
ML Case-study Interview Question: Scalable Grocery Demand Forecasting with Hybrid Heuristics and Deep Networks


Browse all the ML Case-Studies here.
Case-Study question
A large-scale online grocery platform wants to improve demand forecasting for its items. They aim to reduce wasted stock while maintaining high product availability. Some retailers on their platform lack historical data, so heuristic methods are initially used. Once data becomes available, they transition to machine learning models, including feed-forward neural networks and advanced sequence-to-sequence deep networks. They also want to incorporate factors like new product launches, promotions, seasonal shifts, and global events. How would you design a complete solution that addresses cold-start scenarios, scales to millions of daily forecasts, and achieves human-level accuracy?
Provide:
A clear plan for how to handle new retailers or products with no historical data.
An explanation of how to integrate heuristics, feed-forward networks, and sequence-to-sequence architectures into a single pipeline.
Strategies to adapt to rapidly changing external factors while maintaining accuracy.
Methods to handle uncertainty estimation, so the system can decide how aggressively to optimize for either stock reduction or availability.
Details on practical implementation, including infrastructure and model deployment.
Detailed Solution
Heuristic Phase
Heuristic solutions use rolling averages of recent sales and checkout orders. They work immediately even when historical data is sparse. They rely on simple calculations of typical demand over the last few days or weeks. They keep short-term forecasts aligned with real-time checkout data, ensuring near-term accuracy.
Feed-Forward Neural Network Phase
After accumulating some sales history, a feed-forward neural network learns patterns and weighted combinations of those heuristic features. Each product’s daily demand, rolling averages, recent checkout data, and other signals become inputs to the model. The model trains on past forecasts vs. actual sales. Gradients push the network to assign optimal importance to each input. This outperforms fixed heuristics because the network refines its weights continually as more data arrives.
Sequence-to-Sequence Deep Network Phase
External factors (promotions, seasonality, unforeseen global events) drive abrupt changes in demand. A sequence-to-sequence (seq2seq) network with recurrent or attention-based mechanisms captures longer historical patterns. It generalizes across all products by learning typical shapes of demand curves. It memorizes relevant patterns and forgets irrelevant noise. It projects future demand for each product while considering events such as price discounts or holiday seasons. This approach handles both short-term spikes and long-term trends.
Core Loss Function
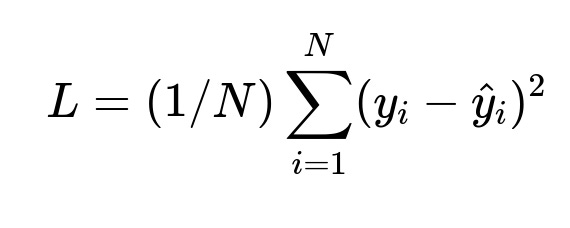
N is the number of training examples. y_i is the actual demand for the i-th data point. hat y_i is the predicted demand. The network trains to minimize this loss, which pushes forecasts to align with true sales volumes.
Transfer Learning for New Retailers
A general seq2seq model trained on aggregated data from existing retailers learns universal demand patterns. When a new retailer joins, the model parameters serve as a starting point. Fine-tuning on the new retailer’s emerging sales data tailors the model to local demand. This shortens time-to-accuracy, so the platform quickly moves beyond heuristics.
Uncertainty Estimation
A forecasting system rarely has perfect foresight. Modeling predictive distributions or using Bayesian layers or Monte Carlo dropout in the network quantifies uncertainty. Products with large forecast variance get buffer stock, balancing wasted inventory with potential demand. Products with stable forecasts carry smaller buffers. This helps optimize the trade-off between availability and overstock.
System Scale
Millions of daily forecasts need efficient computation pipelines. A cloud-based microservices architecture, combined with distributed training on GPU clusters, handles large-scale training. Schedulers trigger incremental retraining or fine-tuning as new data flows in. Scalable streaming frameworks process real-time signals from checkouts. Model deployment uses container orchestration for robust, fault-tolerant inference.
