
ML Case-study Interview Question: Predicting Email Sentence Attention Using Cost-Value Linguistic Models


Browse all the ML Case-Studies here.
Case-Study question
A leading writing platform wants to show email writers which sentences might receive high or low attention from their readers. The team created a prototype that highlights “high-attention” or “low-attention” sentences using different shades of color. They must measure actual reading behavior and develop an accurate, explainable model that predicts how much time a reader will spend on each sentence. How would you design a solution for this problem, collect data at scale, build and refine a predictive model, and then evaluate its performance?
Be sure to discuss:
How to measure and label attention without intrusive methods.
How to ensure scalability and diversity of participants.
Which features or linguistic signals might be important.
Strategies to handle subjective variance in reader behavior.
The evaluation metrics you would use to score your model.
Approaches to improve model explainability.
Detailed Solution
Problem Restatement
The goal is to predict which parts of an email a reader will focus on. The writing platform wants to highlight high- vs. low-attention sentences in real time. This requires a dataset capturing how people read emails, an attention model that assigns scores to sentences, and a strategy to make the model’s suggestions understandable to end users.
Data Collection Approach
The team needs actual human reading patterns. Tracking eye movement via specialized hardware is accurate but not scalable. They used a custom interface that reveals one sentence at a time while the rest remains blurred. Readers navigate using arrow keys. Time spent on each sentence is captured for attention signals.
Readers receive an incentive to summarize each email. This compels them to read carefully for key details but also move quickly if they want to finish more emails. This simulates how real email readers behave when scanning for intent.
The company aggregated data from multiple readers per email. They normalized reading speeds because individuals read at different rates. This formed a large labeled dataset that maps sentence position to average attention time.
Modeling Strategy
The first model tested a “heuristic” that assumes readers follow an F-shaped pattern from the top to the bottom of a page, giving more attention to the beginning. This helped establish a baseline.
Then they introduced a “cost-value” model. This model estimates how much information (value) a sentence might contain vs. how much work (cost) it takes to read. It ranks sentences by predicted value and cost, then allocates more of a reader’s attention budget to high-value or low-cost sentences. They engineered features such as token complexity, linguistic structures, and frequency of key terms.
Feature Exploration
Computational linguists contributed a wide range of features that capture word frequency, sentence parse depth, reading difficulty scores, and language patterns. They tested more than 40 core linguistic features. Many improved the model’s performance:
High-frequency words can reduce cost, since they are easier to parse.
Complex phrases increase cost, so readers might slow down or skip them.
Certain topic keywords boost perceived value, especially for urgent contexts.
They combined these signals, retrained the model, and reported incremental improvements in accuracy and recall.
Metrics for Evaluation
They measured performance with:
Regression-based metrics like mean absolute error, root mean squared error, and R-squared.
Recall-oriented metrics to avoid false positives on high-attention sentences.
Likelihood-based metrics to give more tolerance in cases where readers themselves exhibit high variability.
They compare predicted attention times y_pred vs. actual attention times y_true. Mean squared error (MSE) is a core metric:
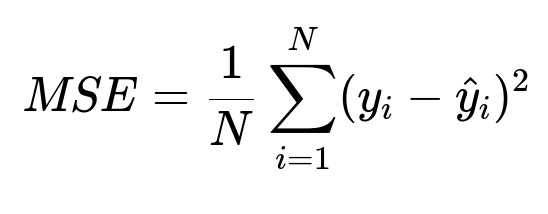
N is the total number of sentences in the evaluation set. y_i is the measured attention for sentence i, and hat{y}_i is the predicted attention.
They also use recall-based metrics to capture how well the model recovers truly high-attention segments. Recall is:

True Positives are sentences correctly flagged as high-attention. False Negatives are sentences that are predicted low-attention but actually have high attention.
They further incorporate likelihood-based metrics for subjective variability. If a sentence has a wide range of observed reading times, the penalty for misclassification is reduced, reflecting the inherent reader-by-reader differences.
Explainability
Writers need a clear reason why certain lines are flagged high or low. A black-box approach could be confusing and less actionable. The cost-value model offers transparency. By examining cost features (complex words, syntactic complexity) vs. value features (keyword presence, rhetorical importance), users can see why the model thinks some sentences will attract more attention.
Implementation Details
A possible pipeline in Python:
import time
# Hypothetical function to measure reading
def measure_reading(email, participant):
sentence_times = []
for sentence in email.sentences:
start = time.time()
# Wait for participant to press arrow key
# ... user presses arrow key ...
end = time.time()
sentence_times.append(end - start)
return sentence_times
# Hypothetical training process
def train_attention_model(features, attention_times):
# features: linguistic and structural features per sentence
# attention_times: observed times or normalized attention scores
# Train a regressor or cost-value model
# ...
trained_model = "CostValueModelTrained"
return trained_model
They gather many reading traces, transform them into per-sentence attention scores, generate features, and train. The final step is to serve a system that, given an email’s sentences, outputs a predicted heatmap in real time.
