
ML Case-study Interview Question: Faster Customer Support Answers Using Semantic Search and Language Models.


Browse all the ML Case-Studies here.
Case-Study question
You are leading a data science project for a large platform that handles high volumes of customer support cases. The current keyword-based search leads to slow and inefficient solutions. Your task is to design a robust question-answering system that empowers service agents to resolve cases faster and reduces the time spent digging through lengthy documents. Explain how you would approach this end-to-end, from data preparation to model deployment, ensuring that the system understands natural language queries, extracts precise answers from knowledge articles, and provides direct, shareable answers to agents.
Detailed Solution
Agents often face repetitive questions from customers. They search a knowledge base using keywords that frequently return large amounts of text, forcing them to scroll through many sections to find answers. An improved system requires:
Semantic Retrieval with Language Models
Traditional search focuses on matching keywords. The new system needs a deeper understanding of user intent. Pre-trained language models such as BERT-like architectures compute vector representations (embeddings) of both queries and passages. The search pipeline retrieves candidate passages using a combination of lexical methods and semantic embeddings, then reranks these candidates to display the most relevant snippet.
Passage Splitting for Granular Answers
Long knowledge articles are split into smaller segments. Each segment remains semantically coherent. When a query arrives, these smaller segments are individually embedded and then compared to the query’s embedding to find the best match.
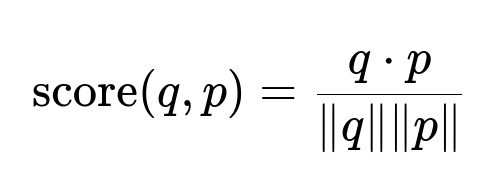
Above is the cosine similarity formula. The vector q is the embedding of the query. The vector p is the embedding of a candidate passage. The dot in the numerator represents dot product of the two vectors. The denominator is the product of their magnitudes. A higher score indicates stronger similarity.
Fusion Reranker
The system combines signals from both sparse/lexical retrieval (keyword-based) and dense/semantic retrieval (embedding-based). Final ranking orders passages by relevance. This yields short and actionable answers. Agents can copy these answers directly or click through to see the full article. This shortens customer wait time and improves agent efficiency.
Implementation Details
Data preprocessing splits articles into meaningful passages. A pipeline is built in Python, often using a framework like PyTorch or TensorFlow. Training or fine-tuning a BERT-like model on domain-specific data helps the system learn the nuances of typical support inquiries. During inference, vector indexes facilitate fast lookups. Libraries such as Faiss or ElasticSearch with vector search extensions handle the dense retrieval step. The final reranker fuses results from textual matching (e.g., BM25) and vector similarity to prioritize the best answers.
Below is a Python-style example showing how you might embed queries and passages:
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")
def embed_text(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=256)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state[:, 0, :]
return embeddings.squeeze().detach()
query = "How do I add an email signature?"
query_embedding = embed_text(query)
# The same function is used to embed each passage.
# Then compute cosine similarities or store them in a vector index for fast retrieval.
Deployment and Monitoring
A service layer handles the semantic retrieval pipeline. Real-time logs track search latency. You measure performance with metrics like time-to-resolution and retrieval accuracy. A feedback loop captures whether agents found answers useful. Any needed retraining or refinement is scheduled regularly.
Follow-Up Question 1
How would you handle low-resource data in which only a few domain-specific samples are available for training?
Answer and Explanation Few-shot or zero-shot techniques can reduce the need for large labeled datasets. You would:
Use a pre-trained language model already exposed to general text.
Fine-tune the model with any available in-domain text, even if unlabeled. Self-supervised methods like masked language modeling on domain documents help the model internalize domain vocabulary.
Evaluate performance on small validation sets or by manual agent feedback to see if the embeddings align with user intent.
Use data augmentation by slightly rephrasing known queries or artificially creating synonyms. This enriches model training samples without requiring large manual annotation.
Follow-Up Question 2
Why combine both lexical and semantic search rather than relying on embeddings alone?
