
ML Case-study Interview Question: Real-Time Airport Driver Wait Forecasting via Demand/Supply Modeling and Simulation


Browse all the ML Case-Studies here.
Case-Study question
You have a large ride-hailing platform serving multiple airports worldwide. Drivers must enter a first-in-first-out queue to pick up arriving passengers. When passenger demand is high relative to the number of drivers in the queue, drivers get trips quickly (undersupply). When passenger demand is low relative to supply, drivers wait a long time for dispatch (oversupply). The company wants a system that forecasts demand and supply dynamics, then generates a reliable estimate of the expected time to receive a ride request (ETR) for each driver waiting at the airport. How would you design this system to predict ETR and display it to drivers in real time, ensuring that both riders and drivers have a better experience?
Explain the core models, data ingestion strategy, infrastructure, and how you would handle operational challenges (e.g., data scaling, partitioning, real-time feature ingestion). Propose an end-to-end solution that can be extended across different airports. Recommend approaches for mitigating the risk of stale or unreliable data, ensuring the latency is acceptable, and discussing ways to improve future iterations of the system.
Detailed Solution
ETR prediction combines queue position estimation and demand forecasting. The core approach is to build separate models for supply and demand, then a simulation layer calculates ETR. The system continuously updates forecasts based on real-time signals from flights, driver abandonments, app usage, and weather.
Supply Model
A gradient boosted tree predicts the “true” position of the driver at the back of the queue (not the naive observable queue length). Input features include observed queue length, driver abandonment rates, arrivals of priority drivers with special passes, and temporal features. This model outputs an integer s_t at time t.
Demand Model
A gradient boosted tree predicts the queue consumption rate in discrete intervals (e.g., 15-minute blocks). Key features include flight arrival schedules, local weather at the destination airport, app engagement (how many riders are actively searching), and time-based signals. This provides an array [d_t,t:t+15, d_t,t+15:t+30, d_t,t+30:t+45, d_t,t+45:t+60], which gives the expected demand for up to 60 minutes in the future.
ETR Calculation
We compare the predicted supply position s_t against cumulative demand in each time interval. Once the driver’s position has been “consumed,” we derive the wait time estimate. We classify it as short, medium, or long.
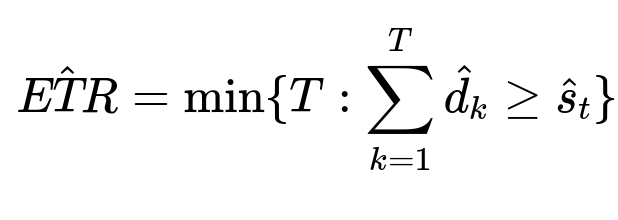
Here, s_t is the predicted true queue position for the last driver. d_k is the predicted queue consumption in each future interval k.
This modular design (supply model, demand model, final simulation) allows independent upgrades to each component and enables reuse of the demand or supply modules for other applications (e.g., city-level demand projection).
Infrastructure and Data Ingestion
A near-real-time (NRT) feature store streams data (driver app engagements, flight info, queue states). Training data can come from batch pipelines, but real-time predictions rely on streaming updates. A single pipeline handles multiple airports to reduce complexity, although some high-traffic airports may need special partitioned models. Kafka streams queue updates. A custom NoSQL database tracks driver queue states. Sharding by driver_id avoids partition imbalances. This requires a materialized view to answer queries by airport queue. Large data emissions can cause throughput and latency issues, so careful throttling or “peek-based” streaming might be used instead of “emit-on-write.”
Serving and App Integration
A back-end service queries both models, applies a simulation heuristic, then returns the final ETR class to the driver app’s airport venue marker. This is a backend-driven UI pattern where the app simply displays what is returned by the service. This approach decouples front-end logic from model complexities, reducing maintenance overhead.
Future Improvements
A deeper time-series or deep learning approach can extend forecasts throughout the day. More granular in-queue ETR estimates could refine predictions for drivers already waiting. Tight integration with supply summoning tools can proactively redirect drivers to high-demand periods. Partitioning by airport or cluster can address specialized airport traffic patterns.
Potential Follow-Up Questions and Answers
How would you handle partial or missing real-time signals, such as flight data inaccuracies?
Robustness requires fallback logic. If flight arrivals are missing, the model can rely on historical average arrival volumes at that time. If weather data is missing, default to typical seasonal conditions. The gradient boosted tree can handle missing features by using internal splitting strategies. A broader fail-safe approach can involve caching recent predictions or reverting to a static heuristic. Monitoring pipelines should trigger alerts when real-time signals drop below a threshold.
