
ML Case-study Interview Question: Neural Network Recommender: Feature Engineering & Embeddings for High-Scale Interactions


Browse all the ML Case-Studies here.
Case-Study question
A data platform handles millions of transactions daily, including vast user interactions. Management wants to build a new recommendation engine that increases user satisfaction and revenue. They provide historical interaction logs and user metadata. They ask you to propose a complete solution from data ingestion to online serving.
Explain your high-level approach. Propose your design for data preprocessing, model selection, and training. Show how you would evaluate performance, measure business impact, and iterate your pipeline. Suggest how to maintain and update the system in production. Specify potential pitfalls and mitigations.
Proposed Detailed Solution
Data ingestion uses a streaming system that collects raw event logs and user attributes. A batch pipeline combines these logs into a single structured dataset. The process standardizes fields like timestamps, user identifiers, item identifiers, and interaction signals.
Data cleaning removes duplicates, invalid entries, or corrupted rows. Feature engineering creates aggregated statistics, such as average user rating or time since last purchase. User embedding merges demographic and behavioral signals. Item embedding captures textual or categorical properties. Context embedding incorporates real-time signals like device or region.
Model selection focuses on a neural network that consumes user, item, and context vectors. The input merges user embedding plus item embedding plus context features. The network outputs an interaction likelihood. Loss function typically uses binary cross-entropy if we train for a click or purchase prediction objective.
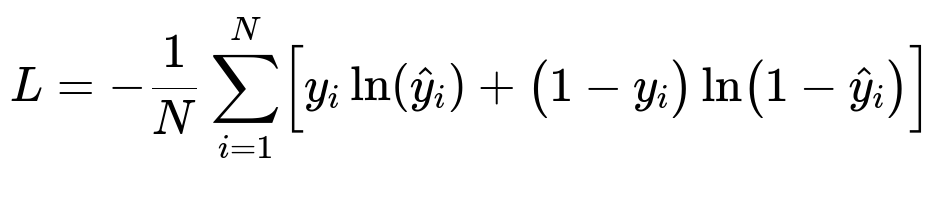
N is the number of training samples. y_{i} is the true label for the i-th sample. \hat{y}_{i} is the predicted probability for the i-th sample. The first term penalizes false negatives, and the second term penalizes false positives.
Training uses minibatch stochastic gradient descent with adaptive optimizers. Early stopping monitors validation loss. Hyperparameter tuning experiments with dropout rates, learning rates, and layer sizes. Regularization avoids overfitting by controlling parameter magnitude.
A candidate code snippet for the neural network (PyTorch style):
import torch
import torch.nn as nn
import torch.optim as optim
class RecommendationNN(nn.Module):
def __init__(self, user_dim, item_dim, context_dim, hidden_dim):
super(RecommendationNN, self).__init__()
self.fc1 = nn.Linear(user_dim + item_dim + context_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.output = nn.Linear(hidden_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, user_vec, item_vec, context_vec):
x = torch.cat([user_vec, item_vec, context_vec], dim=1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.sigmoid(self.output(x))
return x
user_dim = 64
item_dim = 64
context_dim = 10
hidden_dim = 128
model = RecommendationNN(user_dim, item_dim, context_dim, hidden_dim)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
In this example, RecommendationNN merges user vectors, item vectors, and context vectors. Then two fully connected layers use ReLU activation. The final layer outputs a probability. BCELoss calculates the cross-entropy. Adam updates parameters.
Once the model converges, offline metrics include AUC (Area Under the Curve), log loss, precision at top ranks, or recall. We also measure revenue uplift by simulating recommendations on a sample set. For production, an A/B testing framework compares the new engine with the existing baseline. Real user engagement (click, purchase, retention) is observed.
A real-time feature store feeds the serving environment with fresh embeddings. A microservice takes a user context, looks up relevant features, runs the model inference, and outputs recommended items. A caching layer speeds up response time for frequent queries. Monitoring tracks response latency, system load, and key business metrics.
Potential pitfalls: Overfitting to historical data if user behavior shifts. Address with regular re-training or incremental updates. Data leakage from including future data in the training set. Avoid by carefully controlling temporal splits. Scalability issues from large embeddings. Mitigate by sharding or approximate nearest neighbor queries. Bias if the system systematically overlooks certain item categories. Address by fairness constraints or re-balancing data.
System updates should happen regularly. Re-run feature extraction, re-train, and test offline. Roll out to a fraction of traffic, validate stability and performance, then fully deploy. Use a robust rollback strategy if metrics degrade.
Potential Follow-Up Questions
How would you handle the cold-start problem?
A new user or item has no historical interactions. Factor this into your embeddings. One approach uses the average representation for unknown items or partial signals from item metadata. For new users, a minimal questionnaire or short feedback loop can bootstrap a basic embedding. Side-information like content or user demographics also helps.
Why choose a deep neural network over a simpler algorithm like matrix factorization?
A neural network processes user vectors, item vectors, and context signals in a single architecture. A linear matrix factorization approach is simpler and sometimes effective, but it may not capture complex interactions or unstructured content like text. A neural network can incorporate more features and learn nonlinear patterns.
How would you ensure reliability and consistency in the feature store?
A pipeline must transform raw events into consistent feature vectors with stable schemas. Timestamp alignment ensures features and labels come from the same time slice. A robust data validation step checks distributions and data types. Schema evolution is carefully tracked, and versioning is used to handle changes.
How do you measure if the system performs well in production over time?
A/B tests compare the recommendation engine to the baseline on key metrics. If the new engine has higher user satisfaction, increased session length, or more purchases, it is performing well. Time-series tracking reveals any drift in user behavior. A post-deployment data monitoring pipeline ensures the model’s predictions match real outcomes.
How do you handle personalizing recommendations while respecting user privacy?
Use anonymized and aggregated data. Avoid storing identifiable attributes. Deploy differential privacy or other anonymization techniques if needed. Only collect minimal user information and follow data privacy regulations. Models can train on hashed IDs, ensuring no direct user identity is exposed.
How would you approach scaling this system to hundreds of millions of users?
Horizontal scaling with distributed data processing frameworks. Feature computation parallelizes across clusters. Model training uses large-scale GPU or parameter server infrastructure. Serving can be split regionally to reduce latency. System architecture includes load balancers, auto-scaling groups, and caching layers.
What if you see big performance gains offline but no improvement online?
Possible mismatch between offline training data and real user behavior. A/B test metrics might differ if user preferences shifted. Real-time context could be missing from the offline dataset. Investigate alignment issues, incorporate fresh data, or refine the training objective to match real usage signals. Adjust the evaluation metric to reflect the online objective.
What is your strategy for avoiding model staleness if user preferences rapidly change?
A near-real-time feedback loop collects new events. Frequent incremental re-training or a streaming training pipeline updates the model. If user behavior changes drastically, a new model version is trained and validated quickly. Feature extraction is adapted for changing trends. Rolling updates keep the serving model fresh.