
ML Case-study Interview Question: Enhancing E-commerce Catalogs: LLMs for Automated Attribute Extraction and Entity Resolution.


Browse all the ML Case-Studies here.
Case-Study question
A major e-commerce platform wants to build a high-quality product catalog for its grocery, convenience store, and alcohol store merchandise. Each item has attributes such as brand, size, organic label, and others. Many items have missing or inaccurate attributes in the raw merchant data. The Company decides to use large language models to extract, tag, and enrich attributes without relying solely on human operators.
They want to build a system that:
Automatically infers product attributes from item names and descriptions.
Identifies new brands to expand their brand taxonomy.
Labels items with specialized tags such as “organic.”
Resolves different merchant SKUs to a unique product entity (entity resolution).
Design a robust approach that addresses these requirements end to end, including any specialized pipelines, data processing techniques, and model or pipeline orchestration. Propose how you would handle scaling, accuracy, and speed. Suggest how to avoid relying too heavily on manual data labeling.
Detailed solution
Overview
LLMs can interpret unstructured text with minimal or no labeled training data. The system can ingest product information (title, description, merchant metadata, images) and derive attributes such as brand, size, and dietary tags. Building a flexible pipeline ensures that new product categories can be incorporated with minimal effort.
Brand Extraction
Operators used to add new brands manually, which was error-prone and slow. The Company automated brand extraction. An in-house brand classifier first attempts to match SKUs to known brands. If it cannot confidently do so, an LLM identifies the most likely brand from the product title or additional data. A second LLM checks for near-duplicates in an existing knowledge graph of brands. If the brand is truly novel, it is added to the brand taxonomy. Re-training the brand classifier with these new annotations lets the pipeline continuously improve.
Organic Label Tagging
The Company needed a reliable way to detect which SKUs are organic. A string-based filter flags items with an explicit “organic” mention. But many SKUs lack a direct mention or have typographical errors. An LLM infers the label from partial data, such as merchant inputs or recognized text from product images. Where further information is needed, the system uses an LLM agent to search online references. A second LLM then decides whether the search results confirm the item is organic. This process balances coverage and precision.
Generalized Attribute Extraction
The system must recognize attributes like vintage, flavor, or other domain-specific details. Data for these attributes is sparse. The Company employed retrieval augmented generation to reduce labeling overhead. The pipeline retrieves example SKUs with known attributes using embeddings and approximate nearest neighbors. It supplies these examples as prompts to GPT-4 to label a new SKU’s attributes. This output populates a training set for fine-tuning an internal model. This jump-starts coverage for new categories without massive labeling campaigns.
Entity Resolution
Entity resolution merges identical products sold by different merchants. Each pair of SKUs must match on all relevant attributes. The pipeline extracts attributes from each SKU using the LLM-based approach above. A final comparison checks if they match exactly or meet threshold similarity. Accurate entity resolution boosts features like global product listings and sponsored ads.
Embedding Similarity
The pipeline often uses embeddings. A common approach is to compute cosine similarity:
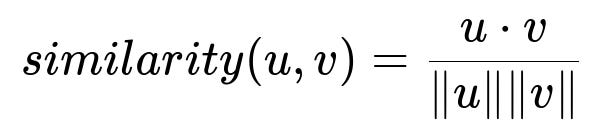
Here u and v are embedding vectors for two pieces of text, such as item titles. A higher similarity indicates that the items likely refer to the same product or share relevant context.
Implementation Details
A typical workflow queries an in-house service for brand classification. If a confidence threshold is not reached, an LLM uses a prompt instructing it to extract the brand from the given SKU title. Another LLM call checks potential duplicates. For attribute tagging, the pipeline tries exact keyword matching first, then LLM reasoning, and finally an LLM agent for external data retrieval. Collected annotations feed back into model fine-tuning, ensuring continuous improvements in accuracy.
Scalability and Speed
LLM inference can be more expensive than simpler rules-based or classical ML approaches. Caching repeated inferences, batch-processing large data sets, and carefully tuning timeouts for agent-based queries control operational costs. Parallelizing requests with asynchronous calls speeds up throughput, and embedding-based retrieval ensures LLM queries only happen when absolutely needed.