Answer and Explanation Lexical search excels at matching exact terms, which is crucial if a user query references a specific product name or version. Semantic embeddings capture contextual meaning but may miss rare jargon or product IDs. By fusing both outputs, you harness lexical precision and semantic depth. This approach catches both straightforward keyword matches and conceptually aligned passages that do not share identical words.
Follow-Up Question 3
How do you justify the additional inference cost of transformer-based embeddings in a high-traffic environment?
Answer and Explanation You offset computation costs by:
Caching embeddings for the knowledge base passages, since they remain static or infrequently updated.
Using GPU or specialized hardware for fast batch processing of queries.
Implementing approximate nearest neighbor search structures (e.g., Faiss), which speed up vector comparisons significantly.
Monitoring throughput and using horizontal scaling if traffic spikes.
Follow-Up Question 4
What if query volume is huge and real-time scoring is slow? How would you maintain latency within acceptable limits?
Answer and Explanation You would:
Precompute passage embeddings and store them in a vector index.
Implement load balancing across multiple retrieval servers.
Batch incoming queries so they pass through the model in chunks rather than one by one.
Prune and update your knowledge base so it remains concise.
Use quantization or distillation on the large model to reduce its size and improve speed.
Follow-Up Question 5
Explain how you would track the impact of this system on the customer support team’s performance.
Answer and Explanation You monitor:
Case resolution time before and after deployment.
Agent satisfaction via surveys on how quickly they retrieve answers.
Customer satisfaction through net promoter scores or feedback forms.
Adoption metrics like how often agents use the question-answering feature versus older methods.
Error analysis on queries returning low confidence or irrelevant answers, then refine or retrain as needed.
Follow-Up Question 6
How do you manage changes to knowledge base articles so the search system remains accurate?
Answer and Explanation You rebuild passage embeddings whenever there is a significant update to articles. You maintain versioning so older indexes remain available while you generate new ones. For frequent updates, you can incrementally embed only changed sections and re-inject them into the vector index. Consistency checks ensure references remain valid, and regression tests confirm that core queries still yield correct answers.
Follow-Up Question 7
How would you ensure data privacy, especially if embeddings might contain sensitive text?
Answer and Explanation You can:
Anonymize sensitive information before model ingestion.
Mask or redact personal data within text that goes into embeddings.
Ensure encrypted transmission of embeddings and store them in a secure environment.
Use role-based access control to ensure only authorized personnel and services can query or retrieve embeddings.
Follow-Up Question 8
What if the retrieved passage is relevant but the text is still too lengthy?
Answer and Explanation You segment the final passage further by using a smaller text window around the likely answer. A re-scoring step or a small generative summarization layer might produce an even more concise snippet for quick agent viewing. This final snippet is placed at the top of the results, and the full passage link remains accessible if the agent needs more context.
Follow-Up Question 9
Could you apply the same approach to other domains beyond customer support?
Answer and Explanation Yes. Any domain where textual information must be retrieved by queries would benefit. Examples include legal document search, product manuals, or academic literature search. The same pipeline of embeddings, semantic similarity, and re-ranking generalizes well across large text repositories where precise answers improve the user experience.
Follow-Up Question 10
Why is it beneficial to show short snippets inline rather than linking to the entire article?
Answer and Explanation Service agents need instant clarity. Short snippets reduce context switching. Agents avoid extra clicks or scrolling through multiple sections. This leads to faster resolution and better customer satisfaction. They can copy relevant text directly, respond to customers quickly, and handle more support tickets in less time.
Follow-Up Question 11
What are your top considerations for rolling out a proof-of-concept in a production environment?
Answer and Explanation A typical proof-of-concept includes a small subset of knowledge articles, a minimal passage-splitting pipeline, and a workable vector index. You start with limited traffic to measure performance and relevance. You carefully measure latency, memory usage, and user feedback. You plan for incremental scaling with stable hardware resources. Proper logging captures any failure points for debugging. Once stable, you extend coverage to all articles, add fallback mechanisms, and finalize a robust production deployment strategy.