
ML Case-study Interview Question: Learning-to-Rank for Personalized Real-Time Used Car Recommendations


Case-Study question
You are working as a Senior Data Scientist at a used-car e-commerce platform. Millions of users visit the platform each month, and the site has over 10,000 cars listed at any time. The existing system clusters users into broad cohorts based on past interactions and serves a single ranked catalog to each cohort. Leadership wants more granular, user-level personalization that considers detailed user behavior, such as search history, filter usage, impressions, clicks, and wishlists. Build a solution that ranks cars for each user in near real-time, aiming to increase overall engagement and purchase conversions. Describe how you would design this new learning-to-rank system, what data and features you would use, how you would train and deploy the models at scale, and how you would measure success.
Detailed Solution
High-Level Approach
Build a user-level personalization pipeline that creates a user profile capturing each user’s preferences. Replace the previous cohort-based system with a Learning to Rank approach. Analyze user activities like clicks, filters, and searches. Assign relevance to cars based on how well they match individual user preferences. Sort the cars in decreasing order of predicted relevance scores for each user.
Data Collection and Feature Engineering
Collect impressions, clicks, wishlist additions, search queries, filter usage, inspection-report views, and other user events. Aggregate these signals into features:
User behavioral features such as recent click frequencies, time spent viewing car details, repeated focus on certain models or price ranges.
Item (car) attributes including brand, model, price, mileage, body type.
Contextual features like user’s region and device type.
Model Training
Use a Learning to Rank framework that emphasizes correct ordering of items. Compare Pointwise, Pairwise, and Listwise methods. Prefer the Listwise approach for ensuring optimal ordering of the entire list. One effective option is YetiRank in CatBoost to optimize the entire ranked list.
Core Evaluation Metric
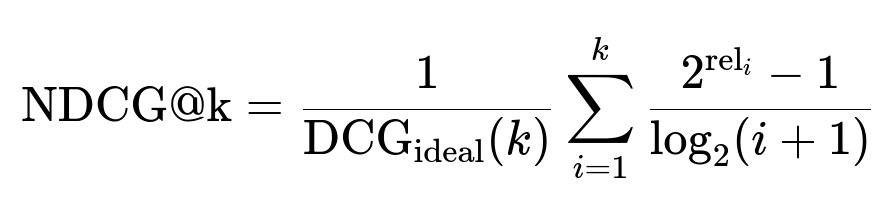
Above, rel_i is the relevance of the item at position i, DCG_ideal(k) is the best possible DCG for the top k positions, and log_2(i+1) discounts lower-ranked positions. NDCG captures both relevance and position of relevant items.
Model Deployment and Real-Time Scoring
Maintain a user-profile store that updates quickly whenever a user interacts with new cars. Perform inference by scoring each user-car pair or a shortlist of candidate cars. Use a queue or pub-sub mechanism to publish these scores for immediate consumption by the listing API. Re-rank the displayed catalog based on up-to-date scores to give a personalized ordering.
A/B Testing and Observed Results
Run an A/B test comparing the new personalized ranking to the older cohort-based approach. Track:
Conversion (e.g., booking initiated per user).
I2V (impressions-to-views ratio).
I2BI (impressions-to-booking-initiated ratio).
In a real deployment, an uplift of around 11% in conversion was observed, with increased I2V and I2BI in higher-ranking positions of the personalized list.
Future Enhancements
Implement online scoring to react instantly to session-level intent. Scale the system to multiple countries by retraining or fine-tuning the model on new location-specific preferences. Keep iterating the model with more user signals and refined feature sets.
Potential Follow-Up Questions
1) How would you handle cold-start users with limited historical data?
Use a fallback strategy. For new users, capture any immediate signals (first few clicks, searches) and merge them with a generic ranking model or a small popularity-based approach. Continuously update the user profile after each interaction.
2) How would you choose a ranking loss function?
Use a listwise loss because it directly optimizes the item ordering rather than predicting an absolute relevance score. In CatBoost with YetiRank, the algorithm internally optimizes for better ordering by focusing on pairwise and listwise comparisons.
3) How do you ensure your model considers user location preferences?
Include geographical features, such as user’s region or city, distance to the car’s location, or region-level preference patterns. The model sees these features and learns location-specific relevance.
4) How can you guarantee low-latency model predictions?
Implement near real-time inference using a streaming pub-sub setup. Pre-compute user embedding vectors or partial model scores. Store them in an in-memory system for quick retrieval. Maintain a horizontally scalable inference service to handle spikes in traffic.
5) How do you tune hyperparameters for CatBoost with YetiRank?
Set up a grid or randomized search over hyperparameters like max_depth, iterations, and learning_rate. Track NDCG@k or a similar ranking metric on a validation set. If your data is large, rely on smaller well-structured validation samples and adopt early stopping to avoid overfitting.
6) How would you tackle interpretability in a Learning to Rank model?
Use feature importance or SHAP values in CatBoost. Examine which features most influence rank ordering. For user-facing explainability, consider simpler global explanations like “prices and model preferences are top drivers for your recommended listings.”
7) How would you confirm that your personalization model generalizes to new geographies?
Retrain or fine-tune on data from each new region. Evaluate with region-specific metrics. Compare to baseline ranking approaches for that region. Confirm consistent gains in conversion and user-engagement metrics.
8) Could you highlight the differences in data pipeline design for offline training vs. real-time scoring?
Offline training uses batch-processed historical data in a data lake. Real-time scoring needs an online pipeline that updates user profiles quickly. Use a queue to publish new user interactions, transform them into incremental features, and fetch these updates to generate fresh ranking scores on demand.
9) How would you deal with slow-moving or stale user preferences?
Introduce time decay in features. Assign higher weight to recent clicks, searches, or views. Decrease the impact of older actions. Implement a rolling window for user actions to let the model reflect any shifts in taste.
10) In production, how would you track errors and ensure stability?
Set up extensive monitoring for inference latency, memory usage, and correctness metrics. Use robust logging for user scoring events. Roll out updates gradually (canary or phased approach), and revert quickly if anomalies arise.
All these details enable an end-to-end user-level ranking system that boosts engagement, guides users to relevant cars, and lifts conversion rates in a scalable fashion.