
ML Case-study Interview Question: Optimizing Large-Scale Ad Conversions with MTL, Sequence Modeling, and Ensemble Serving


Browse all the ML Case-Studies here.
Case-Study question
A large-scale online platform wants to improve its conversion-based ad ranking system. They face sparse and delayed labels for conversion events, noise from advertiser data, and the need to accommodate billions of content items for hundreds of millions of users every month. The goal is to create a robust, scalable model to optimize for specific conversion actions. Propose an end-to-end solution covering data pipelines, multi-task learning for sparse labels, user sequence modeling for personalization, in-model ensemble methods, and GPU-based serving for low latency at scale. Include practical details of your modeling approach, infrastructure trade-offs, and any relevant system design considerations.
In-depth Solution
Overview of Approach
Modeling for conversion optimization demands handling label noise, label sparsity, and delayed feedback. Focus on building a pipeline that reliably handles data issues, a model architecture that learns from multiple signals, and an inference environment that can support large-scale traffic. Combine multi-task learning to share knowledge across objectives, sequence modeling to capture user interests over time, and an in-model ensemble of advanced feature interaction modules. Serve the final model on GPUs to keep latency and infrastructure costs in check.
Data Pipeline and Label Handling
Train the model on user actions such as clicks, add-to-cart, and checkout. Gather these signals from advertiser platforms, ensuring probabilistic matching of conversions to users. This process introduces inaccuracies, so detect and mitigate outliers. Use a data transformation layer that normalizes and filters abnormal signals. Perform random sampling for training, but ensure enough positive labels. Monitor the time lag from click or view to conversion to address delayed feedback. Produce balanced examples with an emphasis on high-quality labels.
Multi-Task Learning (MTL)
Share representations across multiple objectives, such as clicks, add-to-cart, and final checkout. Model architecture includes shared bottom layers for feature extraction, then separate task-specific towers for each objective. This setup injects more training signals into sparse conversion tasks. The system quickly learns general user intent from abundant signals (like clicks) and refines deeper layers for rarer conversions.
In-Model Ensemble
Combine different feature interaction backbones in a single model. Examples include cross networks and transformer-based self-attention modules. Train them jointly, then fuse their outputs at inference. Build a shared bottom for embedding and basic processing, then branch into separate modules. Each module sees the same feature set but encodes interactions differently. Blend the predictions from each module to get a final output score. Calibrate final probabilities carefully.
User Sequence Modeling
Represent historical user activity with a sequence model. Capture temporal patterns and personal interests over a longer lookback window. Feed the sequence (e.g., user’s prior ad clicks or site events) into a transformer or MaskNet block to learn user intent shifts. Temporally closer actions get more weight, reflecting recent interests. This user representation merges with other features (ad features, context features) before the final scoring layer.
GPU-Based Serving
Serve large models on GPU to maintain sub-hundred-millisecond inference. Export the trained model in a graph-safe manner (e.g., with PyTorch JIT or CUDA Graphs). Apply zero-padding for any variable-length feature inputs to ensure consistent shapes. Use mixed-precision inference in heavy layers (like cross networks or transformers) to shrink memory usage and speed up computations. GPU concurrency can handle parallel requests efficiently if the serving infrastructure supports batch requests.
Code Snippet for Model Skeleton
import torch
import torch.nn as nn
class MultiTaskEnsembleModel(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.shared_bottom = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU()
)
self.cross_net = DCNv2Module(128) # Example cross network module
self.transformer = TransformerModule(128) # Example transformer module
self.task_heads = nn.ModuleDict({
"click": nn.Sequential(nn.Linear(128, 1)),
"add_to_cart": nn.Sequential(nn.Linear(128, 1)),
"checkout": nn.Sequential(nn.Linear(128, 1))
})
def forward(self, x):
bottom_rep = self.shared_bottom(x)
cross_out = self.cross_net(bottom_rep)
transformer_out = self.transformer(bottom_rep)
# Simple fusion: average or learned gating
fused_out = (cross_out + transformer_out) / 2.0
outputs = {}
for task_name, head in self.task_heads.items():
outputs[task_name] = torch.sigmoid(head(fused_out))
return outputs
Key Mathematical Formulation for Classification Probability
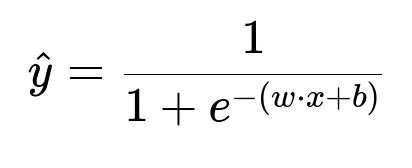
Here, w is the weight vector, x is the input feature vector, and b is the bias term. The model outputs the probability of a positive class (e.g., a user converting).
