
ML Case-study Interview Question: Neural Network Ranking with Similarity Penalty for Diverse Marketplace Search.


Case-Study question
You are asked to design a search ranking system for a major online marketplace that connects millions of users to a vast set of listings. The system must maximize the likelihood of a booking for any query but also incorporate result diversity. How would you build this solution end-to-end? Outline your approach and the machine learning techniques you would use to optimize both individual listings’ relevance and the variety of the overall returned set.
Your task:
Explain how you would train a neural network to predict booking probabilities for different listings, use it to create a ranked list of search results, and then enhance the final list to include more diverse listings without sacrificing too many bookings from the top choices. Include important details such as training data construction, model loss function, evaluation metrics, and ways to measure diversity.
Detailed Solution
Core Overview
Start with a pairwise ranking neural network that estimates a numeric score for each listing. The system compares two listings at a time to produce a probability for which listing is more likely to be booked. This approach is repeated across large volumes of historical query data. The final output is a ranking: listings with higher scores appear higher in search results.
Pairwise Ranking Objective
Train the network using pairs of (booked_listing, not_booked_listing) from past user sessions. The goal is to maximize the difference in predicted scores for these pairs. A common loss function is a logistic form that enforces higher scores for the booked listing.
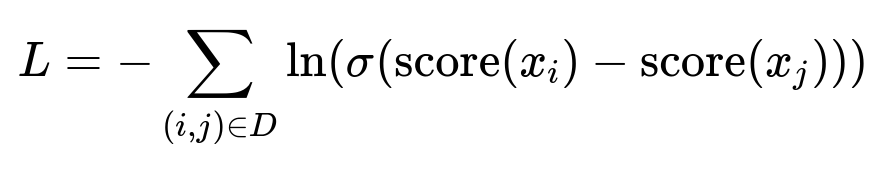
Here:
D is the set of all training pairs constructed from historical searches.
i corresponds to a booked listing; j corresponds to a listing that was not booked in the same session.
score(x) is the neural network’s output for listing x.
sigma is the logistic function 1 / (1 + exp(-z)).
The network weights are updated so that the final score function aligns with real-world booking preferences.
Challenge of Overemphasizing the Majority
Relying only on the pairwise ranking model can bias the top of the list toward what the majority of users prefer, such as cheaper options. This excludes a sizeable fraction of users who may prefer premium or high-quality listings. The system’s "majority principle" overemphasizes the most common preferences.
Capturing Diversity by Penalizing Similarity
A second similarity network estimates how close a listing is to the ones already placed higher in the results. Once the top-ranked listing is chosen, subsequent listings are scored again with a penalty term for similarity. This creates more variety in the final ordered set.
Here:
hat{score}(x_{i}) is the adjusted score for listing i.
score(x_{i}) is the original output from the main ranking network.
sim(x_{i}, x_{k}) is the similarity between listing i and a previously placed listing k.
alpha is a hyperparameter to set how strongly we penalize listing i if it is too similar to the already placed listings k.
Selecting the top position uses the unadjusted score(x). Then for position 2, 3, etc., the system uses hat{score} to reduce the rank of redundant listings and surface more unique options.
Model Training and Implementation Details
Use large-scale historical data for both the main pairwise ranker and the companion similarity estimator. Construct pairs for the similarity model by taking a top search result listing (antecedent) and then distinguishing between booked vs. not-booked listings that appear lower. The similarity network learns to assign higher similarity if a listing is close to the antecedent in major attributes (e.g., price, location).
During inference:
Sort all candidate listings by the main ranking network’s score.
Place the top listing in the first position.
For the next position, re-score each remaining listing with the similarity penalty included in hat{score}.
Pick the listing with the highest adjusted hat{score}.
Iterate until all positions are filled.
Observed Results
This approach significantly increases overall booking value and results in more balanced coverage of user preferences. A measurable improvement in uncancelled bookings indicates the enhanced system is robust and beneficial for both the business and customers.
