
ML Case-study Interview Question: Efficient Lookalike Audiences via Compressed Embeddings & Real-Time In-Memory Matching


Browse all the ML Case-Studies here.
Case-Study question
A large aggregator platform wants to improve its advertising system by leveraging lookalike audiences. They face issues with high audience creation cost, slow service level agreement, and delayed user embedding updates. They store and serve embeddings for millions of users in memory. They compress embeddings to reduce memory usage while preserving accuracy. They then perform real-time audience matching via cosine similarity between user and audience embeddings to decide which ads to show. How would you build a data science solution to tackle these problems and deliver more effective campaigns, while meeting strict latency requirements?
Detailed Solution
Creating a scalable lookalike audience pipeline involves embedding-based user representations and an efficient retrieval system. This helps advertisers deliver ads to users whose interests match a given audience. Below is an in-depth breakdown:
Core Embedding Strategy
Train a user embedding model with large-scale historical user actions. Use these embeddings to represent user interests in a continuous vector space. Keep user embedding dimensionality relatively high to capture nuanced behaviors. Store those embeddings in memory for fast reads. When a new custom audience arrives, compute the audience embedding by aggregating embeddings of its known members (for example, by averaging).
Cosine Similarity for Matching
Score each user against a given audience embedding using cosine similarity. Keep a threshold to decide membership. Use this equation:
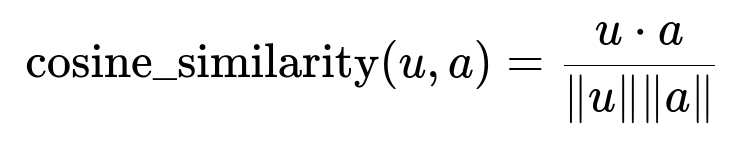
where u is the user embedding, a is the audience embedding, u dot a is the dot product, and |u|, |a| are the Euclidean magnitudes of the vectors.
Users with cosine similarity above the threshold are considered part of the lookalike audience. This step quickly checks membership in real time. Fine-tune the threshold to control precision and recall.
In-Memory Retrieval Service
Store user embeddings and the audience embeddings in an in-memory system. This avoids external lookups, achieving low-latency responses. Partition memory across multiple servers if necessary. Keep track of model versioning to handle updates gracefully.
Embedding Compression Method
The aggregator platform deals with massive numbers of user embeddings. To store them all in memory, compress each high-dimensional user embedding. Use a hashing trick: each user ID is processed by hash functions that map it into smaller embedding blocks.
For example, split a hash64(user_id) into four 16-bit segments, each indexing a 16-dimensional embedding block. Concatenate these blocks to form a compressed embedding. Train these compressed embeddings to approximate the original ones by minimizing mean squared error between them. This reduces memory footprint by about 90%. Adjust the number of hash functions or blocks to balance storage savings and accuracy.
Data Pipeline and Audience Creation
A daily or frequent batch job fetches new custom audiences from a queue. This job computes each audience embedding. It updates the thresholds. It pushes new embeddings into the serving layer. The serving system then uses these updated embeddings and thresholds for real-time lookups.
Example Code Snippet
Below shows a high-level Python-like example for generating audience embeddings:
def generate_audience_embedding(user_ids, user_embedding_map):
sum_embedding = np.zeros(embedding_dim)
count = 0
for uid in user_ids:
sum_embedding += user_embedding_map[uid]
count += 1
avg_embedding = sum_embedding / count
return avg_embedding
def store_audience_embedding(audience_id, avg_embedding, threshold, model_storage):
model_storage[audience_id] = {
'embedding': avg_embedding,
'threshold': threshold
}
This snippet retrieves user embeddings, averages them, then stores the result with a threshold.
Updating Frequencies
Frequent updates prevent stale audiences. Schedule partial re-training or incremental updates of user embeddings if user behaviors shift significantly. Update audience embeddings as soon as advertisers create new audiences.
Cost Optimizations
Share user embeddings across multiple use-cases to avoid duplicative training costs. Store only compressed embeddings for real-time retrieval. Keep audience embeddings small (single vector plus threshold). This drastically reduces memory overhead.
