
ML Case-study Interview Question: Optimizing Rideshare Prices with Real-Time Reinforcement Learning


Browse all the ML Case-Studies here.
Case-Study question
A rideshare platform wants to optimize its pricing to balance supply and demand, support consistent rider experiences, and remain competitive. The system has three layers: a pricing orchestration layer for stable price quotes, a pricing operations layer for strategic and tactical guidance, and an algorithmic pricing layer that uses real-time machine learning models, including reinforcement learning, to adjust prices based on rider demand and driver availability. Propose a comprehensive strategy to design and implement such a system. Outline how you would handle system architecture, data pipelines, model selection, real-time feedback loops, and online learning techniques. Explain how your solution will address reliability, fairness, and competitiveness. Show any crucial mathematical formula you consider central to your approach.
Detailed Solution
System Architecture
The pricing orchestration layer stabilizes ride quotes over a short time. The platform caches relevant ride data and ensures consistent pricing within sessions. Each ride request passes through an application programming interface layer that collects route data, time estimates, and fees. The calculation layer aggregates inputs, applies pricing rules, and returns itemized prices. A storage system logs each quote to maintain historical records and support audit trails.
Data Pipelines
Real-time streams capture ride requests, driver availability, and marketplace events. An analytics pipeline processes these streams. Offline components handle large-scale historical data analysis using Apache Spark, Hive, and distributed storage. These systems feed aggregates and features into the serving stack, which acts on fresh signals.
Model Selection
Pricing depends on two parts. One part is structural pricing, which sets a baseline fare incorporating route distance, estimated time, and time-based factors. Another part is dynamic pricing, which adjusts the baseline based on supply-demand patterns. This approach avoids stale estimates by using frequent updates to reflect actual driver entries and exits.
Reinforcement Learning Core
Real-time price adjustments rely on a policy that evaluates the marketplace state and computes an action (price increment or decrement). The algorithm collects reward signals from completed rides and adjusts the policy to meet multiple objectives such as revenue, conversion rate, and rider-driver matching quality.
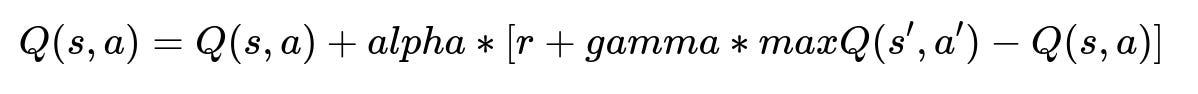
Here, s is the current market state represented by factors like driver availability, rider requests, and time of day. a is the chosen pricing action. Q(s,a) is the action-value function indicating how good it is to apply action a in state s. alpha is the learning rate controlling how fast the model updates. r is the immediate reward, which can combine metrics like completed rides, wait times, and potential revenue. gamma is the discount factor for future rewards. s' is the next state after applying action a. max Q(s',a') is the best predicted value for the next state.
Online Learning and Real-time Feedback
Offline training initializes model parameters using historical data. The system refines those parameters online by continuously interacting with real marketplace conditions. This involves collecting short windows of ride transactions, evaluating metrics (such as rider cancellation rate, driver wait times, or surge intensity), and updating model weights or Q-values accordingly.
Practical Implementation Details
Implement the pricing engine in Python for flexibility. Use a serving framework like Flask or a similar microservice. Store frequent updates in Redis for short-term caching and in Dynamo for structured records. Keep stable counters and aggregated metrics in a near real-time data system to measure the impact of each price change. Enable fast rollbacks if anomaly detectors or policy constraints indicate unhealthy behavior.
What if a sudden market disruption happens (e.g., major event surge)?
A robust approach involves an override component that can apply special logic. If the system detects abnormally high request volume at a location, it can temporarily raise the dynamic pricing factor to ensure enough drivers enter the area. The reinforcement learning pipeline quickly collects new data, updates the Q-values, and reverts to normal if the spike ends.
How do you handle fairness when implementing dynamic pricing?
Enforce consistent pricing rules for similar riders at similar times. Use membership features or promotional discounts as separate line items rather than mixing them into the baseline fare. Label these adjustments so riders understand why they see a particular price. Validate fairness by running frequent checks on distribution differences across user segments, ensuring that no unintended biases appear.
How can you prevent instability or oscillations in prices?
Smooth out price updates using a cooldown period or weighting function that averages recent actions. Check if large consecutive changes reduce user satisfaction or cause driver confusion. If the policy tries a big jump in price, hold it for a minimum window and measure the outcome. This approach maintains stable experiences and avoids rapid swings in pricing.
How do you evaluate the performance of the pricing model?
A separate off-policy evaluator simulates different policies on stored trajectories. Measure metrics such as total rides completed, driver utilization, rider wait times, and overall revenue. Compare the new policy against baseline strategies or purely rule-based heuristics. If the new policy outperforms on key metrics, gradually increase its rollout percentage in production while monitoring anomalies.
How do you ensure reliability at large scale?
Design the system with fault tolerance using replication and redundancy in microservices. Cache partial computations and gracefully degrade if a downstream service lags. Maintain load balancers and circuit breakers to reroute requests. Log all transactions with a unique quote identifier and store them in a large-scale storage solution. Monitor end-to-end latency and add fallback strategies that revert to simpler pricing rules if real-time components fail.
How do you handle cross-functional influences like airport or venue-specific pricing?
Integrate special logic in the pricing operations layer. Mark flagged locations that require venue fees or strategic adjustments. Incorporate them in the structural price formula, then feed them into the dynamic pricing model. Keep these adjustments transparent in the line items for final quotes. Maintain separate monitoring for these scenarios to ensure correct driver incentives and passenger costs.
How would you extend this system in the future?
Increase complexity by moving to a hierarchical reinforcement learning structure, where a top-level policy sets global strategies and a lower-level policy handles local dynamic adjustments. Consider synergy with other marketplace objectives such as driver retention, multi-hop trips, or multi-vehicle fleet types like bicycles and scooters.
How do you confirm the candidate truly understands the approach?
Ask them to walk through the data flow from ride request to final quote, explaining how each step influences the model’s decision. Ask them to examine a scenario with unexpected external shocks and how the system corrects itself. Listen for understanding of caching strategies, real-time feature engineering, RL fundamentals, and how to maintain fairness and reliability in a fast-moving marketplace.