
ML Case-study Interview Question: Developing Specialized Code LLMs: Data, Context, Fine-Tuning, Benchmarking, and Safety.


Browse all the ML Case-Studies here.
Case-Study question
You are given a scenario where a large technology organization wants to create an open-source specialized language model to generate and interpret code. They train several model sizes (7B, 13B, 34B, and 70B parameters) on large corpuses of code. These models can handle diverse tasks, including code completion, debugging, and generating detailed explanations. They plan to release different variants specialized for Python and for following natural language instructions. They also want to benchmark these models on popular coding benchmarks like HumanEval and MBPP, and compare performance against other open-source and proprietary models. Propose how you would design, develop, and evaluate a solution that meets these objectives. Specifically address:
How to choose training data sources for code.
How to ensure the model can handle large context lengths (up to 100,000 tokens).
How to provide specialized variants (Python-specific and instruction-tuned).
How to benchmark using HumanEval and MBPP while analyzing limitations or safety concerns.
How to plan red-teaming to mitigate risks of malicious code generation.
How to handle performance trade-offs across model sizes.
Explain your approach, focusing on architectural choices, data preprocessing strategies, fine-tuning methods, safety measures, and practical deployment considerations for real-time code completion.
Detailed In-Depth Solution
Begin by collecting datasets from public code repositories. Remove data with ambiguous licensing or unsafe content to limit legal or security issues. Ensure balanced coverage of languages like Python, C++, Java, and more. Split data into training and validation sets to systematically monitor overfitting. Filter out large binary files and duplicated snippets to maintain data quality.
Pre-train a base model on a broad mix of source code. Extend context window capability by using position interpolation or modified attention mechanisms, so it can handle context up to 100,000 tokens. This allows deeper code analysis and debugging of large files. Implement model parallelism or tensor parallelism for 34B and 70B models. Adjust hyperparameters and optimize memory usage.
Fine-tune specialized variants. For Python, sample more Python code from your dataset. For instruction-tuning, provide natural language instructions paired with correct code outputs. Retrain with a specialized objective that emphasizes alignment with user prompts. This helps the model handle queries like “Explain how this function works” or “Optimize this snippet.”
Use coding benchmarks like HumanEval and MBPP. HumanEval tests code completion quality based on docstrings. MBPP assesses broader problem-solving. Compare results across open-source and proprietary models to gauge competitiveness. Monitor pass rates at multiple top-k levels.
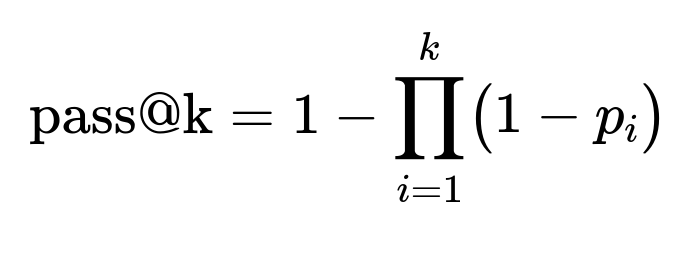
Where p_i is the probability that the i-th sample passes the test suite. This measures how likely the model is to produce a correct solution within k attempts.
Apply rigorous red-teaming. Prompt the model for malicious or unsafe code. Track responses using internal guidelines. Retrain or refine policies if outputs reveal vulnerabilities or harmful patterns. For example, mask or block direct instructions for writing malware. Maintain usage logs to detect potential misuse.
Deploy smaller models (7B or 13B) for low-latency code completion. Provide 34B and 70B models for complex tasks like multi-file debugging or code generation with larger context. Offer inference endpoints with scalable GPU setups. For real-time completion, slice user code to ensure the model sees relevant context. Return stepwise completions to avoid repeated re-generation.
Choose robust inference frameworks. Cache partial computations for speed. Handle concurrency with queue-based request management. Use guardrails to block PII or harmful code. Provide disclaimers about correctness and security. Collect user feedback to refine prompts and overall model performance.
Potential Follow-Up Questions
1. How would you handle the risk of the model generating copyrighted snippets?
Explain how you would identify and mitigate potential violations. Discuss data filtering, compliance checks, and usage licenses.
Answer and Explanation Train on code with clear open-source or permissive licenses. Use automated filters that remove exact copies of large blocks of text from restricted licenses. Maintain an internal database of known restricted code. If your model accidentally regenerates long copyrighted snippets, add a rule-based system to identify large verbatim passages. When such passages appear, truncate the model response or provide an alert to the user.
2. How would you ensure domain adaptation for specific coding environments or libraries?
Discuss dataset augmentation, domain-targeted prompts, or additional fine-tuning.
Answer and Explanation Gather specialized code examples from relevant repositories. Fine-tune your model again using these domain-specific snippets. Focus on the libraries or frameworks you want to cover (for example, specialized data-processing libraries). Offer system prompts describing environment setup, library versions, and typical usage patterns. Combine standard and domain-focused data so the model learns general syntax plus specialized APIs.
3. How would you optimize inference speeds while using large models?
Discuss techniques to reduce latency, GPU parallelization, and memory optimization.
Answer and Explanation Use quantization (e.g., 8-bit or 4-bit weights) to reduce model size in memory. Apply tensor or pipeline parallelism to spread computation across multiple GPUs. Cache the attention key-value pairs during sequential token generation, so each new token only requires incremental computation. Prune extraneous layers or use layer dropping if response accuracy remains acceptable. Explore compilation optimizations like TorchScript or custom CUDA kernels.
4. What is your approach to handle ambiguous prompts or partial code?
Discuss the methodology for dealing with uncertain instructions or incomplete user input.
Answer and Explanation Train with fill-in-the-middle tasks. Let the model handle partial code blocks by inserting code in the middle. If the user prompt is ambiguous, generate clarifying questions or disclaimers. For instance, “It seems you have not specified how the function should handle edge cases. Do you want me to assume default behavior?” Align the model’s instruct variant to always clarify or ask questions rather than produce uncertain or incorrect outputs.
5. How do you address safety and alignment in code generation models to prevent harmful outputs?
Discuss your alignment framework and your method for addressing malicious queries.
Answer and Explanation Use an instruction-tuned variant with explicit moral and legal constraints. Prompt the model with a content policy that forbids direct help with harmful activities. Red-team extensively by requesting malicious code generation. Log and categorize those prompts. Retrain or adjust refusal strategies when the model fails to comply. Deploy a gating layer that analyzes the request for suspicious patterns before it reaches the model.