
ML Case-study Interview Question: Deep Learning for Travel Search Ranking: Addressing Bias, Cold Start, and Diversity


Case-Study question
A large-scale travel marketplace wants to improve its search ranking system with deep learning for better guest booking outcomes. The marketplace has millions of property listings, each with different features such as price, location, and capacity. The goal is to serve the most relevant listings at the top for any given search query. Past data shows that user clicks and bookings are heavily influenced by the listing’s position in the search results. Also, new listings struggle to get visibility due to limited historical engagement data. The team wants a holistic solution that addresses architecture, bias correction, cold start, and diversity of results.
Design a full plan for building and deploying a deep learning based ranking pipeline. Propose solutions to handle:
The core deep learning architecture.
The positional bias in past data.
Cold start for new listings.
Diversity among top search results.
Explain how you would measure success and ensure your approach generalizes well. Provide any relevant equations or code.
Detailed Solution
Architecture
Many teams adopt a dual-tower neural network for learning user-listing interactions. One tower encodes query/user features and the other encodes listing features. The training objective ensures that booked listings receive higher scores than unbooked listings. That is sometimes approximated by a margin-based loss:
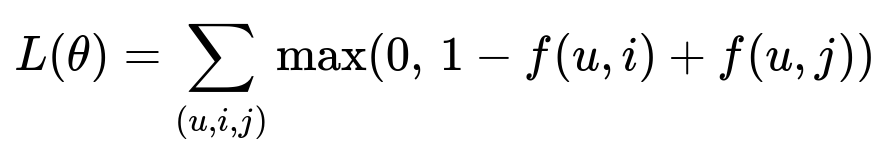
Where:
u represents user or query features.
i represents a booked listing.
j represents an unbooked listing.
f(u,i) is the model's relevance score for user/query u and listing i.
Minimizing this loss pushes booked listings closer to the user embedding than unbooked ones.
Bias
Position bias arises when items near the top get more attention by default. This skews training data, since those items appear favored regardless of their true quality. Incorporating a learned position feature in the neural network helps the model understand how many clicks or bookings are partly due to the listing’s rank. During training, that position feature can be dropped out some fraction of the time, forcing the model to rely on intrinsic listing quality. At serving time, you zero out the position feature so all listings receive an equal chance.
Cold Start
New listings lack historical data. Global defaults often fail to capture their true potential. A better strategy is to estimate the new listing’s likely performance by referencing similar listings in the same geographic area or with similar capacities. Aggregated performance from those similar listings serves as a proxy for the new listing’s initial engagement prediction.
Diversity of Search Results
Individual listing scores alone may produce a homogenous set of top results. Introducing a sequence model or context embedding captures the overall set composition. For example, re-rank the top candidates to ensure variety in features such as price, location, or style. One approach is to use a Recurrent Neural Network to encode the partial list of chosen items, then apply that information to pick the next item, ensuring broader coverage in the final set.
Implementation Detail
For production, you can first train offline on historical data with the above approach. You can then perform online A/B tests with different re-ranking and cold start treatments. Use real-time features like user location or session context to feed into the architecture.
Below is a minimal code structure for a two-tower model in Python:
import tensorflow as tf
# Example tower for query/user
user_inputs = tf.keras.Input(shape=(user_feature_dim,))
user_hidden = tf.keras.layers.Dense(128, activation='relu')(user_inputs)
user_emb = tf.keras.layers.Dense(64, activation=None)(user_hidden)
# Example tower for listing
listing_inputs = tf.keras.Input(shape=(listing_feature_dim,))
listing_hidden = tf.keras.layers.Dense(128, activation='relu')(listing_inputs)
listing_emb = tf.keras.layers.Dense(64, activation=None)(listing_hidden)
# Compute similarity or relevance score
dot_product = tf.reduce_sum(user_emb * listing_emb, axis=1)
model = tf.keras.Model(inputs=[user_inputs, listing_inputs], outputs=dot_product)
model.compile(optimizer='adam', loss='hinge') # example margin-based loss
You can adapt the loss to your ranking scheme. You might sample pairs (booked vs unbooked) during training.
