
ML Case-study Interview Question: E-commerce ML Pipeline: Real-Time User Preference Prediction and Anomaly Detection


Browse all the ML Case-Studies here.
Case-Study question
You have a large e-commerce platform with diverse user behaviors across multiple product categories. You want to build a Machine Learning pipeline that analyzes user interaction data (search queries, click-throughs, purchases) to predict user preferences in real time. You also want an automated alert system that flags possible anomalies (fraudulent behaviors or sudden drops in user engagement). Suggest a complete solution, including data ingestion architecture, model training, real-time scoring, and anomaly detection, without naming any specific company. Propose approaches to handle large-scale streaming data, incorporate multi-modal features, maintain low-latency predictions, and ensure model monitoring. Outline all key steps and potential challenges. Provide enough detail so the leadership team can evaluate feasibility.
Detailed Solution
Data ingestion involves collecting interaction logs from mobile apps, web clients, and partner feeds. A message queue system can buffer incoming events and send them to a distributed cluster. A specialized streaming framework can process incoming data and store it in a columnar store for analytical queries. A second real-time pipeline can feed data to an online inference service.
Model training uses a two-step approach. First, process historical data in a batch job to compute global statistics, embeddings, and label generation. Then train a ranking model on the aggregated data. The model can be a gradient boosting system or a neural network. The embeddings can capture user profile, product attributes, and time-based contextual signals. For the real-time part, keep a small sliding window of the latest user interactions. The aggregator merges new user features with historical profiles. The real-time scoring service consumes these merged features to serve predictions at request time.
Anomaly detection uses an unsupervised approach on aggregated metrics and user behavior vectors. Compare new vectors with historical distribution. Detect outliers using local density estimation or clustering-based methods. If unusual deviation appears, trigger alerts. Maintain a separate pipeline for anomaly scoring, because it must handle large streaming volumes with minimal delay.
Architecture Overview
Data arrives as raw logs. A cluster performs feature extraction. Store key features in a fast-access data store. Real-time requests ping the scoring service with user IDs and the relevant context. The scoring service fetches user vectors and product vectors from memory, combines them, and runs inference with the trained model. The pipeline logs each decision for retraining.
Example Code Snippet
Below is a simplified illustration of the online inference flow in Python:
import time
class RealTimeScoringService:
def __init__(self, model, feature_store):
self.model = model
self.feature_store = feature_store
def predict_score(self, user_id, product_id):
user_features = self.feature_store.get_user_vector(user_id)
product_features = self.feature_store.get_product_vector(product_id)
combined = user_features + product_features # Vector concatenation
score = self.model.predict([combined])[0]
return score
def process_request(self, user_id, product_id):
start_time = time.time()
score = self.predict_score(user_id, product_id)
end_time = time.time()
latency = end_time - start_time
return score, latency
This code fetches features from a central store, concatenates them, and calls a loaded model for scoring. The returned score can be used for ranking products or detecting anomalies.
Mathematical Foundation for Online Model Updates
Keeping a dynamic estimate of user preference benefits from iterative updates. An example is the incremental update rule for a Q-value estimate:
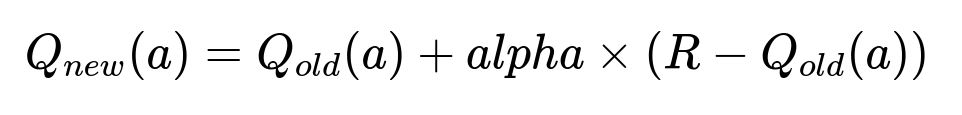
Where:
Q_{old}(a)is the previous estimate for action a.Q_{new}(a)is the updated estimate for action a.alphais the learning rate.Ris the observed reward or signal for action a.
This approach updates preference estimates as soon as new data arrives. In a real-time recommendation service, R might represent click, purchase, or other engagement signals. The iterative rule uses a partial step (controlled by alpha) to incorporate new information while retaining prior knowledge.
Potential Challenges
Model drift occurs if user preferences shift abruptly. Retrain models frequently or implement incremental learning. Feature skew can happen if offline and online data do not match. Ensure consistency in the feature extraction code. Low-latency requirements demand efficient serving infrastructure. Anomaly detection must handle potentially high false-positive rates; calibrate thresholds and set up human review for critical alerts.
Potential Follow-Up Questions
How do you ensure that your pipeline remains robust under sudden traffic spikes?
Scale the ingestion layer by deploying more message queue instances that can absorb bursty load. Autoscale the streaming framework so it can spin up additional executors. Keep a buffer to reduce backpressure if the downstream system slows. Log slowdowns, and raise alerts if the consumption rate lags. Implement stateless microservices with low overhead so they can be replicated quickly under high load.
How do you handle delayed or missing data in your real-time features?
Include timestamp fields in all events. Use windows that allow some margin for late-arriving records. If a record arrives late, adjust the user profile incrementally. Maintain a short time buffer in the streaming pipeline to wait for straggling events. If critical feature data is missing, backfill from a persistent store. If the data is irrecoverably lost, mark features as null and compute a fallback path (such as a global default).
How do you monitor concept drift?
Monitor performance metrics over time (precision, recall, or business KPIs). Compare recent data distributions with historical baselines. If user behaviors or product interactions shift significantly, measure the divergence (such as population stability index). If the drift crosses a threshold, retrain the model. Automate this with a scheduling system or a specialized drift detection algorithm.
How do you optimize hyperparameters at scale?
Distribute hyperparameter search using a framework that can run parallel trials on a large cluster. Early stopping avoids wasted computations. Use random search or Bayesian optimization to explore the parameter space. Capture best-performing hyperparameters in a model registry. Retrain final models on the full dataset and log metrics for reproducibility.
How do you ensure low latency for inference under heavy load?
Host the trained model in a microservice that runs on optimized hardware. Pre-load the model into memory. Cache frequently accessed feature vectors in memory-based stores. Use asynchronous I/O to reduce blocking. Employ load balancers that distribute requests across multiple model-serving instances. If needed, accelerate inference with GPU or specialized hardware.
All these practices uphold performance, reliability, and adaptability in a high-throughput environment.