
ML Case-study Interview Question: Personalized Restaurant Search Using Pairwise Learning to Rank


Browse all the ML Case-Studies here.
Case-Study question
A major food-delivery platform wants to personalize its search results so that when users look for nearby restaurants, they see options aligned with their own past preferences and order history. The platform handles millions of searches daily, and user tastes vary widely. Propose a solution that builds a personalized ranking system using historical user behavior data and restaurant attributes. Explain how you would collect data, engineer features (including user-specific features), choose a model to rank results, handle training at scale, and evaluate performance. Describe how your solution can boost conversions from search to actual orders and reduce the time users spend scrolling through long lists of restaurants.
Proposed Solution
Each user has unique food preferences. Using search logs, order histories, and restaurant data helps in tailoring search outcomes per user. The ranking system uses a learning to rank approach rather than a simple static scoring. Traditional methods that try a single formula like 2*(1/distance) + 1.2*restaurant_rating are inflexible and ignore user-specific signals. A supervised model that learns from clicks and orders is more powerful.
Data Ingestion and Feature Engineering
Transaction logs, clicks on restaurants, and final orders form the backbone of the dataset. Each search result can be labeled by relevance. For example, if a user orders from a restaurant after clicking on it, that restaurant’s relevance label is higher relative to one that was only viewed. Both user-centric features (e.g., how often a user has ordered from a given cuisine, a restaurant’s distance from that user, user’s location context) and restaurant-specific features (e.g., ratings, popularity, price range) appear in the dataset. Storing these features in a large-scale system requires a data pipeline that processes search queries and logs in near-real time or in periodic batches.
Model Approach
Pointwise ranking predicts a relevance score for each restaurant independently and then sorts by that score. Pairwise ranking focuses on getting the order correct. Pairwise ranking often matches the actual goal: ordering the items in a way that aligns with the user’s real preferences. A popular method is LambdaMART, which uses gradient-boosted decision trees to minimize a pairwise loss. The core idea is: if restaurant A is more preferred than restaurant B for a user, the model learns to score A higher than B.
Central Pairwise Ranking Formula
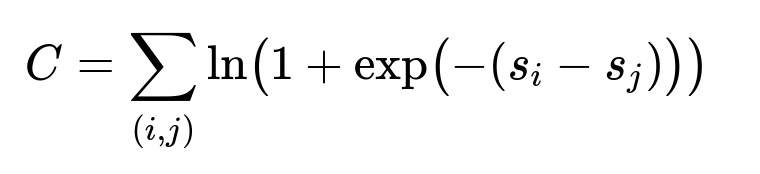
C is the cost function summed over all item pairs (i, j). s_i and s_j are the model’s predicted relevance scores for the respective items. The term inside the log captures the penalty when the model orders a less relevant item above a more relevant item.
Minimizing C makes the model push s_i > s_j whenever item i is truly more relevant than item j. The model learns relevance scores that give correct item orderings for each user.
Implementation Details
A gradient-boosted tree model (such as LambdaMART) is trained on labeled examples. Each training instance consists of one user’s search session containing multiple restaurants, with each restaurant’s features plus a relevance label derived from historical behavior. The model iteratively refines tree splits to produce better ordering. After training, the scoring function is applied to any new search query. The system then ranks candidate restaurants by the predicted score, personalizing results based on each user’s feature values (cuisine tastes, distance, rating preferences, and past orders).
Example Code Snippet
import pandas as pd
import lightgbm as lgb
# Suppose df has columns: user_id, restaurant_id, label, distance, rating, user_cuisine_pref, ...
# label is an integer representing relevance (0, 1, or 2), or derived from click/order data.
train_cols = ['distance','rating','user_cuisine_pref', ...]
train_data = lgb.Dataset(df[train_cols], label=df['label'], group=df['group_size'])
params = {
'objective': 'lambdarank',
'boosting': 'gbdt',
'metric': 'ndcg',
'ndcg_eval_at': [10],
'learning_rate': 0.05,
'num_leaves': 31
}
model = lgb.train(params, train_data, num_boost_round=100)
# model.predict(...) can then be used to get personalized ranking scores
Explanation in simple terms: each row includes relevant features plus a group identifier (group_size or query group). The Lambdarank objective tries to optimize ordering within each group. The result is a model that ranks restaurants higher if they match a user’s preferences and yield higher relevance.
Performance Metrics
Search-to-order conversions and Normalized Discounted Cumulative Gain (NDCG) track how effective the re-ranking is at placing truly preferred restaurants near the top. Observing a rise in search-to-order conversion indicates users found what they wanted faster. A jump in NDCG means the ordering is closer to user relevance. Reduced scrolling and quicker decisions are expected by-products.
Observations
Personalization tends to push restaurants the user has engaged with higher on the list. Users often choose a familiar or favored cuisine if shown quickly. This reduces decision fatigue and confusion. A typical A/B test compares the personalized ranker against a baseline. Significant lifts in conversions and NDCG confirm the model is succeeding in presenting relevant results at the top.
Possible Follow-up Question 1
How do you handle new users who have not placed any orders yet?
Answer: Cold-start users lack order history features. Default to a generic ranking strategy that prioritizes high-rated, popular restaurants near them. Once a user completes even one order, the system updates user-centric features accordingly. Another option is to use collaborative filtering signals: users with shared location or minimal preferences might get initial recommendations from similar user segments. Hybrid approaches combine popularity-based fallback with incremental learning once the user has some interactions.
Possible Follow-up Question 2
How do you prevent the model from over-recommending the same restaurants repeatedly to loyal customers?
Answer: Overfitting to a user’s favorite restaurant can restrict discovery. Penalize repeated recommendations by incorporating diversity-based features or adding a slight negative weight to high-frequency orders from the same restaurant. Track how often a user orders from that restaurant. If it exceeds a threshold, reduce its relevance score. Exposing more variety can sustain user interest and prevent monotony.
Possible Follow-up Question 3
How do you continuously update the model given shifting user preferences and changing restaurant data?
Answer: Retrain in frequent intervals (daily or weekly) on fresh data. Capture new user interactions, restaurant openings/closings, and rating changes. Consider online learning approaches when real-time updates are critical. Incremental training can keep the model from growing stale. Store the newest labeled data in a streaming pipeline and periodically refresh the model so it adapts to emerging trends.
Possible Follow-up Question 4
What are potential pitfalls in using pairwise ranking for this task?
Answer: Pairwise ranking focuses on relative ordering. It does not directly estimate absolute relevance. If training labels are noisy or if there are wide variations in user behavior, the model can find it hard to learn consistent pairwise preferences. Another pitfall arises when there is a heavy class imbalance (many zero-relevance pairs). Mitigation might include sampling strategies or adjusting pair weights. Thorough validation is crucial to ensure the model correctly captures real-world preferences.