Quality Control
Setting high precision thresholds, random sampling, and partial human audits can catch anomalies. A second LLM pass can help detect contradictions. During deployment, new product expansions can use the same pipeline, adjusting prompts as needed to address category-specific attributes like “vintage” for wine.
How would you handle noisy or inconsistent product titles?
A robust pipeline includes a data normalization step. Standardizing text (lowercasing, removing punctuation) limits the effects of erratic strings. Tokenizing the text into meaningful chunks ensures consistent input to an LLM. Mispelled brand names can often be corrected by string distance measures or by letting an LLM infer the correct brand with context. If a product has multiple references (e.g., synonyms for flavors), embeddings can unify them.
How do you ensure minimal reliance on manual annotations?
Strong prompt engineering on top of LLMs and retrieval augmented generation reduces labeled data requirements. Searching relevant examples from a small set of verified SKUs cuts annotation time. The pipeline also automatically reuses LLM outputs to fine-tune a smaller in-house model. This synergy pushes each iteration to rely less on humans. Humans only perform final spot-checks or validations of uncertain cases.
How do you choose between first-party text data versus product images?
Text data might be incomplete or have many abbreviations. Images tend to be more consistent in showing brand logos or “organic” icons. When text data is inadequate, a multimodal LLM can process both text and images (via OCR). Extracted text from the product label or packaging can be combined with the original item title. By comparing them, the LLM can reconcile any inconsistencies. Using images mitigates the risk of merchant-provided text that is out-of-date or inaccurate.
How would you handle model updates if new product categories or attributes arise?
Fine-tuning an internal model is simpler with additional annotated SKUs and new prompts. The retrieval-based approach helps bootstrap labels for novel attributes with minimal manual tagging. You can create new prompt templates for categories that exhibit specialized attributes, such as “vintage” for wines or “material” for clothing. Over time, a unified pipeline can handle new categories by introducing fresh prompts and embedding examples that reflect the new domain.
What if the LLM sometimes invents non-existent brand names?
An LLM can hallucinate. A second pass verification step or a knowledge-graph-based similarity check guards against that. When the pipeline sees a new brand name, it checks the brand knowledge graph for close matches or semantically similar names. A human or a secondary LLM can confirm if it is truly new or fabricated. This multi-step validation controls brand duplication or hallucination.
Could you show how you might implement a brand extraction prompt?
A simple Python snippet could look like this:
def extract_brand(llm_client, item_name):
prompt_text = (
"You are a product attribute extraction agent. "
"Given the item name: '" + item_name + "'. "
"Extract the brand. If not certain, say 'Unknown'."
)
response = llm_client.generate(prompt_text)
return response.strip()
This snippet sends a direct prompt to the LLM. If the brand is ambiguous, the pipeline logs “Unknown” and possibly retries with additional data. Another pipeline step checks whether the brand is already in the knowledge graph.
How would you prevent re-adding the same brand?
Duplicate detection compares the extracted brand name to existing names using embeddings or string distance. The pipeline also uses an LLM to see if the new brand closely matches a known brand. If the brand is distinct, the system creates a new entry. If it is a match, the pipeline links the SKU to that existing brand entity.
Could you clarify the fine-tuning process for your in-house model?
The labeled data from LLM outputs forms a training set. The training pipeline includes tokenization, splitting into train/validation sets, and running a standard cross-entropy loss on each token for classification tasks. Over time, the model sees enough examples to learn brand identification or attribute tagging. This approach offloads many simple cases to the in-house model, using the LLM only for ambiguous instances.
How do you confirm that your attribute extraction improves shopping experiences?
Metrics such as click-through rates, conversion rates, and user retention can be tracked for pages featuring better-labeled items. Proper brand tagging and organic labeling can yield more accurate recommendations. Fewer returns or mismatches in deliveries also indicate better data accuracy. A/B testing compares new attribute-based search or recommendations against a control group. Positive lifts validate the pipeline’s effectiveness.