
ML Case-study Interview Question: Interpretable PDF Analysis: Graph Layout Detection and Attention-Based Classification/NER.


Browse all the ML Case-Studies here.
Case-Study question
A technology firm receives thousands of textual PDF documents daily. Each PDF can contain free-form text in various formats. The firm needs to automate two tasks:
Detect and extract the correct reading order from a 2D grid of words.
Perform text classification and Named Entity Recognition with interpretability for auditing.
How would you design a production-ready pipeline that addresses these tasks, ensuring high accuracy, efficient processing speed, and explainability features? Assume that most PDFs are machine-readable but a small portion are image-based and need Optical Character Recognition. Propose a concrete solution strategy, discuss possible models, outline your approach to continuous improvement, and explain how to integrate interpretability tools for debugging.
Detailed solution
Layout Detection
A pipeline can start with extracting textual information from PDFs. Text is extracted along with word coordinates. When the PDF is image-based, you can apply OCR first. Text then appears as a 2D grid of words, each having an (x, y) coordinate. A fast, rule-based or learned approach can cluster words into paragraphs. One method uses graph-based segmentation, where you build a graph of words and discard edges if they are unlikely to belong to the same paragraph. A Random Forest classifier can score whether two words belong together by analyzing distance, alignment, and font size. After obtaining strong-confidence edges, you cluster words into paragraphs or columns. This step can yield a more coherent text flow.
Classification Model
A classification step can label entire documents or specific attributes. A strong baseline can be an Embedding + LSTM architecture, but long sequences may cause hidden states to lose early information. A global attention mechanism solves this. Each word's hidden state obtains an attention weight that can be used to compute a weighted sum as the final document embedding. This also provides interpretability. A single pipeline can handle tasks like patient gender classification or document type classification.
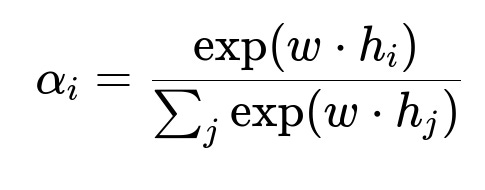
Here, alpha_i is the attention weight for the i-th token, exp is the exponential function, w is a learnable vector, and h_i is the hidden state of the i-th token. The weighted sum of all hidden states becomes the final representation for classification. Words with higher alpha_i contribute more to the predicted label.
Named Entity Recognition
NER can identify structured information like patient name or demographics. A BiLSTM or LSTM with a conditional random field layer on top can label each token with an entity category. For interpretability, you can track the confidence scores per token. This helps debug misclassifications, especially when certain words are mislabeled due to OCR noise or domain-specific abbreviations.
Explainability Mechanism
An internal dashboard can reconstruct the anonymized document. The pipeline can run a sub-model that outputs each token's attention score. A front-end can highlight words in proportion to those scores, making it easy to see which parts of text influenced predictions. For NER, raw softmax outputs or CRF potentials can appear as color-coded heatmaps over tokens. This system helps with:
Support requests (why the model misclassified).
Quality assurance for new clients or unusual PDFs.
Quick inspection of suspicious predictions.
Implementation Architecture
A mono-repo approach can house the classification/NER code (in a library) and a separate web app for debugging. A shared codebase prevents version mismatches. Type annotations enforce consistency. A backend can be in Python (FastAPI) that imports your ML library and exposes endpoints for predicted labels and attention maps. A React or similar front-end can request data from these endpoints. The front-end automatically updates if the OpenAPI spec changes, ensuring that new model output fields are handled.
Continuous Improvement
Feedback on incorrect predictions is funneled into a labeled dataset. This dataset can update the Random Forest for layout detection or the classification/NER models. By regularly retraining, you adapt to new client PDF formats or language usage. A robust MLOps strategy with version control, CI/CD, and type checks ensures models stay maintainable.
Possible follow-up questions and exhaustive answers
How do you handle edge cases where the PDF has overlapping text or tables?
Overlapping text or tables can break standard extraction. A custom post-processing step can fix partially overlapping text blocks. One strategy is to apply stricter alignment checks or advanced region detection using x-y spacing thresholds. For tables, a specialized table parser can detect consistent row patterns or line separators if they exist. If it is an image-based PDF with heavy noise, an OCR solution with table detection heuristics might be necessary. You can store fallback pathways for unusual documents and route them to specialized parsers.
Why not rely solely on PDF's internal text order for layout?
Some PDFs contain text objects arranged randomly on the page. PDF object order can be misleading. A robust system re-sorts words by coordinate clustering instead of trusting the file structure. This prevents mixing columns or ignoring floating text boxes. Also, you want one consistent pipeline that can handle both machine-readable PDFs and those that need OCR, so coordinate-based clustering is universal and more reliable.
How do you tune the threshold in the Random Forest for paragraph segmentation?
The model predicts a probability that two words should merge. You can define a first high threshold that ensures high precision merges. You then have a second slightly lower threshold for plausible merges, which you resolve by checking current cluster context. If both words already belong to similar columns or lines, you can accept the merge. This context-based approach balances recall and precision. Empirical experiments with a labeled dataset show the best thresholds to maximize overall segmentation metrics.
How does the global attention layer improve interpretability over a simple LSTM?
A plain LSTM that only takes the last hidden state does not directly indicate which words most contributed. The global attention mechanism aggregates states from each time step with learned weights. This gives a per-token weight alpha_i that is easy to visualize. Large alpha_i highlights tokens that impacted the final classification. This is more intuitive for debugging. The architecture is also easy to implement with a few lines of code in Keras or PyTorch.
What if the model incorrectly focuses on stop words during attention visualization?
Attention can sometimes highlight unhelpful tokens. This might happen if the dataset distribution biases the model or if certain words appear frequently in a specific class. To address this, you can:
Increase the size of your training set or apply stricter regularization so the model does not overfit to spurious cues.
Mask out stop words or define custom token weighting in the attention mechanism.
Perform error analysis and refine labeling. This helps ensure the model learns more meaningful signals rather than overfitting to random patterns.
How do you test or validate the correctness of the explainable interface?
You can design a test set with known keywords that must strongly impact predictions. If the model's explanation fails to highlight these keywords, there's a discrepancy. You can also do human-in-the-loop testing with domain experts: they read the explanation and confirm if the top highlighted words match their intuition. This ensures the interface works and gives a sense of trust in the system.
How can we integrate the pipeline into a larger MLOps environment?
A containerized approach can package the entire solution into one service or multiple microservices. The service that handles PDF ingestion can feed text blocks to the layout detection step. That step provides a re-ordered text sequence to the classification or NER model. The final predictions, with attention or CRF confidences, are served via an API. A CI/CD pipeline can rebuild and redeploy the container whenever the code changes, ensuring version consistency. Automated tests confirm that the entire chain from extraction to classification runs correctly.
What if your model must handle multi-lingual medical documents?
The pipeline can be extended with a language identification step. The system can load or switch to a specialized multilingual model if the language is not the main language. A modular codebase can keep language-specific embeddings for each language. If your data is mostly in a handful of languages, you can train separate classification and NER models for each. If the distribution is varied, a multilingual Transformer or universal embeddings can unify them. Additional data annotation might be needed for each language to maintain robust performance.