Measuring Success
Deploy to a small subset of live traffic. Compare booking metrics, revenue outcomes, and user engagement signals against a control. If the new system outperforms the baseline in a statistically significant way, you scale it up.
What if the position feature leads the model to memorize user click patterns and ignore listing relevance?
The dropout strategy mitigates over-reliance. You randomly zero out the position feature 15% of the time (or whichever rate you choose). This forces the network to learn listing attributes that lead to higher engagement, not just rank position.
Also watch for overfitting. Overfitting can manifest if the model uses position too heavily on the training set. Adjust regularization or dropout if you see that behavior.
How do you tune your model when you have 200+ features?
Group related features into blocks, such as price, location, user context, listing attributes, etc. Start with simpler architectures and measure performance via offline validation and small-scale A/B tests. Expand or refine feature sets iteratively. Use standard hyperparameter search (grid or random search) or specialized tools like Bayesian optimization.
Monitor metrics like training loss, validation loss, and booking lifts. Watch for any distribution shift between offline data and live data.
Could you accidentally bias towards older listings?
Yes, if historical data systematically ranks older listings higher, the model sees them as more likely to get clicks or bookings. That’s why you add position as a feature, partially drop it out, and also add better cold start for new listings. This evens the playing field for those that lack historical data but show strong potential.
How would you ensure the system remains stable under real-time traffic?
You can keep a stable fallback model in production. Only switch traffic to the new model if metrics are positive. Monitor real-time logs for anomalies in user engagement, bookings, or site latency. If something goes off-track, revert quickly to the fallback.
Do you worry about computational cost with an RNN-based re-ranking step?
Yes. Re-ranking with RNNs can be expensive if the result set is large. You can limit the re-ranking to the top N listings scored by the initial model. That helps maintain decent latency. Also use vectorized operations on modern hardware (GPUs or specialized accelerators).
Would you test the final model worldwide at once?
No. Launch changes gradually, often region by region. This reduces risk in case local user behavior differs. It also protects user experience if any unanticipated issues arise.
What about explainability for this ranking?
Neural networks can appear opaque. For internal debugging, partial dependence plots or feature importance methods can provide insight into how features affect the predicted score. Explainable AI libraries can help. But in practice, you often rely on robust A/B testing to confirm that improvements in user metrics reflect meaningful relevance.
Why not just rely on user-labeled preferences?
Many users do not explicitly label preferences. Bookings and clicks are often the only large-scale signals available. They are imperfect but still strong. That’s why you address the biases in them.
If new listings get an inflated boost, won't that affect user trust?
Balance is crucial. You want new listings to have a fair chance. You do not want them artificially inflated to the point where user experience suffers. You can use gating rules that gradually reduce the cold start boost as a listing accumulates real engagement data.
How do you ensure diversity?
After the initial scores are computed, you can re-rank them by injecting variety in price, location, or style. This usually has a small trade-off with immediate relevance, but it improves overall user satisfaction and helps them explore broader options.
In what scenarios would you keep the simpler approach?
If you have fewer listings or if user preferences do not vary much, a simpler model without diversity re-ranking may suffice. Also consider computational constraints. But at scale, the complexities of bias, cold start, and diversity usually arise.
How do you handle real-time updates, like an owner changing price?
Include real-time features in a low-latency feature store or embed the logic in the inference pipeline. For instance, the listing’s updated price is fed into the model right before scoring. This ensures the final ranking reflects the latest information.
How would you define success in offline experimentation?
Typically, offline checks compute ranking metrics (NDGC, MRR, or other ranking metrics) against historical test sets. If offline metrics look promising, you run small A/B tests. If those hold up in production, you gradually ramp up.
Any final operational considerations?
Maintain guardrails. Monitor system errors, throughput, and latencies. Make sure your system can handle peak traffic. Keep logs for debugging. Have fallback mechanisms ready in case the model or feature pipelines fail.
That completes a thorough plan: dual-tower neural network architecture, position bias correction, cold start solutions, and re-ranking for diversity.