
ML Case-study Interview Question: Machine Learning for Personalized E-commerce: Ranking Collections & Items with Diversity.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a personalized homepage for a multi-vertical e-commerce store that carries hundreds of thousands of SKUs in thousands of categories. The homepage features vertically stacked collections of items, with each collection containing a group of horizontally ranked items. The store’s goal is to show each user only the most relevant collections and items, personalize their arrangement, account for user context and preferences, and ensure diversity to avoid repetitive or overly similar suggestions. The store already has large-scale data on user behavior (searches, clicks, add-to-cart, and conversions) from earlier browsing sessions across different product categories, as well as various contextual information (time of day, day of week, location). The product team also wants a system that can adapt in near real time to changes in inventory and user tastes. How would you build an end-to-end machine learning system to address these requirements and deliver a fully personalized homepage that maximizes user engagement and conversion?
Detailed in-depth solution
Overview of the system
A machine learning pipeline can be split into distinct steps. The first step identifies which thematic collections to show to each user. The next step ranks items within each chosen collection. Finally, the system applies post-processing steps to handle business constraints and to enrich the user experience with diversity.
Collection generation
Collections can come from three sources: operator-curated (manually built for promotional or thematic use), rules-based personalized (based on explicit user history such as top brands they bought previously), and machine learning–based personalized (predicting which product categories or clusters a user would find attractive). Each method yields a group of potential collections.
Collection retrieval
A collection retrieval model makes a first pass to select which collections from the overall inventory are most promising for a given user. It predicts the probability of user engagement for each (collection, user, context) triplet. Features include user behaviors (previous orders, subscription status), collection attributes (popularity, recency), and contextual signals (time of day, store type). A high-level example is training a model to output the probability that a user will click or add something to cart from a certain collection, and selecting the top few that score well.
Horizontal item ranking
An item ranking model then orders items within each retrieved collection from left to right. A simple approach is to optimize for click-through rate, but this can favor items that get clicks yet do not convert to purchases. A better approach includes deeper objectives: assign higher weights to samples where a click led to an add-to-cart or a purchase. Features typically include item popularity, user preferences (brand loyalty, dietary needs), and semantic embeddings that encapsulate deeper user–item similarity.
Position bias handling
Position bias arises because items shown closer to the left (top) receive more engagement by default. The system learns a function of position and context to correct for this. During training, item position is passed in as a feature along with the product surface. This helps the model separate genuine user preference from position-induced clicks. During inference, the model is called with the default position set to the leftmost slot (position=0), telling the model effectively: “Give me the score for this item if it were the first item a user sees.”
Post-processing with diversity
Pure ranking by predicted score often clumps similar items together. The system injects diversity with a post-ranking step using a maximal marginal relevance approach. The objective function for selecting the next item j, given a set I of already-chosen items, is:
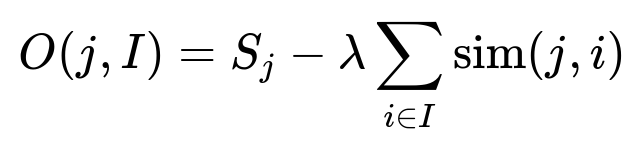
S_j is the item ranking model score for item j, and sim(j, i) measures similarity of item j to previously selected items i in I. The sum runs over items in I, and λ balances the trade-off between relevance and diversity. A similar process is applied to collections. The system thus inserts items and collections that are still relevant but reduce repetitive choices.
Collection ranking and final post-processing
Each chosen collection has items that are already ranked and diversified. The next step orders the collections vertically by their average top-K item scores. After that, business constraints—such as removing items predicted to be out of stock or penalizing items lacking images—are enforced. Collections too similar to each other are also spaced out or pruned. This ensures the final homepage is rich in variety and user-specific relevance.
Future expansions
Future enhancements include using multi-task, multi-label architectures that handle multiple product surfaces simultaneously (for instance, different site layouts or mobile app versions) and training on multiple objectives (clicks, add-to-cart, and conversions). Another step is using session-based real-time features (current cart contents, most recent searches) so the recommendations adapt to sudden user preference shifts. Incorporating signals from a user’s other behaviors, such as their dining history in different verticals, adds additional personalization depth.
