
ML Case-study Interview Question: ML-Powered Real-Time Personalized Product Ranking System


Browse all the ML Case-Studies here.
Case-Study question
You are consulted by a large consumer-facing platform aiming to improve product recommendations for millions of users. They have extensive historical data on browsing and purchasing patterns, along with various contextual features (time of day, location, device type, etc.). They want a real-time machine learning system that provides personalized product rankings to each user. Describe your full approach, including data collection, feature engineering, model selection, and deployment strategy. Propose a detailed solution plan with metrics. How would you handle training at scale and ensure timely inference?
Detailed solution
Data arrives in raw form from events logging user interactions such as clicks, impressions, and purchases. The data pipeline collects these events in real-time and stores them in a distributed system. Transformations include parsing timestamps, user IDs, product IDs, session identifiers, and contextual attributes. Data is partitioned by time to allow incremental processing. The pipeline merges these event streams into training-ready formats: tabular features, user profiles, and product embeddings.
Models that predict a user’s engagement or purchase probability can be trained with an objective function. For classification tasks, a common choice is cross-entropy loss. The formula for cross-entropy loss for a single instance is shown below.
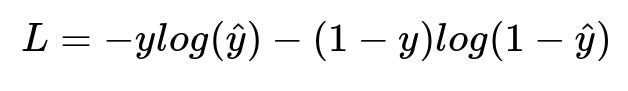
Here, y is the true label in plain text format. For user click prediction, y=1 if the user clicked, else y=0. The term log(...) is the natural logarithm. The predicted value is hat{y} in plain text format, representing the model’s probability of the click or purchase. Minimizing this loss aligns predicted probabilities with actual outcomes.
Feature engineering
Model inputs include user embeddings capturing their past behavior. Features also include product embeddings that represent product similarity. Context features (time of day, device type, session recency) are combined with user and product embeddings. Embeddings might be learned via matrix factorization or neural networks. Numeric attributes (user’s total spend, product’s price) are normalized. Categorical attributes (device type, location) are one-hot or embedded.
Model selection
Experiments can involve gradient-boosted decision trees or neural ranking approaches. For tree-based solutions, libraries such as XGBoost, LightGBM, or CatBoost are efficient. For a neural approach, a two-tower architecture can match user embeddings and product embeddings, with additional layers for context. Validation splits must replicate online data distributions. Hyperparameter tuning is done using randomized or Bayesian search.
Training at scale
Data volumes can be massive, so distributed compute clusters handle iterative training. Frameworks like Spark or TensorFlow on Kubernetes allow parallelization. Pipelines must continuously accumulate new data, shuffle for randomization, and feed it to training nodes. Offline model evaluation uses AUC, log loss, and ranking metrics (NDCG or MRR) over holdout sets.
Real-time inference
The final trained model is served through a low-latency system. For each request, the user’s embedding and context are combined with product embeddings to generate a set of predicted scores. The top products are sorted by descending predicted score. System caching and approximate nearest neighbor lookups speed up retrieval. Monitoring includes per-request latencies, memory usage, and model accuracy drift over time.
Deployment and iteration
Periodic retraining incorporates fresh user behavior. Feature drift is detected by comparing training data distributions with real traffic. Testing strategies involve A/B tests and canary releases to check performance improvements without risking all user traffic. A results dashboard highlights changes in revenue and click-through rates.
How would you address data quality problems in the pipeline?
Data anomalies arise when logs are incomplete or certain identifiers are malformed. Many log records lack user or product information. Solutions involve deduplicating events at ingestion, discarding corrupted entries, and inferring missing fields from known relationships. Monitoring includes automated alerts for unusually high missing rates. Retraining must always exclude problematic data to avoid skewed parameter estimates.
How would you handle the cold-start problem for new products or users?
Scarce historical data complicates modeling for newcomers. Possible approaches include learning shared representations via embeddings that leverage content attributes (product category, textual descriptions). For new users, default preferences can be derived from population-level behavior, then quickly updated after minimal interaction. Zero-shot or few-shot techniques adapt representations by referencing similar items or users in the learned embedding space.
How would you ensure explainability?
Certain regulations or internal guidelines may require interpretability. Tree-based models allow feature importance scoring. Model-agnostic methods like SHAP produce per-feature influence metrics. Neural architectures can be partially explained via attention weights or by analyzing embedding similarity. Continuous documentation includes each feature’s origin, transformations, and effect on the model output.
How would you confirm the system’s success?
Offline metrics like log loss, AUC, and ranking metrics must show improvement. Online tests measure CTR (click-through rate), conversion rate, revenue lift, and session length. System logs track latency and throughput. A/B experiments compare the new system with a baseline. Statistical significance testing ensures observed gains are robust. Production monitoring looks for performance regressions.
How would you optimize inference latency?
Service-level requirements demand sub-100ms responses for each request. Optimization includes caching popular product embeddings, using vector databases for approximate similarity, and serving models through efficient runtime frameworks (TensorFlow Serving, Triton Inference Server, or custom C++ microservices). Hardware acceleration with GPUs or specialized inference chips reduces compute overhead. Batch processing of requests can amortize repeated calculations.
How would you handle hyperparameter tuning in production?
Hyperparameter sweeps run asynchronously with historical data. Each run logs hyperparameters, model metrics, and resource usage. A job scheduler orchestrates multiple experiments. Tuning strategies like Bayesian optimization hone in on promising configurations faster than grid searches. Early stopping halts underperforming trials. Winning configurations are tested offline first, then tested online with small user groups. If they outperform current production settings, they are rolled out systematically.
How would you detect and mitigate data drift?
User or product behaviors evolve. Distribution shifts degrade model accuracy. Continuous data monitoring checks feature distributions against baselines. If features or labels significantly shift, retraining triggers. Unsupervised drift detection can use KS tests or Earth Mover’s Distance. If drift is confirmed, the pipeline refreshes the dataset with recent interactions and updates the model. Frequent iteration plus robust alerts prevent stale models.
How would you handle the ranking logic if there are numerous constraints?
Business constraints (e.g., inventory limits, product promotions) must be integrated. A two-stage approach can filter items by constraints, then apply learned rankings. Alternatively, use a constrained optimization layer that modifies the raw scores. Hard constraints like “must show certain categories” override model outputs. Soft constraints like “promote new releases” can be embedded as additional features. Balancing constraints while optimizing predictive accuracy might require advanced ranking algorithms that re-score items within constraints.
How would you approach scaling this system globally?
Regional data silos and diverse user behaviors might require separate models for each region or a unified approach with region-specific embeddings. Infrastructure scales using container orchestration. Edge computing can cache local product data for faster retrieval. Global load balancing routes traffic to the nearest data center. Model replication ensures redundancy and low-latency predictions. Periodic synchronization merges region-specific updates into a global data store.
Conclusion
A robust, end-to-end machine learning recommender pipeline can produce significant gains in personalization and engagement. Thorough data handling, effective modeling, continuous evaluation, and systematic retraining keep the system reliable at scale.