Python Code Snippet (Illustration)
import tensorflow as tf
def simple_seq2seq_model(input_shape, hidden_units):
encoder_inputs = tf.keras.Input(shape=input_shape)
encoder_lstm = tf.keras.layers.LSTM(hidden_units, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_inputs)
decoder_inputs = tf.keras.Input(shape=input_shape)
decoder_lstm = tf.keras.layers.LSTM(hidden_units, return_sequences=True)
decoder_outputs = decoder_lstm(decoder_inputs, initial_state=[state_h, state_c])
dense_layer = tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(1))
outputs = dense_layer(decoder_outputs)
model = tf.keras.Model([encoder_inputs, decoder_inputs], outputs)
model.compile(optimizer="adam", loss="mse")
return model
This seq2seq model uses two LSTM layers: one encoder and one decoder. The encoder encodes historical demand sequences into hidden states that guide the decoder. The decoder then predicts the future demand steps. This architecture handles variable-length sequences and captures complex temporal dependencies.
Implementation Summary
Heuristics bootstrap forecasts at launch. A feed-forward network refines short-term trends. A seq2seq network handles longer horizons and captures changing external factors. Transfer learning accelerates ramp-up for new retailers, and uncertainty estimation balances inventory decisions.
Follow-up Question 1: How would you handle completely new items with no sales history?
A feature-based similarity approach replaces direct sales data. One technique is to cluster existing products by attributes such as category, shelf-life, or brand. The new item is slotted into the cluster that best matches those attributes. A pre-trained model, already familiar with typical demand patterns for similar items, produces an initial forecast. As sales data accrues, the model updates or fine-tunes in real-time to improve accuracy. This avoids relying solely on naive heuristics.
Follow-up Question 2: How would you integrate global or unusual events (e.g. pandemics or extreme weather) that shift customer behavior unpredictably?
External events become exogenous features fed into the model’s input vectors. This can include indicators such as “pandemic_active = 1,” or macro-level signals like daily infection rates or weather forecasts. The seq2seq model allocates attention to these inputs if they correlate strongly with demand changes. Abrupt shifts in the data cause higher loss in the short run, so the model’s training pipeline updates rapidly to capture new patterns. Continuous learning or online training helps the system adapt without fully retraining from scratch.
Follow-up Question 3: How would you ensure that your forecasting pipeline is robust and reliable under production workloads?
Observability and resilience strategies protect the pipeline. Monitoring tracks metrics like forecast error, system latency, and data quality. Alerting triggers retraining or rollback procedures when errors exceed thresholds. Fault tolerance is built by replicating critical services and storing check-pointed models. Continuous integration and deployment (CI/CD) ensures new models pass regression tests before release. Canary deployments test a new model’s forecasts on a small fraction of products before scaling globally.
Follow-up Question 4: How do you decide how aggressively to prioritize availability vs. stock reduction?
Business objectives govern the cost function for stock-out vs. overstock. A cost-sensitive approach modifies the loss function or the post-processing of forecasts. If availability is paramount, retailers accept higher inventory overhead. If cost-cutting is crucial, they scale back final forecasts by an uncertainty margin to avoid large surpluses. Weighted scoring guides the model to balance these factors. Practical usage involves “safety-stock” rules or percentile-based predictions (e.g., p90 or p95 forecast) to cover typical demand fluctuations.
Follow-up Question 5: How do you handle shifting data distributions caused by seasonality or changes in consumer trends?
Active learning and rolling retraining processes keep models updated. Training sets frequently slide forward in time, so the model re-learns with new data. Seasonal or cyclical signals feed into the model as time-based features (day-of-week, month-of-year). If a major trend shift occurs, the system triggers an accelerated training cycle. Adaptive optimizers (e.g., Adam or RMSProp) update weights faster during major transitions. Offline performance tests confirm the model can handle scenarios where historical data differs significantly from current conditions.