
ML Case-study Interview Question: Dual Contrastive Embeddings for Balanced Two-Sided Marketplace Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
A large-scale online platform hosts a two-sided marketplace with millions of active job-seekers and millions of active job postings. The goal is to create a recommendation engine that connects both sides efficiently. The platform observes diverse data from employers (thumbs up/down), job-seeker activities (applications, searches), and textual attributes (job descriptions, resumes, titles, skills, etc.). The data exhibits extreme long-tail distributions, constant entity churn, and noisy free-text with domain-specific jargon. Propose a robust machine learning system that produces relevant, balanced recommendations for both sides. Show how you would design and train your approach to handle zero-shot predictions for unseen entities, incorporate feedback signals from both sides, and keep inference scalable. Provide your reasoning, architecture choices, and any supporting technical details. Explain how you would ensure that the system optimizes for both job-seeker relevance and employer satisfaction.
Detailed Solution
Problem Framing
Training a model to recommend jobs to job-seekers requires representing both sides of the marketplace. The data is sparse, non-stationary, and includes free-text with non-standard formats. Embedding representations help tackle these issues by converting textual and structured attributes into dense vectors. Embeddings also allow scalar dot products at inference for scalability, rather than heavier per-request models.
Encoder Strategy
Pre-trained encoders capture same-entity semantic similarities. One encoder models job-to-job similarity. Another encoder models resume-to-resume similarity. These encoders use large corpora of implicit user interactions and explicit employer thumbs-up/down signals.
The job encoder learns representations of job postings. Co-applied jobs are treated as positive pairs, while random pairs are negatives. The resume encoder learns representations of candidate resumes. Two resumes that receive a thumbs-up on the same job are considered similar, while a thumbs-up vs thumbs-down pair is dissimilar. Triplet loss is effective here, particularly because many job postings contain far more negative feedback samples than positive ones.
Combined Architecture for Cross-Entity Inference
A downstream model learns to align job-seeker embeddings with job embeddings. The job-seeker side uses:
The pre-trained resume embedding.
A time-based encoder for recent activities, such as search queries or job interactions, each mapped through the same job encoder or a separate query encoder.
A feed-forward layer merges the static resume encoding with the dynamic interaction-based encoding.
This merged job-seeker representation is dot-producted with the pre-trained job embedding to generate a match score.
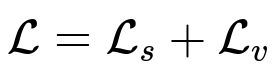
In text:
L_s is a contrastive term sampling jobs for each job-seeker to ensure relevant matches.
L_v is a contrasting term sampling job-seekers for each job to balance employer objectives.
Symmetrizing loss terms avoids bias toward only one side. Sampling negative pairs from the entire corpus captures better coverage, reduces repetitive or in-batch bias, and helps the model learn zero-shot generalizations.
Practical Example
Below is a simplified Python snippet showing how a training step for the job-seeker side might be organized. Explanations follow.
import torch
import torch.nn as nn
import torch.nn.functional as F
class JobEncoder(nn.Module):
def __init__(self, vocab_size, embed_dim):
super(JobEncoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.linear = nn.Linear(embed_dim, embed_dim)
def forward(self, job_tokens):
x = self.embedding(job_tokens).mean(dim=1)
x = self.linear(x)
x = F.normalize(x, p=2, dim=1)
return x
class SeekerEncoder(nn.Module):
def __init__(self, resume_embed_dim, activity_embed_dim, hidden_dim):
super(SeekerEncoder, self).__init__()
self.resume_linear = nn.Linear(resume_embed_dim, hidden_dim)
self.activity_linear = nn.Linear(activity_embed_dim, hidden_dim)
self.final_linear = nn.Linear(hidden_dim, hidden_dim)
def forward(self, resume_embed, activity_embed):
r = self.resume_linear(resume_embed)
a = self.activity_linear(activity_embed)
merged = r + a
merged = self.final_linear(merged)
merged = F.normalize(merged, p=2, dim=1)
return merged
# forward pass with dual-contrastive loss
def dual_contrastive_loss(seeker_embs, job_embs):
# L_s: fix seeker_embs, differentiate over job_embs
logits_s = torch.matmul(seeker_embs, job_embs.t())
labels_s = torch.arange(len(seeker_embs)).to(seeker_embs.device)
loss_s = F.cross_entropy(logits_s, labels_s)
# L_v: fix job_embs, differentiate over seeker_embs
logits_v = torch.matmul(job_embs, seeker_embs.t())
labels_v = torch.arange(len(job_embs)).to(job_embs.device)
loss_v = F.cross_entropy(logits_v, labels_v)
return loss_s + loss_v
This structure shows separate encoders (conceptually referencing your pre-trained job encoder and combined job-seeker encoder) and a dual contrastive loss. The cross-entropy usage approximates a softmax-based contrastive term, with rows and columns reversed for each side.
