
ML Case-study Interview Question: Multi-Objective Restaurant Ranking: Wide & Deep Learning with Monotonic Constraints


Browse all the ML Case-Studies here.
Case-Study question
A large food-ordering platform observes a direct link between how restaurants are ranked on its homepage and the rate at which customers place orders. They aim to build a ranking system that balances multiple business goals, such as relevance, delivery experience, and personalized preferences. They want to move beyond a simple pointwise ranking system that scores each restaurant individually, towards a system that compares restaurants relative to each other. They also want to incorporate memorization of individual customer tastes and real-time context, while ensuring interpretability of the model. How would you architect a solution to address these objectives, detail your approach to model training and evaluation, and explain how you would iteratively refine the solution?
Constraints and requirements:
Directly optimize multiple objectives such as relevance and delivery factors. Incorporate methods (pairwise or listwise) to capture relative ordering of restaurants. Use a combination of generalization and memorization to handle both broad patterns and unique user-specific behavior. Ensure monotonic behavior with respect to certain features (like recency). Adopt an evaluation framework that can reliably compare different model variants offline and in production.
Detailed in-depth solution
Overview of the approach
Training data consists of rows representing customer-restaurant-time instances. The label is 1 if the customer ordered from a restaurant in that session, else 0. There is significant class imbalance because very few restaurants end up being ordered from, compared to the total available. The final model must optimize multiple objectives, maintain relative ordering insights, and incorporate memorization of user-level patterns.
Multi-objective optimization
Balancing multiple objectives (for example, maximizing relevance and minimizing delivery distance) often uses linear scalarization. One typical approach uses weights that reflect the importance of each sub-objective.
The parameter w_i is the weight for objective O_i. We tune these weights by simulating trade-offs in offline experiments. A curve is generated by varying w_i and assessing how much we sacrifice on one metric by gaining on another.
Learning relative ordering
Pairwise or listwise losses penalize wrong orderings more directly than a pointwise loss. A pairwise loss function compares two items at a time and enforces that if one restaurant is more relevant, it should have a higher predicted score. In a listwise loss, entire ranked lists are compared, but pairwise training often leads to simpler implementations and a good balance of accuracy.
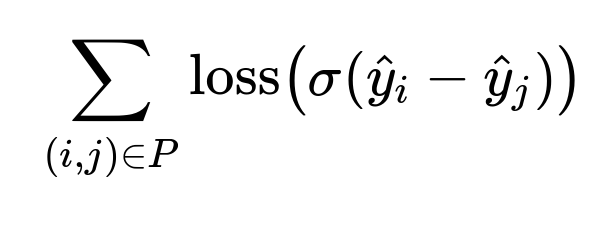
Here, (i,j) are pairs of restaurants, and \hat{y}_i is the model’s score for restaurant i. The function \sigma could be a sigmoid.
In practice, inference remains pointwise. For training, we sample pairs (i,j) for each session, feed them in batches, and optimize pairwise ordering accuracy.
Wide and Deep with lattice constraints
A deep neural network generalizes well across multiple customers, but it might forget exact individual preferences. A wide component memorizes feature crosses, recency indicators, or embeddings for city and time-slot. This combination balances generalization and memorization.
A lattice layer enforces monotonic constraints on features like recency. When recency increases, predicted relevance should not decrease. A lattice layer can be integrated into the final network layers, enabling direct domain knowledge injection.
Architecture outline
The wide branch has sparse cross-features capturing user-specific signals like "user_id x restaurant_id" or "frequent cuisine x user_id."
The deep branch takes raw dense features: restaurant embeddings, user embeddings, time of day, location vectors, and so on.
The lattice branch receives features on which monotonic constraints must hold. For instance, recency or similarity to past orders.
The outputs of these branches are concatenated, then passed through fully connected layers. The last layer outputs the final ranking score.
Model training details
Sampling negative labels: Negative labels are the customer-restaurants not chosen in a session. We randomly sample from these to maintain manageable class imbalance.
Optimizer choice: ADAM often converges faster than ADAGRAD or plain SGD. Learning rate tuning remains crucial.
Regularization: A dropout layer of 0.3 to 0.5 in fully connected layers often prevents overfitting. Weighted loss can handle class imbalance.
Pairwise vs listwise: Pairwise often yields higher pairwise accuracy in practice.
Final performance and evaluation
NDCG is used to measure the ranked ordering. Offline simulation replays the sessions and computes how well the relevant restaurants are placed at top ranks. We run A/B experiments comparing new models with a baseline.
The wide and deep approach with a lattice layer usually surpasses a simpler gradient-boosted tree model. The combination preserves individual preferences while capturing general patterns and respecting monotonic constraints.
Example Python code snippet
import tensorflow as tf
from tensorflow.keras import layers
# Wide inputs
wide_inputs = tf.keras.Input(shape=(wide_feature_dim,), name='wide_inputs')
# Deep inputs
deep_inputs = tf.keras.Input(shape=(deep_feature_dim,), name='deep_inputs')
deep_hidden = layers.Dense(128, activation='relu')(deep_inputs)
deep_hidden = layers.Dropout(0.5)(deep_hidden)
deep_hidden = layers.Dense(64, activation='relu')(deep_hidden)
# Lattice inputs
lattice_inputs = tf.keras.Input(shape=(lattice_feature_dim,), name='lattice_inputs')
# Lattice layer or custom constraints code can be integrated here
# Combine all
combined = layers.concatenate([wide_inputs, deep_hidden, lattice_inputs])
output = layers.Dense(1, activation='sigmoid')(combined)
model = tf.keras.Model(inputs=[wide_inputs, deep_inputs, lattice_inputs], outputs=output)
# For pairwise training, specialized approach or TF Ranking library might be used.
model.compile(optimizer='adam', loss='binary_crossentropy')
This sketch shows the wide, deep, and lattice inputs. Pairwise or listwise training could be implemented using specialized libraries or custom loops.