Why not train a single model that directly outputs ETR?
An end-to-end model can be opaque, harder to maintain, and more prone to error propagation across demand/supply subproblems. The modular approach isolates each step. If the queue consumption logic is wrong, you only need to fix that part without retraining an entire model. You can reuse the demand model for other tasks. Also, direct ETR regression can struggle with the complexity of queue dynamics, driver abandonments, and spiky flight-driven arrivals. Splitting supply and demand reduces model complexity.
How would you keep latency low when ingesting streaming data from multiple airports?
A near-real-time feature pipeline streaming through Kafka or a similar service can batch updates in short windows. Partition by driver_id or queue_id to distribute load across multiple consumers. Use lightweight transformations in flight data pipelines. Persist enriched data in memory-backed stores for fast retrieval at inference time. Serve predictions through dedicated endpoints with automatic scaling. If an airport has high traffic, spin up separate consumers and microservices to handle that partition and reduce cross-airport contention.
How do you train and evaluate the models to ensure good performance?
Split historical airport data into training and validation sets. A typical approach uses time-series cross-validation to reflect real operational patterns. For the supply model, evaluate how well the predicted position matches the final position drivers experience. For the demand model, evaluate mean absolute error of predicted consumption. Then measure the combined ETR classification accuracy (precision/recall for short/medium/long classes). Track these metrics across multiple airports. Conduct online experiments (A/B tests) comparing ETR predictions against a control group or simpler heuristic.
How would you reduce the risk of data oversampling or undersampling when emitting queue signals?
Implement rate-limiting or “peek-based” event emission. If a driver’s queue position is updated frequently within a short time, combine those updates into a single event to reduce Kafka write volume. For midnight hours or periods with limited updates, you might ensure a minimum emission rate to avoid a long silence in the data stream. Monitor lag in Kafka consumers, and tune your partition strategy or add more consumers if throughput is insufficient.
What partitioning scheme would you propose if certain airports dominate the sample?
Start with a single pipeline for all airports. Monitor performance by airport ID. If an airport has a unique demand profile or accounts for a large share of volume, you create a specialized pipeline for it. This retains a unified approach for most airports while allowing targeted optimizations where needed. Keep an internal library of pipeline templates for quick replication. Ensure metadata and model registry entries are consistent so that training, deployment, and version control do not become fragmented.
Why store queue events in a NoSQL docstore instead of a relational database?
Airport queue events are high volume and require flexible schemas. Drivers join, leave, or get priority passes at unpredictable intervals. A NoSQL store is more suitable for rapid, large-scale writes. Sharding by driver_id or entity_id prevents hotspots. Data lookups often focus on a single driver or queue, which matches the docstore’s access pattern. Traditional relational databases might struggle with scalability under the streaming load.
What testing or monitoring measures would you set up before fully deploying?
Enable canary deployment in a smaller airport or a subset of drivers to verify correctness. Track real wait times vs. predicted ETR, queue lengths, and user feedback. If predictions deviate beyond a threshold, roll back or issue alerts. Monitor logs for timeouts or Kafka lag. Check memory usage on the docstore. Maintain detailed dashboards for driver abandonment rates and flight data accuracy. Once performance metrics are stable, roll out more widely with incremental expansions, continuing to track metrics for anomalies.
How would you integrate deep learning to improve the queue consumption model?
Collect time-series data of flight arrivals, queue consumption, and real-time engagement. Feed these sequences into a recurrent or transformer-based architecture. Output predicted consumption at each future time step. Compare performance to gradient boosted trees. If the network generalizes well to unseen patterns (e.g., sudden flight cancellations), keep it. Otherwise, revert to simpler methods for interpretability or speed. Gradually incorporate the deep learning model into your pipeline once it proves stable and interpretable in production.
Would you ever consider real-time retraining of the models?
Real-time retraining is expensive and requires a robust infrastructure that can handle streaming data and produce frequent model updates. If your environment changes rapidly (e.g., flight patterns or driver behaviors shift on short notice), then micro-batch retraining daily or hourly might help. But you need to ensure resource availability, strict model versioning, and stable rollout processes. Often, partial online learning is enough, especially if your current system ingests near-real-time features. A careful cost-benefit analysis is crucial to decide the retraining frequency.