
ML Case-study Interview Question: Hybrid Sequence Models & Rules for Scalable Automated Grammar Correction


Browse all the ML Case-Studies here.
Case-Study question
A major platform needs to build and scale an automated grammatical error correction system for millions of daily active users. The system must return error-free text suggestions for any grammatical, spelling, or punctuation mistakes. The challenge is to balance precision and recall while also incorporating context-aware and personalized corrections. The platform wants a robust solution that uses multiple models, maintains real-time performance, and quickly iterates on user feedback. Propose a strategy to design this system, measure its quality, and ensure it remains reliable and adaptable to changing language usage over time.
Proposed Solution
Understanding the Problem
Users submit text that often contains grammar, spelling, and punctuation mistakes. The solution must detect the errors, propose valid corrections, and maintain context awareness. There are multiple valid ways to correct a sentence, and each suggestion might subtly alter the sentence’s meaning. High recall means catching more mistakes; high precision means minimizing incorrect suggestions.
Measuring Quality
Evaluation focuses on precision and recall. These metrics are central to measuring accuracy in detecting and correcting errors:
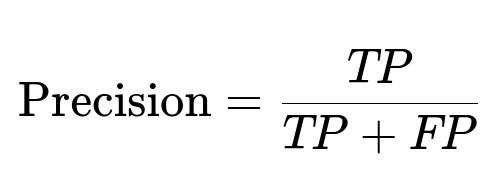
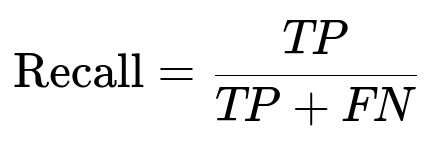
TP stands for true positives (correct corrections), FP for false positives (wrong corrections), and FN for missed corrections. Balancing them is crucial. Additional user engagement data, like accept/dismiss actions and user ratings, refines system performance.
System Components
A hybrid approach can be used:
Sequence-to-sequence rewriting with a transformer-based model. It rewrites the entire sentence in one step.
Sequence tagging. It pinpoints each error token by token. This fine-grained insight complements the full-sentence rewrite.
Pattern-based rules. Handcrafted syntax-based checks detect common issues quickly. These rules are frequently updated.
Combining these components yields better context and granular control. The large-scale transformer model captures global context, the tagging model enforces local correctness, and pattern-based rules handle straightforward mistakes and respond fast to user feedback.
Practical Details
High-volume traffic requires efficient deployment strategies. Model distillation, ensembling, caching, and on-device inference options can reduce latency and resource use. Linguist-expert input refines pattern-based rules and custom data labeling. Online experimentation validates updates. User feedback triggers fast rollouts of new rules or model adjustments.
Example Pseudocode for Sequence Tagging
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("your-sequence-tagger")
model = AutoModelForTokenClassification.from_pretrained("your-sequence-tagger")
def sequence_tag_correction(text):
inputs = tokenizer.encode_plus(text, return_tensors='pt')
outputs = model(**inputs)
# Retrieve predicted tags
predictions = torch.argmax(outputs.logits, dim=-1)
# Convert tags to actual corrected tokens
corrected_text = apply_tags(text, predictions)
return corrected_text
def apply_tags(original_text, tag_predictions):
# Replace or modify tokens according to predicted tags
# Return corrected text
pass
Potential Personalization
User preferences on stylistic choices or repeated mistakes get tracked to tailor suggestions. This ensures the system remains flexible across formal or casual writing styles. Personalization data might include frequently accepted suggestions, leading to user-specific patterns that refine outputs.
Follow-Up Question 1
How would you handle instances where the language is changing rapidly, or new slang or jargon appears?
Answer
Collect new usage patterns by constantly sampling real user text (with privacy controls). Build incremental training sets with newly emerging terms. Update lexical dictionaries and pattern-based rules. Fine-tune models on fresh data regularly. Introduce fallback mechanisms for unfamiliar tokens. Repeated user dismissals of particular corrections signal the need to adapt. Rolling model updates or lightweight rule expansions keep the system aligned with current language trends.
Follow-Up Question 2
How do you prevent the sequence-to-sequence model from making overly aggressive rewrites that change the intended meaning?
Answer
Use a multi-system approach that includes a tagging model to constrain global rewrites. Assign confidence scores to the sequence-to-sequence output. If the rewrite suggests major meaning shifts, the model defers to local corrections or notifies the user with multiple suggestions. Maintain a threshold-based gating mechanism that prioritizes conservative corrections when confidence is uncertain. Track user feedback to identify patterns of overcorrection and retrain or adjust thresholds accordingly.