Follow-up Question 1
How do you deal with representation drift or data shifts over time?
Answer
Monitor user behavior changes. Retrain user embeddings on up-to-date data. Maintain a pipeline that incrementally retrains on new actions. Update embeddings at a frequency depending on data volatility and resources. Validate drift by tracking key performance indicators such as click-through rate or conversion rate. If metrics degrade significantly, initiate earlier re-training or threshold readjustment.
Follow-up Question 2
What if the user embedding dimensionality is still too large for in-memory storage, even after compression?
Answer
Partition users across multiple memory-based retrieval nodes. Assign each node a subset of user embeddings. Place a load balancer or routing layer in front that directs queries to the right node. Use additional hashing or sharding strategies if user distribution is skewed. Consider advanced compression: additional hash functions, product quantization, or dimension reduction techniques. Balance retrieval speed with potential small losses in accuracy.
Follow-up Question 3
How would you evaluate the performance of this system in an A/B test?
Answer
Randomly split users or traffic into control (old system) and treatment (new system). Maintain identical ad campaigns and measure impressions, clicks, click-through rate, and conversion rate. Track cost metrics to see if the new pipeline reduces computing expenses. Conduct statistical significance tests (for example, p-values on CTR lift). Confirm that improvements in clicks or conversions are not due to random variance. If positive, gradually roll out to more traffic.
Follow-up Question 4
Could adversaries manipulate the embeddings to get more impressions?
Answer
They might attempt to inject synthetic user actions that distort embeddings. Mitigate by detecting anomalous activity, such as sudden spikes in behavior or improbable usage patterns. Use robust training procedures, input validation, and anomaly detection at ingestion time. Keep watch for suspicious embeddings that deviate drastically from typical embedding distributions.
Follow-up Question 5
How would you choose an initial threshold for cosine similarity?
Answer
Run offline experiments to evaluate different threshold values. For each threshold, compute precision and recall relative to known audience labels. Select the threshold that yields acceptable coverage and accuracy. A typical approach is to pick a threshold that balances false positives and false negatives in an ROC or precision-recall curve. Calibrate it further with small-scale online tests to confirm real-world performance.
Follow-up Question 6
How can you extend this system to support multiple embedding types (for example, merchant or driver embeddings)?
Answer
Design a flexible architecture that can handle various entity embeddings stored in memory. Introduce a metadata layer that maps entity types to the correct embedding space. If you need cross-entity comparisons, unify them in a shared latent space or train a multi-task model that aligns embeddings. Keep separate thresholds per entity type if you measure similarity differently for each domain.
Follow-up Question 7
How do you ensure minimal latency during real-time retrieval?
Answer
Preload user and audience embeddings in RAM. Avoid network calls to external databases. Use efficient approximate nearest neighbor structures if the dataset is too large for direct in-memory matching. Optimize the lookups with concurrency or vectorized libraries. Watch garbage collection and memory fragmentation. Scale out horizontally if your query volume spikes.
Follow-up Question 8
What pitfalls might arise if you set the user embedding to be too generic?
Answer
It may not capture niche or evolving preferences. Overly generic embeddings might mix up different behaviors, leading to less personalized recommendations. This can degrade the system's overall precision. Monitor business metrics (CTR, conversions) to see if the embedding coverage is too broad. Reintroduce specialized embeddings for distinct segments if needed.
Follow-up Question 9
How do you keep the model backward-compatible when you upgrade embeddings or thresholds?
Answer
Version your embeddings and store them with timestamps. Introduce a new model version in parallel. Let a small traffic slice test it. If metrics are stable or improved, migrate users over. Handle any newly computed thresholds on the new version. Provide fallback to old embeddings for a short period if issues surface. This staged rollout preserves stability.
Follow-up Question 10
What if your offline evaluation shows high accuracy, but real-world campaigns yield poor returns?
Answer
Check for mismatch between offline metrics and actual ad performance. Investigate training data biases or data leakage. Verify that the offline user actions align with your real user interactions. Conduct small live tests to validate embedding quality. Retrain or fine-tune if the distribution of live user actions differs from historical data. Reevaluate threshold settings or consider domain-specific features that might be missing in the embedding model.