Zero-Shot Adaptability
Representations come from generic text or attribute embeddings, not from a closed set of IDs. New job titles or new resumes can be mapped without retraining the entire network. Pre-trained text-processing layers handle domain-specific slang or creative job titles. Training updates can incorporate fresh patterns.
Large-Scale Inference
Dot products between normalized embeddings scale well. Approximate nearest-neighbor indices can accelerate job retrieval for each job-seeker. Similar methods can retrieve candidate sets for an employer. The system can keep up with huge real-time traffic.
Follow-up Questions
How would you handle the long-tail job titles when training the job encoder?
Training data is skewed. Many titles have few samples. Oversampling and a shared embedding vocabulary for text tokens help. Data augmentation from synonyms or domain expansions helps. Subword tokenization frameworks (for instance, Byte Pair Encoding) mitigate rare-word issues. Embedding-based approaches handle new combinations of rare tokens. Pre-trained language models offer robust representations for unusual job titles. Frequent re-training or fine-tuning ensures rare classes get updated representation.
Why does focal loss help for job-pair encoding, and how would you modify it?
Focal loss focuses on hard misclassified pairs by reweighting easy examples. This prevents the model from becoming overconfident with abundant easy positives. Including a tunable gamma parameter adjusts how quickly weighting decays on well-classified examples. To implement it, multiply the standard cross-entropy term by (1 - p_t)^gamma, where p_t is the probability assigned to the correct class. The model then allocates more emphasis on challenging examples.
How do you ensure balanced optimization for the platform’s goals, not just one side’s preferences?
Symmetry in the loss function addresses each side’s objective. The job-seeker loss predicts which jobs a candidate prefers. The job-loss predicts which candidates a job might attract. Weighted sums can adjust emphasis if business goals require. One can also incorporate secondary terms that reflect global constraints, such as coverage or fairness across different categories of users.
How would you maintain real-time updates for the candidate’s recent activities and job statuses?
A streaming or micro-batch approach can be used. Resume embeddings remain static, but activity-based states update on fresh interactions. A queue or event-driven pipeline continually ingests new signals. A feature store can hold these incremental features. The job-seeker embedding then recalculates at short intervals or on-demand. For jobs, indexing pipelines can recalculate job embeddings upon significant changes in their data or after new descriptors arrive.
How would you deploy this system in practice at large scale?
A dedicated service hosts both job and candidate encoders. Embeddings are precomputed and cached. At request time, a fast approximate nearest-neighbor search retrieves top matches. Jobs or candidates can be periodically re-embedded with new data. A streaming pipeline handles partial model updates, especially for embedding layers. Automated A/B testing monitors metrics such as click-through rates, apply rates, and satisfaction. Monitoring ensures that system drift or data distribution shifts trigger re-training.
How would you extend it with Graph Neural Networks?
A GNN can incorporate multiple entity types in a single embedding space. Entities become nodes, and interactions become edges. Additional signals (rating edges, search edges, application edges) can be learned simultaneously. This captures higher-order relationships among job-seekers, jobs, and attributes. Convolution-like passes aggregate neighbor information. The final embedding can be used for the same similarity-based recommendation. This unifies everything in a single architecture rather than separate encoders.
How do you handle textual queries in searches that do not map to known jobs?
A separate text-based encoder for search terms can be trained. Tokenize the query, represent each token, and aggregate them, possibly via attention. Weighted self-attention helps highlight crucial terms. A pre-trained model for search tokens improves context understanding. This search embedding can be aligned with the job embedding space. In zero-shot scenarios, unusual queries still produce meaningful embeddings. The search-based signal integrates with the final job-seeker vector to reflect their real-time interests.