Follow-Up Questions and Detailed Answers
How do you handle delayed conversion feedback to avoid labeling some positive examples as negative during training?
Use a trailing label window. Extend the training label to account for conversions that occur several days after a click or view. Move the cutoff time further out for each impression, so the training process includes late conversions. Maintain a robust pipeline that merges old impressions with new conversions. Regenerate the training set periodically with updated labels. Let the model see fresh data that captures these delayed events.
How do you select the best ensemble strategy without causing excessive infrastructure overhead?
Start by testing multiple backbones in parallel offline. Evaluate each backbone’s offline metrics and pick the top two or three with diverse error patterns. Combine them in a single architecture that shares bottom layers. For the final score, experiment with simple arithmetic averages, learned gating networks, or linear/logistic blending. Profile online inference to ensure the overhead of multiple modules remains acceptable. Optimize hidden layer sizes or use half-precision to keep GPU memory under control.
How do you stabilize training when labels from different advertisers have varying quality?
Track conversion rates by advertiser and identify outliers. Downweight or remove advertisers with extreme or suspicious label behaviors. Calibrate each advertiser’s label distribution with historical performance. Incorporate features for advertiser or campaign reliability. Let the model learn patterns of consistently good data. Re-check these adjustments by running holdout tests that confirm whether discounting certain advertisers improves overall generalization.
How do you measure success for sparse conversion events when online tests require large volumes of data?
Deploy a holdout approach that reserves a fraction of traffic. Run tests long enough to accumulate sufficient conversions for statistical power. Use aggregated metrics such as total conversions, revenue, or return on ad spend. Compute confidence intervals to confirm whether performance differences are significant. For major launches, run sequential testing to detect any negative signals early and roll back if necessary.
Why does mixed-precision inference not degrade accuracy?
Model weights in half precision can slightly reduce numerical precision, but the final activations often stay close to 32-bit floating point values. Many frameworks automatically handle loss scaling, preventing underflow. The slight rounding does not significantly affect predictions. Empirical checks show negligible drop in metrics. The performance boost in GPU throughput outweighs the minor numerical approximation.
How would you maintain low latency for each request when using a large transformer-based user sequence model?
Limit the maximum sequence length or user events. Truncate the sequence if it exceeds a preset limit. Use sequence-level encoding offline, storing precomputed embeddings for frequent sequences. Implement GPU batch serving to handle concurrent requests in one pass. Monitor latency with real traffic. Scale GPU clusters horizontally if throughput saturates. Use CUDA Graphs to avoid overhead when repeatedly launching many kernels.
How do you ensure the user’s sequence features are updated in real time for accurate recommendations?
Embed a real-time pipeline that streams user actions (clicks, conversions, etc.) into a feature store. When a user makes a new request, query the feature store for recent events. Build or update the sequence representation on the fly, if needed. Any slight lag is mitigated by asynchronous processing and caching. Keep close watch on data ingestion and serving latencies to ensure near real-time updates.
How do you confirm that multi-task learning is genuinely beneficial when each task has different business value?
Compare the multi-task model with standalone single-task baselines. Evaluate each task’s lift in conversions. Check whether the multi-task approach drives better performance or speeds up training. Verify that tasks do not hurt each other. Inspect partial correlation among tasks. If a less relevant task undermines performance, use gating mechanisms or reduce its importance in the shared layers.
How do you reduce overfitting when using so many features?
Regularize the model with dropout in hidden layers. Apply weight decay in certain layers. Use partial data augmentation or label smoothing if beneficial. Early-stop based on validation performance and watch for large generalization gaps. Increase sample coverage for less frequent advertisers or events to avoid memorizing short-term noise.