks like Tensorflow, containerized deployments are safer than monolithic approaches, ensuring the correct library versions.
Follow-up question 1: How do you handle interpretability when moving from logistic regression to Gradient Boosted Decision Trees?
Many business stakeholders ask why certain users are flagged. Logistic regression has direct coefficients. GBDT is less transparent. You can explain GBDT predictions by checking feature importances (for the entire model) and single-instance explanations (for example, SHAP values). These methods identify which features have the most impact for the model overall or for a particular prediction.
Follow-up question 2: Why not continue with a single monolithic service for feature engineering and model scoring?
A monolith forces the same codebase and library versions for everything. If you upgrade the model library, you might break other parts of the system. A microservice that solely handles model scoring can run isolated dependencies. Another microservice can handle feature engineering. This decoupling simplifies updates and debugging because each service focuses on one responsibility.
Follow-up question 3: What are common pitfalls with pickled models in production?
Pickled models depend heavily on exact environment matches. Different versions of Python or package libraries can break unpickling. Another pitfall is that pickling can open security risks if untrusted sources load the pickle. Using container-based deployment sidesteps version mismatches by shipping the entire environment. Strict access controls limit who can load or modify pickles in production.
Follow-up question 4: How do you evaluate these models in an online fraud-detection system?
You hold out a small fraction of users from your production model to form an experimental group. You measure precision and recall metrics on flagged entities or suspicious activity. You compare the results between old and new models. You also record the business impact (for instance, how many false positives lead to user inconvenience). By rotating or splitting traffic, you can confirm that improvements in offline metrics align with real-world fraud outcomes.
Follow-up question 5: How can container-based model deployment help when new frameworks or deep models need to be tested?
Containers package a consistent environment with the correct software versions and libraries. You can deploy a container with a new deep learning library without forcing the entire system to upgrade. This approach allows side-by-side testing of new frameworks. If the new model outperforms the current one, you gradually migrate traffic to that container. This approach removes friction from dependency mismatches and accelerates iteration on cutting-edge methods.