
ML Case-study Interview Question: Specialized Text Revision Using Instruction Fine-Tuned Language Models


Browse all the ML Case-Studies here.
Case-Study question
A leading tech company needs a text editing system that takes user text as input, applies various edits (grammar fixes, rephrasing, style adjustments), and returns improved output. They want a specialized language model for text revision rather than a general-purpose generator. They found that training large models for every possible task wastes resources and yields lower-quality edits. They want to train smaller models with fewer parameters, but with higher performance, focusing on text editing tasks such as fluency, coherence, style adaptation, and meaning preservation. The project team wants the new text editing model to handle “adjacent” tasks (like sentence compression or formality changes) and chained tasks (like combining style, grammar fixes, and clarity in a single request).
Propose a strategy to build and evaluate this specialized text editing model. Show how you would construct the training data, choose the architecture, design the instruction fine-tuning scheme, measure the performance, and handle composite tasks. Describe how to confirm its capability to generalize to new editing tasks.
Detailed solution
This requires a systematic approach to gather data, train a specialized model, and compare it with general-purpose models. Building a dense dataset of text editing instructions helps the model learn to transform text while preserving the original meaning. Constructing targeted prompts that express common editing needs (improving fluency, changing tone, etc.) makes the model more robust for text editing scenarios. Splitting data into known tasks (grammar corrections, rephrasings) and “adjacent” tasks (sentence compression, politeness transfer) tests the model’s ability to generalize to variations.
Training a sequence-to-sequence architecture with encoder-decoder layers is effective. The model sees pairs: (instruction plus original text) -> (revised text). Instruction fine-tuning focuses the model on text revision objectives. This helps the system produce more accurate outputs for specialized tasks. The best practice is to select a base pretrained language model that is already proficient in text comprehension. Fine-tuning on a domain-specific dataset narrows the model’s expertise to text editing.
Showing the core cross-entropy loss used in training:
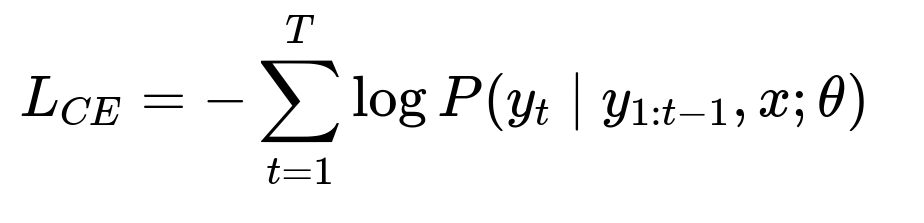
Here, x is the input text, y_t is the target token at timestep t, and theta is the model’s trainable parameters. Minimizing L_CE encourages the model to assign higher probability to the correct edited token sequence.
Evaluating the model involves both automated and manual methods. Standard text-editing benchmarks (covering grammar, coherence, paraphrasing) supply a quantitative measure. Human raters compare candidate outputs against ground truth or alternative models, judging fluency, meaning preservation, and style accuracy. One can measure how often the new model’s edits are preferred relative to a reference system.
Handling composite tasks requires data that combines multiple edits in a single prompt (for instance, “correct grammar and simplify wording”). Augmenting training data with combined instructions trains the model to chain different editing needs. This approach helps the model handle multi-part requests without losing consistency or clarity.
Adapting to adjacent tasks happens naturally if the training set includes varied instructions that are still within text editing territory. Examples: “compress the sentence,” “shift the tone from casual to formal,” or “make the text polite.” The model learns to interpret new instructions that are near its training domain.
In code, the fine-tuning can use a popular library:
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-base")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-base")
instruction_examples = [
{
"instruction": "Improve fluency",
"input_text": "He go to store for buy some bread",
"target_text": "He goes to the store to buy some bread"
},
{
"instruction": "Change to polite tone",
"input_text": "Send me that file now",
"target_text": "Could you please send me that file"
}
]
enc_inputs = tokenizer(
[f"{ex['instruction']}: {ex['input_text']}" for ex in instruction_examples],
padding=True, truncation=True, return_tensors='pt'
)
dec_inputs = tokenizer(
[ex['target_text'] for ex in instruction_examples],
padding=True, truncation=True, return_tensors='pt'
)
outputs = model(**enc_inputs, labels=dec_inputs["input_ids"])
loss = outputs.loss
loss.backward()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
optimizer.step()
This snippet shows a simplified version of how to structure instruction-based fine-tuning. Repeating with a large batch of text-editing examples improves editing quality.
How would you measure performance on specialized editing tasks?
Accurately measuring editing tasks requires referencing standard datasets for grammar correction, paraphrasing, and style transfer, then comparing predictions to gold-standard references. One can compute the usual string-based metrics (BLEU, ROUGE, METEOR) or use newly proposed text-editing metrics that emphasize fluency and meaning preservation. Human evaluations add clarity by rating subtle factors like style and naturalness.
How would you handle complex multi-part requests where multiple edits must happen in sequence?
Training a separate model variant on composite instructions helps. Concatenating tasks within the same prompt (like “correct grammar, simplify, then paraphrase”) during training encourages the model to perform sequential edits. This approach involves layering tasks in a single dataset sample, ensuring the output is a single text revised according to all instructions.
How would you approach model size vs. quality trade-offs?
Experimenting with different parameter sizes (for example, 770 million vs. 3 billion vs. 11 billion) is helpful. Smaller models can run more efficiently while still performing well if the data is dense with text-editing instructions. Comparing them on standard benchmarks and real user feedback indicates if the smaller model retains strong editing performance. If the smaller model underperforms for certain tasks, adding more examples or focusing on crucial instructions can close the gap.
How do you ensure the model adapts to “adjacent” tasks it never saw in training?
Feeding it tasks near the core editing domain and ensuring diverse instructions within text editing fosters generalization. Synthetic tasks similar to the main tasks can push the model to learn flexible text transformation strategies. If the model sees enough varied edits, it can extrapolate to new but closely related instructions.
How would you structure a human evaluation?
Pairwise comparisons between model outputs and outputs from a baseline or other competitor measure preferences. Human judges look at fluency, accuracy, preservation of meaning, and style. They pick which output is better on each dimension. Aggregating results from multiple judges confirms whether your specialized model has a clear advantage.
What if some tasks require domain-specific knowledge?
Adding domain examples to the fine-tuning dataset helps. If the model must revise technical documentation, collecting representative data with domain jargon clarifies the expected text style. Fine-tuning on a domain subset ensures it acquires relevant context. Continual training or adapter-based methods can further refine the model for specialized terminology.
Would you explore reinforcement learning or other techniques?
Yes, if you want the model to optimize for user-centric objectives like minimal distortion or maximum clarity. Reinforcement learning from human feedback can help the model revise text in ways that please readers. Designing a reward function that captures human satisfaction can refine model outputs beyond standard cross-entropy training.