Follow-Up Question 3
How do you speed up inference for a large model under high-traffic conditions?
Answer
Use techniques like model compression and quantization to reduce memory usage. Apply distillation to create smaller student models that preserve performance of the large teacher model. Cache common queries. Implement batch processing when feasible. Distribute load across clusters with a load balancer. For some frequent requests, store partial outputs or adopt edge device inference. Profile latency bottlenecks and optimize code paths at the framework and hardware levels.
Follow-Up Question 4
If a user frequently rejects certain grammar corrections, how do you incorporate this feedback back into the system?
Answer
Record user actions (acceptances, rejections, dismissals) and track them in a feedback dataset. For consistent rejections in specific contexts, update pattern-based rules or fine-tune the relevant model. Personalization profiles store these preferences at user-level or user-segment level. Gradually adapt suggestions to align with user choices. Retraining schedules can include explicit weighting for user feedback data, ensuring the system learns from such patterns.
Follow-Up Question 5
What would you do if your model sometimes suggests correct grammar but incorrect domain-specific usage?
Answer
Detect domain context by analyzing specialized vocabulary or topic references. If detected, apply domain-specific rules or a domain-tuned sub-model. Maintain curated sets of domain terms or specialized collocations. If the text belongs to a recognized domain, override generic grammar rules with the domain’s style guidelines. Continuous feedback from domain experts refines these rules or domain-specific language models.
Follow-Up Question 6
How would you ensure that suggested corrections don’t break the user’s original text formatting, such as preserving line breaks or special tokens?
Answer
Partition text into segments, preserving layout markup and spacing. Process each segment for corrections but reconstruct them within the original format. For advanced documents, parse with a structured format (for example, an HTML parser if text is from a webpage), store style data, correct only the text nodes, and re-inject them at the same positions. Maintain robust tests ensuring that the final output replicates all the original layout properties except for the corrected tokens.
Follow-Up Question 7
What if the user’s text includes code snippets or unusual symbols that are not typical linguistic content?
Answer
Detect code blocks or markup by scanning for delimiters (like triple backticks or angle brackets). Bypass grammar models for those blocks or apply specialized code-aware rules. For unusual symbols, apply normalization pipelines that respect known symbols but do not attempt grammar corrections on them. If the snippet partially overlaps with normal text, process only the textual parts carefully, ignoring the code fragments.
Follow-Up Question 8
What lessons do you draw from combining multiple models (seq2seq, tagger, rule-based) in production, and how do you evaluate trade-offs?
Answer
Each model has strengths. The seq2seq approach captures global context, but it can overcorrect. The tagger model enforces localized edits, but it might miss broader sentence issues. Rule-based checks are fast but limited by coverage. Combining them balances coverage and precision. Evaluate ensemble performance on representative test sets and track real-world feedback. Run A/B tests, measure acceptance rates and user satisfaction. Adjust weighting or priority for each approach if feedback shows one approach is underperforming or overcorrecting.
Follow-Up Question 9
How do you measure success beyond standard precision and recall metrics?
Answer
Track long-term user engagement with corrections, rates of acceptance vs. dismissal, and user satisfaction scores. Observe how suggestions affect final text quality. Collect semantic similarity data to see if meaning remains intact. Analyze the average time saved or stress reduced for users. These richer metrics supplement precision and recall and give actionable insights into user experience.
Follow-Up Question 10
How do you handle edge cases where grammar rules are subjective or under debate?
Answer
Maintain a configuration that defaults to widely accepted grammar standards. Log controversies (like optional Oxford commas) to either skip or offer multiple suggestions. Allow user or organizational preferences to override defaults. Evaluate dismissals to see if a majority of users reject a contentious rule. Periodic reviews by linguists keep suggestions aligned with evolving usage.
Follow-Up Question 11
Could you summarize how you would ensure the system remains adaptable, accurate, and user-friendly at scale?
Answer
Adopt continuous evaluation with fresh labeled data and user feedback. Retrain or fine-tune models periodically. Use a robust architecture that combines large-scale seq2seq rewriting, local tagging, and curated pattern-based rules. Implement thorough monitoring of latency, memory usage, and acceptance rates. Introduce personalization features that capture user styles. Regularly incorporate new slang, domain jargon, and grammar standards, ensuring the system stays current while delivering correct, fast, and user-friendly text corrections.