
ML Case-study Interview Question: Deep Multi-Task Learning for Robust Detection of Evolving Fraud Types


Browse all the ML Case-Studies here.
Case-Study question
A large online payment platform faces multiple fraud patterns across different transaction flows, including stolen identities, unauthorized account access, and fraudulent financial instruments. Each pattern arises from overlapping tactics used by fraudsters, but some differences exist depending on the sub-population or transaction type. The platform wants one deep neural network to learn these fraud types simultaneously, maintain high detection accuracy, and keep false positives low by approving good users swiftly. The platform also expects sporadic changes in data distribution over time. Propose a machine learning solution strategy. Explain how you would handle multi-task learning across various fraud subtypes, use robust representation learning to manage distribution shifts, and ensure accurate real-time detection. Outline architecture choices, data requirements, training pipelines, model evaluation strategy, and a plan for online updates.
Provide your approach in detail, focusing on:
Multi-task learning framework to detect multiple fraud patterns at once
Mechanisms to mitigate negative transfer between sub-populations
Methods to ensure robust feature learning under temporal shifts
Steps to maintain high fraud catch rate and reduce declines of legitimate users
Detailed Solution
Multi-Task Learning Architecture
Simultaneous learning of multiple fraud subtypes involves shared and task-specific layers. Hard parameter sharing keeps a common backbone for feature extraction, then branches into separate layers for each fraud subtype. This setup reduces overfitting while letting each subtype have its own specialized output.
Cross-stitch units mix activation maps from different tasks. Each cross-stitch unit learns how to combine shared representations and maintain task-specific paths. The hyperparameter alpha controls the degree of overlap in those representations.
The training process begins by shallow training each task-specific branch on its data slice. This initialization is then used in a joint optimization phase where cross-stitch units retrain weights to find the right balance between shared and individual representations.
Key Mathematical Regularization
Tasks that are closely related often benefit from penalizing large deviations of each task’s parameter vector from their mean. This avoids one task dominating. The penalty constraint enforces a soft clustering of parameter vectors around their average.
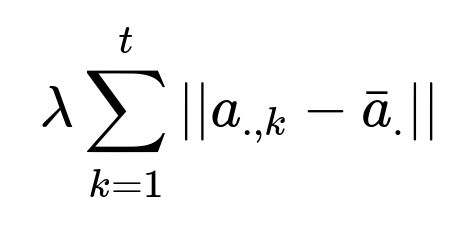
Here, a_{.,k} represents the parameter vector for the k-th task, and bar{a}_{.} represents the mean parameter vector across tasks. lambda controls how strongly we push tasks to stay close to the mean. This helps handle tasks with smaller sample sizes or higher imbalance.
Robust Representation Learning
A robust feature set helps retain performance when data shifts. Training a denoising autoencoder on corrupted versions of the input data forces the hidden layers to discover stable features. Higher weight is placed on corrupted features during reconstruction so the model prioritizes learning robust encodings. These learned feature representations then feed the multi-task supervised model. This pipeline helps the system stay resilient even if some features become missing, noisy, or have changed distributions in production.
Handling Temporality and Shifting Fraud Patterns
Rolling-window training updates the model with new fraud samples in increments. A near-term window detects emerging attacks, while a long-term window captures stable patterns. Joint optimization on historical data preserves crucial fraud signals that are infrequent but high-impact. Online updates enable incremental retraining or fine-tuning as distribution shifts are detected.
Reducing False Positives
A second-stage approach can target good-user approvals. Techniques such as online hard example mining identify borderline cases frequently misclassified. These borderline good-user instances are retrained with extra weight to reduce declines. Generative models trained on genuine user features can also refine thresholds or produce synthetic examples that help the system learn boundary regions between fraud and legitimate transactions.
Practical Implementation
Short intervals for model retraining or fine-tuning keep the model current with new fraud tactics. Scheduled hyperparameter tuning checks maintain a good balance between fast adaptation and stable convergence. Logging and analytics pipelines monitor recall, precision, and true positive rates for each fraud subtype. Large-scale distributed training is advisable for high-volume data.