Implementation example (simplified)
Data is gathered in a feature store that logs user signals (clicks, conversions) and item attributes (category, brand, price). A training pipeline is set to learn a logistic regression or tree-based model that outputs an engagement probability for each collection. A second model ranks items. A microservice queries these models at inference time when a user visits a page, retrieving top collections and items. A post-processing layer reorders items and collections to ensure diversity. Caching is applied when many users with similar profiles visit a store, but the system still relies on real-time signals for final adjustments if required.
Potential follow-up question 1
How would you ensure that the collection retrieval model is not too slow given the need to score a large number of possible collections?
A good approach is to limit the total collections you score by first applying a lightweight filter. For instance, filter out collections with extremely low overall popularity or those shown only in rare contexts. Caching or indexing strategies can be used so that the system only performs detailed inferences for the top candidate collections. Another technique is approximate nearest-neighbor search in embedding space for user–collection similarity.
Potential follow-up question 2
Why might focusing exclusively on click-through rate for item ranking be problematic?
Some items attract many curiosity clicks but rarely lead to final purchases. Pure CTR optimization can rank these items too high. A balanced approach uses click-to-purchase or add-to-cart signals. One practical method is to assign different weights to examples in the training data so that a click leading to an actual purchase is considered more valuable than a simple click.
Potential follow-up question 3
How do you measure similarity between items when applying maximal marginal relevance?
One option is to use similarity of item attributes such as category, brand, or price bucket. Another option is to embed items in a vector space using an embedding model and compute a distance metric such as cosine similarity. The key idea is to push the system to avoid repeating near-duplicates that reduce variety.
Potential follow-up question 4
What are the main challenges of handling position bias?
Position bias can mask true user preference because higher positions get more attention regardless of item quality. This can produce misleading labels. During training, introducing position as a feature or performing inverse propensity weighting can counteract the skew. The challenge is that raw click data alone is not sufficient. You need modeling techniques or experiments that expose items to different positions randomly to learn unbiased preference signals.
Potential follow-up question 5
Could you describe how multi-task multi-label architectures help with such a system?
A multi-task multi-label network can learn several outputs concurrently (click, add-to-cart, order) and can predict user preferences across multiple page surfaces. A single unified model shares low-level representations (for example, embeddings for user and item) while separate heads produce specialized outputs. This allows data from one task to benefit another and offers more robust representations in lower-data regimes. It also simplifies deployment since one model handles multiple predictive targets.
Potential follow-up question 6
How would you adapt the system for real-time user interactions, such as when a user is already adding items to their cart?
Real-time features are crucial. The system observes the user’s actions (items added to cart, categories searched) during the session. A session state might track a short-term embedding that changes with each click or cart addition. The model can then re-rank remaining items or collections in real time, emphasizing those that complement the current cart. This requires low-latency feature updates and in-memory serving.
Potential follow-up question 7
What strategies would you consider for evaluating success in production?
Common metrics include click-through rates, add-to-cart rates, conversion rates, and total order subtotals. Online A/B testing or multi-armed bandit frameworks can compare new models against existing baselines. Offline metrics, like normalized discounted cumulative gain (NDCG), can provide quick iteration but are only proxies for online performance. Finally, a robust monitoring system is needed to watch for issues like user drop-off if the diversity is too aggressive or if the model incorrectly penalizes popular items.
Potential follow-up question 8
How would you handle new items or new collections that do not have historical performance data?
Use cold-start strategies. This might include transferring behavior patterns from similar items (in terms of brand, category) or from user embedding approaches that learn latent representations. Another idea is to place new items or collections in higher positions with small controlled probability to gather data, known as an exploration approach. This ensures the system can learn to rank them properly over time.
Potential follow-up question 9
Why is it important to apply post-processing steps rather than relying purely on model scores?
Business logic sometimes demands constraints or reordering not captured in the model. For example, an item with no image or with a strong indication it is out of stock hurts user experience if shown in a top spot. A model might give it a high relevance score, but real-world constraints trump that. Post-processing addresses these edge conditions and ensures final results align with operational requirements.
Potential follow-up question 10
What are some common pitfalls when designing personalized e-commerce recommender systems?
Frequent pitfalls include overfitting to a small slice of user behavior, ignoring data freshness, not accounting for position bias, failing to introduce sufficient diversity, and missing real-time context signals. Another pitfall is inadequate offline–online correlation, where a model looks good offline but fails in production because the training data distribution diverges from live traffic.