
ML Case-study Interview Question: Detecting Streaming Fraud at Scale with Semi-Supervised Autoencoders


Browse all the ML Case-Studies here.
Case-Study question
You are working at a global streaming company that serves digital content to millions of subscribers on various devices. Your team suspects three major fraud types: content fraud, service fraud, and account fraud. You have limited ground-truth labels and only a few rule-based heuristics defined by security experts for identifying suspicious activities. You also have large-scale device and license acquisition logs. You need to design and implement a robust machine learning system to detect these fraud types at scale and in near real-time. How would you architect your solution to handle feature engineering, data labeling, model development (supervised or semi-supervised), and reliability of the final deployment? Please outline your approach, justify each major step, and address the trade-offs. Provide pseudocode or actual code snippets to illustrate core steps.
Detailed Solution
Overview of the Proposed Approach
The system needs a hybrid pipeline leveraging expert-driven labeling heuristics and machine learning methods. Rule-based approaches help create an initial labeled dataset. Model-based methods scale detection and adapt to new threats.
Data Labeling and Heuristic Creation
Security experts define a few rules to label suspicious accounts. These rules rely on parameters such as rapid license acquisitions, excessive streaming errors, or unusual device-and-DRM combinations. Any account that meets these heuristic rules is labeled anomalous. Trusted accounts are labeled benign. This approach might include false positives, but it seeds initial labels.
Feature Engineering
Each account gets aggregated daily features capturing device usage, number of streams, and license requests. Examples include:
dist_dev_id_cnt (number of distinct devices used by an account)
license_cnt (total number of licenses requested)
dist_enc_frmt_cnt (distinct encoding formats used)
dev_type_a_pct (percentage of a certain device type usage)
Percentage-based features highlight usage patterns, while count-based features measure volume of activity. Higher counts in certain features (e.g., multiple devices used in a short period) can signal suspicious behavior.
Handling Label Imbalance
Fraud data is often minority class data. Synthetic Minority Over-sampling Technique (SMOTE) synthesizes additional examples of the minority class to mitigate imbalance during training. SMOTE interpolates feature values between existing minority samples to create synthetic points.
Semi-Supervised Anomaly Detection
This approach only trains on benign data to learn normal patterns. The model flags points that deviate significantly from the benign distribution.
Autoencoders are common for this. The encoder-decoder network tries to reconstruct inputs. Suspicious accounts often yield higher reconstruction error:
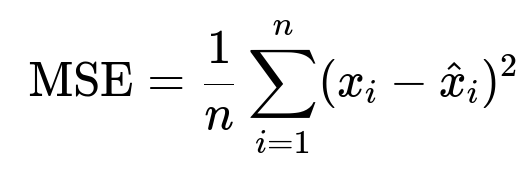
Here, x_i is the original input, and hat{x}_i is the reconstruction. If the MSE is above a threshold, the account is considered anomalous.
Isolation Forest or One-Class SVM can also be tried for semi-supervised detection, but deep autoencoders often work better on high-dimensional data.
A simple PyTorch-like autoencoder snippet:
import torch
import torch.nn as nn
import torch.optim as optim
class FraudAutoencoder(nn.Module):
def __init__(self, input_dim):
super(FraudAutoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(8, 16),
nn.ReLU(),
nn.Linear(16, input_dim)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# Suppose X_benign is your benign training set
# Convert data to PyTorch tensor
input_dim = X_benign.shape[1]
model = FraudAutoencoder(input_dim)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(100):
model.train()
optimizer.zero_grad()
outputs = model(torch.FloatTensor(X_benign))
loss = criterion(outputs, torch.FloatTensor(X_benign))
loss.backward()
optimizer.step()
Supervised Anomaly Detection
When a labeled dataset is available (benign vs anomalous), a binary classification approach can be used. Models like Random Forest, Gradient Boosting, or XGBoost often perform well. These models can also extend to a multi-class multi-label scenario, distinguishing among content fraud, service fraud, and account fraud simultaneously.
Hyperparameter tuning and cross-validation ensure optimal model performance. Thresholding may be necessary to adjust recall vs precision trade-offs.
Model Evaluation
Metrics like accuracy, precision, recall, and f1 are standard. In multi-label tasks, additional metrics (Hamming loss, exact match ratio) are used. For multi-class problems, you can sum or average metrics across classes.
Deployment Considerations
The pipeline must process fresh data quickly:
Data pipeline: Real-time or near real-time ingestion of streaming logs.
Feature store: Automated feature computation (per account, per day or hour).
Model service: Low-latency prediction to flag suspicious activity.
Continuous feedback loop: Investigations confirm or refute flagged accounts, refining training data.
## Potential Follow-Up Questions
How would you handle noisy heuristic labels?
The heuristic labels can produce false positives. Training a model exclusively on these labels may propagate inaccuracies. Perform a small-scale manual review to curate a high-confidence subset. You can use confidence-weighted labeling, or incorporate weak supervision methods (e.g., Snorkel) to refine label quality.
Why might you choose semi-supervised over fully supervised methods?
Fully supervised methods require reliable labels for both benign and anomalous classes. When the true anomalous population is under-sampled or has uncertain labels, semi-supervised models can learn normal patterns more robustly. They still work when few or no labeled anomalies are present.
What if your autoencoder reconstruction threshold is too high or too low?
A high threshold might generate false negatives. A low threshold might inflate false positives. You can tune the threshold via validation on known anomalies or by setting a desired detection rate. The reconstruction error distribution for benign vs suspicious data typically helps you pick a threshold.
How would you manage the risk of concept drift?
User behavior evolves. Fraud techniques also evolve. Concept drift can degrade model performance. Incorporate ongoing re-training with recent data. Monitor drift signals, such as distribution changes in feature space or abrupt changes in error rates.
How would you handle extremely large-scale data and real-time inference?
Distribute data ingestion across multiple nodes. Store data in a scalable system that can handle streaming logs. Consider Spark or Flink for distributed feature computation. For inference, use a containerized model service behind a load balancer. Scale horizontally based on traffic. Use asynchronous message queues if needed.
How can you interpret model decisions?
Random Forests and Gradient Boosting can provide feature importance. By comparing average reconstruction errors per feature in autoencoders, you can see which features deviate the most. This helps investigators understand suspicious activity patterns, like unusually high device variety.
How would you address potential user privacy concerns?
Strictly anonymize identifiable information. Only store aggregated or hashed device identifiers. Follow all privacy regulations. Secure data at rest and in transit. Implement access controls to ensure only authorized processes can read logs.
How do you verify the final model's accuracy against real fraud incidents?
Compare model predictions with confirmed fraud cases. Track how many alerts investigators confirm. Evaluate performance metrics monthly or weekly. Collect feedback from false positives and update training sets. Over time, maintain a balanced approach to capturing real anomalies while avoiding user friction.