Evaluation Strategy
Separate holdout sets for each subtype measure recall, precision, and false-positive rate. A combined metric, such as a weighted average of recall across tasks, checks the global fraud-catch capability. Real-time pilot tests confirm the model’s online performance. The final acceptance occurs if the combined fraud-catch rate meets the thresholds while not harming good-user experience.
How would you select a rolling-window size for training?
A smaller window quickly adapts to emerging attacks but risks underrepresenting older patterns. A larger window retains older signals but might lag in adjusting to new fraud. Balance both by tuning the window size on validation sets, measuring recall for brand-new fraud patterns versus older ones. In practice, a combination of short and long windows is integrated. A short window informs the immediate model shift, while a long window helps preserve stable patterns.
How would you mitigate negative transfer if one fraud subtype is very different from the others?
Testing that subtype in isolation checks if multi-task sharing hurts its performance. If performance degrades, cross-stitch alpha values or partial architecture constraints can limit how much that subtype’s parameters share with the rest. Adjusting the penalty weight lambda in the multi-task regularization further loosens that subtype’s closeness constraint to the mean parameter vector.
How would you handle real-time production scoring?
A typical approach is exporting the trained model to a low-latency serving system. Depending on the scale, distributed in-memory serving frameworks or specialized hardware might be used. Feature engineering pipelines must run in real-time so features match training distributions. A stream-based or event-driven system ensures minimal scoring lag. Regular audits compare online features and offline training features to prevent skew.
How would you choose thresholds for deciding fraud versus good transactions?
Offline experiments compute a receiver operating characteristic curve or precision-recall curve for each task. A business-driven cost function chooses the threshold. High fraud-catch priority leads to a lower threshold. High user experience priority leads to a higher threshold. Real-time performance is tracked with an adaptive threshold based on business metrics (for example, financial loss targets vs. user satisfaction metrics).
How would you address missing or delayed feature data?
Fallback strategies can fill missing features with domain-informed defaults or a learned embedding from the denoising autoencoder. Time-stamping each feature ensures the system knows how fresh the data is. When features are systematically delayed, partial scoring might be needed, then updated once the data arrives. Monitoring pipelines help detect feature drift early so the model can retrain or recalibrate.
Why use cross-stitch units instead of simpler multi-task sharing?
Cross-stitch units let each task learn which other tasks are most similar. A simpler approach might force the same representation for all tasks or specify a small set of shared layers. Cross-stitch allows more granularity in controlling how shared or separate the representations become. This improves performance when tasks share partial but not total similarity.
How would you integrate online hard example mining?
Ranking samples by their loss identifies the hardest examples. Those with high loss are fed into an extra training pass or assigned higher weighting in the loss function. This approach focuses the model on cases it finds confusing, which can be genuine fraud attempts that are subtle or legitimate transactions that appear suspicious. Implementation requires a pipeline to record recent examples, compute losses, sort them, and feed them back into the training loop.
How would you confirm the model’s robustness when certain features break?
Testing with synthetic corruption replicates partial outages or anomalies. Denoising autoencoders help the model recover from partial feature sets. System-level validation checks also forcibly drop critical features or random subsets. If performance degrades minimally, the system can handle real-world feature distribution changes.
How do you ensure quick updates for new fraud tactics?
Live data pipelines monitor anomaly scores and distributional metrics. When spikes occur, a short incremental retraining triggers, or the system flags suspicious patterns for an investigative team. This feedback loop helps the multi-task model incorporate new subtypes or variations. Fine-tuning with new labeled data keeps the model agile.
How would you handle model interpretability or compliance?
Certain financial industries need explanations of automated decisions. Techniques like Integrated Gradients or SHAP can identify which features contributed to the final score. This reveals how the multi-task network weighs user, transaction, and network-level patterns. If domain or regulatory requirements demand simpler interpretable models, you can keep a fallback logistic regression or random forest to confirm high-risk decisions.