
ML Case-study Interview Question: Enhancing AI Code Assistant Context with Vector Embedding Retrieval for Large Codebases.


Browse all the ML Case-Studies here.
Case-Study question
A major platform launched an AI coding assistant based on a large language model. The goal was to reduce coding time by offering real-time suggestions. Engineers discovered that contextual information from multiple open files in an integrated development environment increased suggestion acceptance rates by 5 percent. Another enhancement used a fill-in-the-middle approach, leveraging both prefix and suffix code to deliver another 10 percent improvement. How would you design further improvements for this system to boost contextual understanding, scale it for large enterprise codebases, and ensure robust performance metrics?
Detailed Solution
Prompt engineering is the core. A specialized prompt library must gather and prioritize code from the current file, other open files, and relevant documentation. Including partial matches is useful. This ensures the large language model sees wide context.
A fill-in-the-middle (FIM) approach extends context beyond the immediate prefix. The suffix is also crucial. FIM logic tracks a developer’s cursor position. The model learns to predict code in that middle space. This mechanism generates better completions without large latency cost.
Embedding-based retrieval from a vector database is vital for large repositories. Each code snippet is converted into a high-dimensional vector embedding. This embedding captures both syntax and semantics. A snippet in the user’s environment also becomes an embedding. The tool then locates similar code segments by computing similarity scores. Approximate nearest neighbor search supports low-latency lookups even with billions of vectors. A common similarity metric is cosine similarity:
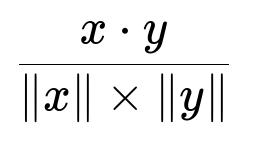
Here, x and y are vector embeddings. The dot product measures component-wise alignment, and the norms measure magnitude.
In practice, the system obtains context by searching for code with similar structure or meaning. This helps produce suggestions that align with the user’s style or domain logic. Enterprise integration might require on-premise hosting of the vector database for data governance. Access control must be enforced so private code remains secure.
Caching partial results is important to keep latency low. Local caches hold recent prompts and embeddings. Models can then avoid recomputing repeated segments.
Performance metrics should measure completion accuracy and developer satisfaction. Acceptance rate measures how often suggestions are accepted. Another metric is latency from request to completion. Tracking function correctness is key. Code coverage and lint checks can measure how reliable suggestions are. Productivity gains can be gauged from time-to-completion analytics.
Versioning is needed for consistent evaluation. As more advanced models appear, A/B tests can track improvements. Fine-tuning or instruction-based approaches help the model adapt to new codebases. Automated test suites can check model outputs against known coding patterns.
How would you handle conflicting contexts across multiple files?
Conflicts can happen when code from different files provides contradictory cues. A scoring mechanism for source relevance helps. The system can weight file references by recency, developer activity, or explicit hints. For example, it can give more weight to files edited within the last few minutes. If there is a mismatch, the model sees the highest-scoring matches first.
A fallback strategy can rely on the single-file context if multi-file references are too contradictory. In practice, the system runs quick scoring steps to rank possible references. The best references feed into the final prompt. This approach balances completeness and precision.
How would you optimize embeddings for domain-specific code?
Pretraining a separate embedding model on domain-specific code is one route. This smaller model can capture niche patterns. If data is scarce, you can adapt an existing foundation model by supervised fine-tuning or contrastive learning on domain-labeled pairs.
Frequent phrases or domain idioms can shape a custom tokenizer. That way, embeddings capture specialized tokens in fewer subwords. Careful hyperparameter tuning controls dimension sizes for better semantic separation. For large enterprise codebases with specialized libraries, adding curated examples yields better generalization. Final performance can be measured by how accurately code search retrieves relevant snippets.
How would you handle model drift and keep suggestions up to date with new libraries?
Adopting a continuous retraining or fine-tuning workflow helps. Periodic ingestion of fresh code updates the embedding model and improves retrieval alignment. Monitoring user feedback and suggestion acceptance rates signals drift. A drop in acceptance might indicate outdated embeddings or incomplete coverage of new APIs.
Regionally caching new libraries is another step. Embeddings for new classes or functions get added to the database. The retrieval service can discover them before older embeddings overshadow them. Alerting the system to new commits or releases triggers re-indexing. This cycle ensures the model remains accurate with changing code patterns.
How would you balance performance and security in an enterprise setting?
Isolating the vector database behind corporate firewalls is vital. This addresses compliance needs and prevents accidental data leaks. Minimizing data sent to external APIs is recommended. On-premise deployment of the retrieval service is also an option, although it might demand extra maintenance.
Performance can be protected by scalable infrastructure. Sharding the vector database or using approximate nearest neighbor search frameworks ensures sub-second retrieval times. Horizontal scaling with load balancing meets demand spikes. Periodic housekeeping tasks remove stale data to keep indexes compact. Observability is essential. Enterprise monitoring tools watch response times and resource usage. When latency climbs, auto-scaling triggers additional instances.
How would you evaluate the model’s ability to understand user intent rather than just syntax?
Semantic tests ask the system to generate code that meets a user story or natural language specification. For instance, “Write a function that merges user data with session logs.” If the code is correct in logic, not just matching variable names, that suggests deeper understanding.
Separate tasks can measure code correctness using test suites. Another measure is how well the model handles synonyms or paraphrases in user prompts. If it can interpret varied instructions similarly, it shows strong semantic understanding. Direct user feedback helps. Surveys or star-ratings on suggestions measure perceived intent alignment.
How do you see the approach evolving as model sizes increase?
Larger models can handle more tokens at once. This allows more code context and better reasoning. But memory and serving costs rise. Vector retrieval remains relevant for pinpointing context in large codebases. Long-context models may not eliminate retrieval steps because code repositories can be enormous.
Hybrid strategies are possible. The model sees an initial chunk of code context. A retrieval module also feeds short embeddings to fill any crucial gaps. This approach combines large context windows with specialized search for rare references. The best path depends on cost constraints, latency requirements, and how effectively the model uses expanded context.
How do you ensure the model suggestions remain relevant to a user’s coding style?
Tracking user acceptance patterns reveals style preferences. If a user repeatedly rejects a certain style, the prompt builder can penalize those patterns. The system can learn consistent naming conventions or indentation from the user’s codebase. This can be an additional input. A style-based fine-tuning process might feed the model user-specific data. Another simpler way is to store user preferences for lint rules. The system can then format generated code to comply with those rules.
Unusual coding styles might require advanced prompts or specialized embeddings. If a user writes purely functional code in a language that often has object-oriented patterns, adjusting the prompt to emphasize functional examples can boost suggestion acceptance.