
ML Case-study Interview Question: Blending Neural CF & Response Prediction for Personalized Course Recommendations


Browse all the ML Case-Studies here.
Case-Study question
You are building a personalized course recommendation engine for an online learning platform. The system provides course recommendations based on both short-term explicit engagement signals (clicks, bookmarks) and longer-term, deeper engagement signals (course watch history). The goal is to serve relevant course recommendations at scale to millions of learners who have varied backgrounds and unique preferences. You have detailed user features (skills, industries, etc.) and course features (difficulty, category, skills, etc.), as well as a rich history of how users interact with different courses. You must design, train, and deploy a recommendation solution that can be continuously updated and can handle both the sheer volume of data and the need for personalized ranking. How would you approach this problem in a production environment, ensuring that the solution captures both the long-term behavior from course watch time and the short-term signals from clicks and other forms of explicit feedback?
Detailed solution
Overview of the approach
Use two complementary models: a Neural Collaborative Filtering model that relies purely on historical watch data, and a Response Prediction model that combines user features, course metadata, and explicit click-based labels. Combine (or blend) both models to provide final recommendations. The Neural Collaborative Filtering model captures the deeper engagement patterns from watch history. The Response Prediction model captures immediate engagement behaviors and the role of specific learner and course features.
Neural Collaborative Filtering
Train a two-tower deep neural network where one tower represents learners and the other tower represents courses. Represent each learner by a sparse vector indicating courses watched within a certain time window. Represent each course by a sparse vector encoding its similarity with all other courses, computed from co-watch patterns.
Pass both vectors through multiple fully connected layers, narrowing down the layers in a tower-like structure. Produce a learner embedding and a course embedding. Feed these embeddings into an output layer that yields a ranking score representing how likely a particular learner will watch a particular course. Train this model using binary labels (1 for a relevant watch, 0 for no watch), ensuring that training data omits any future watch information. Once trained, compute embeddings for all courses and for the target learner. Rank all courses according to the predicted score and pick the top K.
Response Prediction
Use a Generalized Linear Mixture Model that estimates three sets of model coefficients: a global fixed-effect model, a per-learner model, and a per-course model. Each set of coefficients captures different patterns in the data. Feed learner profile features (skills, industry, etc.) and course attributes (category, difficulty, etc.) into the model as inputs. Train with explicit clicks as positive labels to learn how user features and course attributes influence immediate engagement.
Incorporate watch time signals by assigning higher weights to training instances (click events) where watch time is longer. This weighting scheme influences the loss function so that clicks leading to longer watch sessions contribute more to parameter updates.
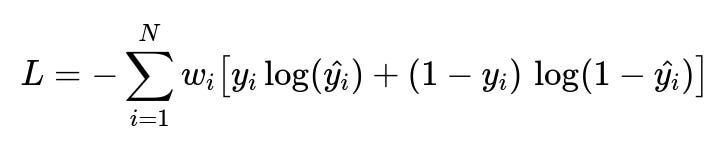
Here, N is the total number of training instances, y_i is the label for instance i (1 if clicked, 0 if not), and hat{y_i} is the predicted probability of a click. The term w_i represents the importance weight derived from watch time for instance i. A higher w_i means the instance is more influential in shaping the model parameters.
This approach allows the model to learn from explicit clicks while factoring in deeper engagement. A short click with minimal watch duration has a smaller weight, whereas a click followed by a long watch session has a larger weight.
Putting it all together
Generate candidate recommendations for each learner by running the Neural Collaborative Filtering model. Compute the predicted scores from the Response Prediction model for each candidate. Blend both scores, possibly using an ensemble or weighted average, to produce a final ranking that captures both deeper watch patterns and near-term engagement signals.
Example code snippet for the Neural CF portion
import tensorflow as tf
# Suppose num_courses is total courses and embed_dim is embedding size
# Learner input placeholder (sparse course watch history)
learner_input = tf.keras.layers.Input(shape=(num_courses,), name="learner_input")
# Course input placeholder (sparse course-similarity vector)
course_input = tf.keras.layers.Input(shape=(num_courses,), name="course_input")
# Learner tower
learner_x = tf.keras.layers.Dense(512, activation='relu')(learner_input)
learner_x = tf.keras.layers.Dense(256, activation='relu')(learner_x)
learner_embedding = tf.keras.layers.Dense(embed_dim, activation=None, name="learner_embedding")(learner_x)
# Course tower
course_x = tf.keras.layers.Dense(512, activation='relu')(course_input)
course_x = tf.keras.layers.Dense(256, activation='relu')(course_x)
course_embedding = tf.keras.layers.Dense(embed_dim, activation=None, name="course_embedding")(course_x)
# Compute dot product for final score
dot_product = tf.reduce_sum(tf.multiply(learner_embedding, course_embedding), axis=1, keepdims=True)
# Model
model = tf.keras.Model(inputs=[learner_input, course_input], outputs=dot_product)
model.compile(optimizer='adam', loss='binary_crossentropy')