Practical Example (Code Snippet)
# Hypothetical example showing the re-ranking step
import numpy as np
def rerank_listings(listings, main_scores, similarity_fn, alpha=0.5):
# listings: array of listing ids
# main_scores: dict with listing_id -> main ranking score
# similarity_fn: function similarity_fn(listing_a, listing_b) -> float
final_ranking = []
remaining = set(listings)
# Pick top listing by main score
current_best = max(remaining, key=lambda x: main_scores[x])
final_ranking.append(current_best)
remaining.remove(current_best)
while remaining:
best_listing = None
best_adjusted_score = -np.inf
for candidate in remaining:
sim_penalty = 0.0
for placed in final_ranking:
sim_penalty += similarity_fn(candidate, placed)
adjusted_score = main_scores[candidate] - alpha * sim_penalty
if adjusted_score > best_adjusted_score:
best_adjusted_score = adjusted_score
best_listing = candidate
final_ranking.append(best_listing)
remaining.remove(best_listing)
return final_ranking
The code uses a loop to pick the top item and then re-scores every other listing by subtracting a penalty proportional to cumulative similarity with already placed listings.
How to Handle Follow-Up Questions
Below are possible follow-up questions that a senior interviewer might ask. These questions test detailed understanding of data science, large-scale systems, and practical considerations. Each answer shows the logic behind the responses.
How do you balance the penalty parameter alpha?
Alpha can be tuned using validation data or an online A/B experiment. Too high alpha might push the system to pick listings that are very different but suboptimal in other respects. Too low alpha might fail to introduce sufficient diversity. Monitor metrics such as overall booking rate, average booking value, and user satisfaction indicators to find the best alpha.
How do you measure diversity in a search result?
Compute a similarity score across the top listings. Alternatively, calculate a measure of coverage for crucial listing attributes: price ranges, number of bedrooms, location, etc. Another approach is to observe user metrics like how many distinct types of listings were eventually booked. The key is ensuring the final result has enough variety to cater to different preferences.
Why not directly model user segments for different price bands?
User segmentation can help if you have a clear way to bucket preferences. But many queries contain a mixture of user behaviors. The pairwise neural network remains flexible. The added similarity penalty ensures the system naturally promotes variety without manually segmenting users. This approach handles new or evolving user segments more gracefully.
How do you handle real-time ranking latencies?
Score computations must be efficient. Precompute neural network embeddings, store them in memory-optimized data structures, and use approximate nearest-neighbor methods if needed for similarity. The re-ranking loop must be optimized or parallelized. For high-traffic scenarios, a small subset of top candidates might be re-ranked while the rest use the main score alone.
What if similarity depends on dynamic factors like availability or date?
The companion similarity network can incorporate date-specific or availability-specific features in training. Provide those features as inputs so it learns how similarity shifts over time. Any time a factor changes that might affect listing similarity, refresh or partially retrain the model.
Could there be a cold-start problem for new listings?
Include regularization or a fallback score for listings with few historical records. Use content-based features (location, price, number of rooms) to generate a decent baseline. As soon as enough interaction data arrives, the system updates the neural network. The re-ranking step still helps to ensure no single attribute dominates the search result.
How would you evaluate success after deployment?
Run an online A/B test where a percentage of traffic sees the new diversity-aware ranking. Track bookings, booking value, user engagement metrics, cancellation rates, and review scores. A stable lift in these metrics indicates success. Offline analysis can supplement, but real user behavior is the best measure.
How do you explain the final list to stakeholders?
Show top metrics like increment in total bookings, average revenue, and user satisfaction. Demonstrate how the system returns a mix of cheaper and premium listings. Provide example queries that illustrate improvements. Emphasize that the method uses a data-driven approach to boost both quantity and quality of bookings.
How do you confirm that diversity truly benefits users and not just the business?
Look at post-booking feedback such as review ratings or net promoter scores. The method mentioned in the problem gave higher 5-star ratings, implying genuine user satisfaction. High repeat usage also suggests that showing more variety builds trust and meets diverse needs.
That completes the case-study question, the comprehensive solution, and the potential follow-up questions with in-depth answers.