Iterative refinement
Improve feature coverage with more real-time signals (time since last order, page scrolling events, in-session dwell times). Build segments for different user behaviors. Vary monotonic constraints for certain features to see how results shift. Perform offline simulations followed by online testing. Adjust weighting in linear scalarization based on business trade-offs.
What if the interviewer asks these follow-up questions?
1) How would you handle negative sampling in a highly imbalanced dataset?
Random sampling of non-purchased restaurants is a simple method, but we risk including many irrelevant examples. Too many negative samples can overshadow the positive examples. A balanced approach is to sample negatives at a fixed ratio or with a strategy that selects "hard negatives," such as restaurants that the customer browsed but did not order from. This approach forces the model to distinguish subtle differences between similarly appealing restaurants.
2) Why not just train the model with a listwise loss at inference time too?
Scoring a list at inference can be computationally expensive for large catalogs. Pairwise or pointwise inference is more scalable because each restaurant is scored independently. The final ranking step sorts restaurants by that score. A purely listwise inference method would require re-computing complex interactions for every potential list, which is not feasible at scale.
3) Why inject monotonic constraints into the model through a lattice layer?
Some features must have a predictable effect on the output. Recent orders often make a restaurant more relevant, so the model score should not drop when recency increases. Lattice layers let us enforce these constraints directly in the architecture, leading to more interpretability and robustness. Without explicit constraints, deep networks might violate expected monotonic relationships, causing trust issues and unpredictable results.
4) How do you select the right weighting factors for linear scalarization?
We typically run offline simulations on historical data. We vary the weights across different objectives and plot the Pareto frontier that shows trade-offs between metrics like NDCG and average delivery distance. We look for an operating point that yields acceptable performance on all objectives. We then confirm this choice in an A/B test.
5) What approach would you follow to incorporate real-time user signals?
Store session signals like time spent on a restaurant’s page or partial menu expansions in memory. Inject these real-time features into the same wide-and-deep model, or train an auxiliary network to capture them. Deploy the updated model in an environment where incoming requests are augmented with these session-level features. Monitor latency overhead, because real-time feature computation might slow overall system response.
6) How do you ensure that the model does not overfit on memorization?
Excessive reliance on memorization can harm generalization. We impose regularization (dropout, weight decay) and track performance on a validation set with unseen users or restaurants. We also calibrate how many cross-features or embeddings we include in the wide branch, so that the model does not just memorize user-restaurant pairs.
7) How would you test the new ranking model in production?
Start with shadow testing or offline replays. Move to an online A/B test where only a subset of users receive the new model. Monitor metrics like conversion rate, average order value, user retention, or last-mile distance. If we see consistent improvement (and no regressions on critical metrics), gradually ramp it up to all users.
8) How would you handle time decay of user preferences?
Add a time decay factor or recency-based feature that indicates how recent the user’s last order from the restaurant was. Feed that feature into the lattice input or as part of the wide input. Enforce monotonic constraints so that relevance does not contradict recency signals. We can also weight user history so that older preferences have diminishing influence.
9) Could you use a transformer-based embedding approach instead of wide-and-deep?
A transformer-based architecture can capture complex relationships in embeddings. It can process sequences of user orders or session steps to generate better context vectors. This might lead to more accurate recommendation patterns. The main concern is computational overhead. If we can handle that overhead in batch or real-time contexts, a transformer-based pipeline might outperform standard wide-and-deep.
10) How do you handle modeling for new restaurants or new users?
Use initialization or cold-start strategies. For new restaurants, apply default embeddings based on their cuisine type, price range, or location. For new users, rely on population-level features (city, time of day, or general popularity signals). Gradually update embeddings as new interactions occur.
11) How does pairwise training scale when there are many restaurants?
The training set size can grow quadratically if you form all pairs. You can constrain pair generation to the user’s top relevant or top engaged restaurants to keep it manageable. Alternative sampling strategies select only the important pairs for training. If the framework or data pipeline is well optimized, modern GPUs or TPUs can handle large pairwise sets.
12) How do you detect if the model is misranking certain restaurants systematically?
Track patterns of user complaints or abrupt drops in orders for particular types of restaurants. Investigate if the model systematically ranks certain classes lower. Examine partial dependence plots for relevant features. Look at post-training diagnostics for monotonic features. Retrain with adjusted constraints, rebalanced sampling, or additional domain checks.
13) How do you track if your multi-objective weights become stale?
Over time, business priorities might shift (focus on lower delivery time or new user acquisition). Retrain or fine-tune the model with updated weights or additional objectives. Continuously monitor if certain metrics degrade. Revisit the Pareto frontier analysis to confirm that the current weights still balance objectives.
14) Would you apply any special technique to manage seasonal changes in user behavior?
Build a modular feature that tracks seasonality or peak-time behavior. For example, embed the month, day-of-week, or special festival period. Feed these seasonality features to the deep network. Maintain specialized model versions for high-peak seasons, or retrain with more recent data leading into those periods.
15) How do you explain or interpret the final ranking to stakeholders?
Show partial dependencies or monotonic constraints. Illustrate how changing recency or location influences the predicted relevance. For wide-and-deep components, highlight the feature crosses or embedding signals that heavily influence final scores. For the lattice layer, point out the enforceable constraints, demonstrating consistent model behavior.