# Train with (learner_input, course_input) and binary labels
# model.fit([X_learner, X_course], y_labels, epochs=..., batch_size=..., validation_split=...)
This snippet shows a basic structure for the two-tower network. The final dot product yields a single score. In practice, store the trained embeddings for fast lookup and scoring in production.
Follow-up Question 1
How do you handle cold-start scenarios where new learners or new courses have little to no historical watch data?
Explanation
Rely on the Response Prediction model for cold-start users. This model does not require a long watch history; it uses user profile features (skills, industry). It can generate recommendations purely from user features. For newly introduced courses, rely on course metadata features (topic category, difficulty, targeted skill). The mixture model structure in the Response Prediction model learns course-level coefficients even when course watch data is sparse by sharing information across similar courses. Another approach is to initialize new course embeddings in the Neural CF model using related courses. As watch data accumulates, embeddings become more refined.
Follow-up Question 2
When merging the Neural Collaborative Filtering model and the Response Prediction model, how would you tune the ensemble?
Explanation
Fit both models independently, then blend their outputs. Try a weighted combination of the two scores. Optimize these blending weights using a small validation set. Use a grid search or a simple line search over weights. Measure offline metrics such as AUC for watch prediction or top-K recall of engaged courses. Evaluate online with A/B tests, tracking engagement metrics. Adjust the blend for different segments, since some groups may respond more to deeper watch signals than to click signals.
Follow-up Question 3
What are the trade-offs of using watch time as a weight instead of a label in the Response Prediction model?
Explanation
A direct label approach might treat watch time as a regression target. This can be tricky, because watch time can be very skewed and may not map well to standard regression losses. Weighing a binary click label by watch time keeps the training target simple (click versus no click) but still encodes deeper engagement. This scheme also avoids complexities with regressing on extremely varied watch durations. The trade-off is that weighting might be less direct than a fully specialized watch-time regression, but it tends to be more stable in large-scale production systems.
Follow-up Question 4
Why do you need separate embeddings for courses, instead of a single embedding shared across all items?
Explanation
A single shared embedding forces every item type to compete in the same space, losing the flexibility to capture item-specific nuances. A dedicated course embedding space permits more fine-grained representation, where each dimension specifically learns co-watch and topic-based relationships among courses. This approach also lets you reuse course embeddings for related tasks such as “similar course” retrieval. If you forced everything into one embedding, you risk losing interpretability and clarity for item-to-item comparisons.
Follow-up Question 5
How can attention-based models enhance the Neural Collaborative Filtering approach?
Explanation
Apply an attention mechanism over the user’s past course interactions. Assign higher attention weights to recently watched or thematically relevant courses. This helps the learner representation capture short-term or session-based interests more effectively. Attention also identifies which watched courses most strongly influence the user’s next watch decision. This approach outperforms naive averaging of all watched courses. Integrate it by inserting attention layers before the fully connected layers in the learner tower.
Follow-up Question 6
Which metrics would you monitor in offline experiments and in production?
Explanation
Use top-K recall or precision at K for offline experiments. Measure how many of the courses that a user truly engages with appear in the top K predictions. Track AUC and log loss for classification-based tasks. Track engagement-based metrics in production: overall watch time, percentage of recommended courses watched, and any business-critical success metrics. Run online tests (A/B tests) to validate that the new recommendation approach improves real-world engagement.
Follow-up Question 7
Why is it essential to avoid future data leakage in training the Neural CF model?
Explanation
The objective is to predict future engagement based on past engagement. If the model sees watch data from the future while training, it learns an unrealistic pattern that cannot generalize when serving real-time recommendations. It overfits by leveraging knowledge not actually available at prediction time. Restricting the training process to only the watch history that occurred before the label date ensures realistic generalization.
Follow-up Question 8
How would you deploy these models at scale for millions of users?
Explanation
Pre-compute learner embeddings and course embeddings offline using a distributed training environment. Store them in a low-latency service for real-time retrieval. Score each user-course pair on demand or pre-rank a subset of candidate courses. Use distributed or sharded systems that handle the large scale. Incrementally update embeddings as new watch signals arrive. Continuously retrain the model at regular intervals. Cache popular course embeddings in memory to speed up inference.