
ML Case-study Interview Question: Hotel Sentiment & Topic Modeling from Social Media using Machine Learning


Case-Study question
A major hotel chain wants to analyze the public online text people post about its brand on social media platforms. They have historical data from networks like Twitter, Facebook, and Reddit. They aim to measure customer sentiment and uncover common problems or recurring themes. They also want to route identified issues to the correct department. Propose a strategy for collecting and cleaning the data, transforming the text into useful features, and building machine learning models to perform both sentiment analysis and topic classification. Show how you would use this analysis to drive brand improvements.
Proposed solution
Overview
The hotel chain has a large volume of unstructured text data from multiple sources. Each post is public, so they can monitor user comments about their brand. The goal is to classify overall sentiment and discover key topics. This informs actions like fixing negative experiences and improving overall brand perception.
Data Preparation and Storage
Text data is stored in a database containing public posts. Data is messy, so it needs cleaning. Tasks include fixing text encoding, removing spam or non-relevant entries, and filtering out duplicates.
Text Preprocessing
Text is inconsistent. Preprocessing includes stripping HTML tags, removing stopwords, and performing lemmatization. A step like lemmatization normalizes words, which helps reduce dimensionality and keep focus on main tokens.
Feature Representation (Vectorization)
Each piece of text must be converted into a numerical feature vector for machine learning. Basic approaches include bag-of-words, n-grams, and TF-IDF. TF-IDF is common for weighting rare but important terms more highly.
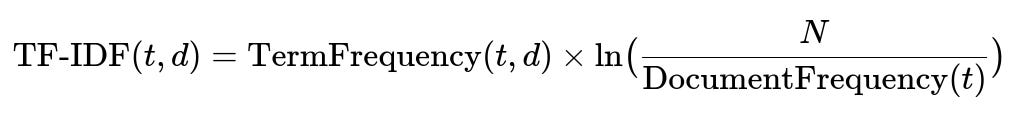
Here, TermFrequency(t,d) is the count of term t in document d. N is the total number of documents in the corpus. DocumentFrequency(t) is the number of documents containing term t. log(...) is the natural logarithm.
Model Building for Sentiment Analysis
The vectorized data is fed into classification models. Logistic regression and support vector machines are standard baselines. Random forests and neural networks can also capture non-linear patterns. Off-the-shelf libraries like NLTK, TextBlob, or pretrained transformer-based models (from sources like Hugging Face) can be adapted and fine-tuned for sentiment classification.
Model Evaluation
Performance is measured with metrics like precision, recall, F1-score, and by examining a confusion matrix. Accuracy alone can be misleading for imbalanced data. Precision and recall show how often positive or negative reviews are correctly classified.
Topic Classification
Beyond sentiment, the chain wants to group posts by themes. Clustering algorithms like k-means group posts into natural clusters. Latent Dirichlet Allocation (LDA) is another method that views each document as a mixture of latent topics. This helps the chain identify reviews about check-in experience, room service, or amenities.
Business Impact
Real-time alerts can inform the chain about negative trends. They can fix frequent issues, improve customer satisfaction, and mitigate brand damage by reaching out to customers who posted negative feedback. Reporting different clusters to relevant departments supports faster resolution.
Follow-up question: Why is it worth going beyond reviews on sites like Tripadvisor or Google Reviews?
Social media platforms can magnify smaller issues into major brand crises. Viral posts can significantly influence public perception. Monitoring these sources captures real-time feedback from a broader audience. Handling these complaints promptly demonstrates responsiveness, which can convert dissatisfied guests into loyal customers.
Follow-up question: How do you handle highly imbalanced sentiment data when most posts are neutral or positive, and only a small fraction is negative?
Class imbalance can degrade model performance. Training with balanced subsets or oversampling negative examples can help. Techniques like SMOTE (Synthetic Minority Over-sampling Technique) create synthetic samples for the minority class. Custom loss functions or class weighting in algorithms like logistic regression or random forests can also balance the influence of each class.
Follow-up question: Why might you prefer a simpler classical model like logistic regression over a deep learning approach?
Classical models are easier to train and interpret when data volume is moderate or labeled data is limited. Logistic regression with strong regularization can perform well in many NLP tasks, especially when combined with powerful vector representations. More complex models might overfit or require extensive hyperparameter tuning. Starting with a simpler model is often faster and ensures a baseline.
Follow-up question: How do you adapt or fine-tune a pretrained transformer-based model if you choose a deep learning approach?
Obtain a large pretrained language model like BERT or a variant. Replace the final classification layer with a new layer matching the number of sentiment classes. Freeze the earlier layers initially, and fine-tune the top layers on your labeled sentiment data. Gradually unfreeze more layers if necessary, carefully adjusting the learning rate. Monitor metrics on a validation set to prevent overfitting.
Follow-up question: How might you evaluate the quality of the topic modeling results?
Topic coherence measures can assess how semantically related the top words in each topic are. Manual inspection is also common; domain experts review representative words from each cluster or LDA topic to confirm meaningful groupings. If the chain sees coherent themes (front desk, housekeeping, etc.), then the topic model is performing well. If there is overlap or confusion in the discovered topics, hyperparameters like the number of clusters or topics may need adjusting.