Handling Subjective Variance
Some people read thoroughly while others skim. Some are non-native speakers. The platform addresses this by:
Collecting multiple readings of each email.
Normalizing each participant’s times.
Creating a distribution of attention for each sentence instead of a single point estimate.
Training a probabilistic model to account for variability.
Future Enhancements
The team wants larger, more diverse datasets and more realistic conditions. They might also incorporate reading comprehension tests to measure which parts truly stuck with the reader. They plan to refine the model to handle user-specific behaviors, such as reading emails from managers in more detail than newsletters.
Potential Follow-up Questions
How would you validate that this sentence-by-sentence reading approach reflects real-world reading behavior?
Real readers glance around, possibly re-read certain paragraphs, or skip around. The experimental setup risks artificially structured reading patterns. A robust validation would involve A/B testing with real emails to see if predicted attention aligns with outcomes like responses or click-through. Collecting partial data from simpler browser-based measurements (like scroll depth or dwell times in a real email client) could further confirm that the controlled study lines up with real-world usage.
It is also useful to run user studies that compare the measured heatmaps to direct recall tests. If readers recall the information in sentences labeled “high attention” more thoroughly, it indicates alignment with real behavior. The writing platform might combine real-time session analytics with the controlled sentence-by-sentence method to strengthen external validity.
How would you handle the cold-start problem where you lack data for certain types of content or new user segments?
One strategy is to rely on strong domain-general linguistic features that generalize well. Even if the system has not been trained on that user’s specific emails, it can still use universal signals such as sentence complexity, keyword frequency, or rhetorical cues. It can then refine predictions over time as new data arrives.
Another approach is transfer learning from existing reading data. If the platform sees a wide variety of emails and reading patterns, a new email category might still be partly captured by previously learned linguistic signals. Over time, incremental updates can fine-tune the model on new segments.
Why do you need multiple metrics (regression, recall, likelihood) instead of just focusing on a single metric?
Each metric highlights different aspects of performance. A regression metric like mean squared error tracks raw error in predicting attention times. Recall emphasizes not missing crucial high-attention sentences. Likelihood-based approaches help account for subjective variability by letting the model be flexible where readers themselves disagree. Focusing on only one metric might produce skewed optimization. Combining these metrics encourages a more balanced model that correctly pinpoints high-attention areas yet remains robust to noisy, subjective outcomes.
What if two readers produce conflicting heatmaps for the same sentence? How does the model decide which attention label to trust?
The model is probabilistic and expects variation. The system collects multiple readings and aggregates them, often by calculating the mean or median attention time. If some readers skip a sentence but others focus on it, the average might be moderate. The model’s training process will consider variance and may reduce confidence in that sentence’s attention score. In practice, the final heatmap might reflect a probability distribution instead of a single absolute label. Some solutions incorporate Bayesian methods or quantile regression to handle conflicting signals and produce a more nuanced prediction.
How would you extend this approach to languages beyond English?
It requires language-specific features. Sentence tokenization, syntactic parsing, and lexical complexity differ across languages. Extending the cost-value approach means re-engineering features to respect each language’s unique morphology and syntax. For example, word frequency distributions differ widely among languages. Localizing the training data is essential, collecting actual reading traces from users of the target language. This ensures the model learns relevant cues for each linguistic context.
How would you mitigate possible biases in this model?
Bias can arise if the dataset overrepresents certain writing styles or user demographics. Some sentences might be labeled consistently low-attention simply because they appear in certain cultural or stylistic contexts. A robust strategy is to sample emails from diverse domains and user groups. Monitoring performance across demographic segments can reveal systematic errors. Techniques such as domain adaptation or fairness constraints can help reduce skew. Regular audits of model outputs can catch biases related to content that the team did not anticipate.
Could you include a personalization layer so the model adapts to each reader's habits?
Yes. The system could track a user’s typical reading speed and known preferences, then adjust the cost-value weighting. For instance, a user who frequently reads technical jargon might find complex words easier, lowering that cost factor. A user scanning for tasks might treat call-to-action words as high-value. Personalization would require an online learning approach or user-level embeddings that update as more reading data arrives. The main trade-off is complexity in storing and maintaining user-specific models at scale.
How would you handle real-time processing in production?
The model needs to run quickly during email composition. Precomputing expensive features (like parse tree generation) could be done asynchronously. The final inference step should be light, possibly using a smaller, optimized model or caching partial results. A typical pattern is to use a microservice with a powerful feature-extraction pipeline in the backend, then store intermediate linguistic representations. When the user types a new sentence, the system retrieves precomputed features and updates the attention score on the fly. Efficient caching strategies and hardware acceleration can ensure minimal latency.
How do you see this technology expanding beyond emails?
It can be applied to any text where predicting reader engagement matters, such as news articles, marketing content, or educational materials. Writers might want to rearrange or simplify high-cost, low-value paragraphs. By highlighting potential “skipped” segments, authors can rewrite them to retain readers. The same approach might help e-readers or online publishing platforms direct user focus or provide simplified summaries for complex passages.