
ML Case-study Interview Question: Using Edge ML & Logistic Regression for Secure Virtual Card Checkout Autofill.


Case-Study question
A large financial technology provider wants to build a browser extension that automatically identifies online checkout pages and populates a unique virtual card number for each merchant. The company wants this process to be secure, resilient to changing website layouts, and fast. You are asked to propose an end-to-end solution. How would you design the machine learning pipeline, data collection strategy, model architecture, and edge deployment approach to solve this at scale? How would you measure success, ensure compliance with privacy rules, and manage ongoing model updates? Provide all technical details.
Detailed Solution
This solution describes a browser extension that can detect payment pages, locate credit card fields, and inject unique virtual card numbers at checkout. The business objective is to reduce fraud risk, minimize exposure of the main credit card number, and automate the user experience with minimal disruption. The company’s engineers used machine learning to improve reliability and reduce manual rule maintenance.
They first collected page data by reading the Document Object Model (DOM) and capturing pixel coordinates of text around payment fields. They used these features to detect whether a page is a payment page. For each input field, they also extracted HTML attributes and nearby text to classify whether it was a credit card number field, expiration date field, or security code field. The team opted for a feature-based model rather than a deep neural network because they wanted a solution that required relatively less data and was easier to interpret. They created two separate logistic regression models. One model detects whether the overall page is a checkout page, and the other model identifies which specific field type it is.
They employed term frequency-inverse document frequency (tf-idf) weighting for the text features. They computed frequencies of certain keywords and HTML attributes near the payment fields, then used logistic regression to classify them. Running inference at the edge (within the user’s browser) keeps user data private and reduces latency.
Below is a common logistic regression formula that captures how the probability of a certain class is computed from input features:
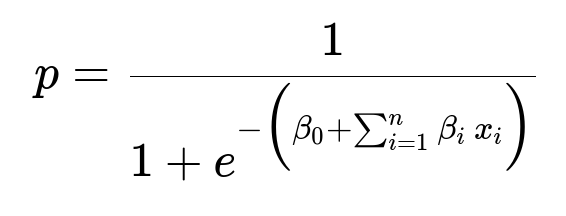
Here, p is the probability of the positive class, beta_{0} is the intercept, beta_{i} are the learned coefficients, and x_{i} are the feature values such as text indicators or HTML attribute flags. The output is 1 if the model predicts the element is indeed a payment field (or the page is a payment page), else 0.
For text processing, the term frequency-inverse document frequency (tf-idf) can be applied to each term. This means terms more common on all pages get lower weights, while terms specific to payment contexts get higher weights. They also included layout-based features by reading pixel coordinates around the input boxes to see which labels or hints appeared close to each field.
They trained both models using a labeled dataset of checkout pages from various merchants. After splitting into training, validation, and test sets, they optimized the hyperparameters and validated that the model maintained high precision and recall for identifying card fields. Once trained, they exported the model to TensorFlow.js format so the extension could run directly in the browser. That let them avoid sending user data to any external server, improving privacy.
They measured success by tracking how often the extension correctly identified checkout pages and autofilled fields without error. They reduced manual rule maintenance by letting the model adapt to new layouts. The team iterated on data quality, labeling, and feature refinement to keep the model robust.
Edge deployment required good software engineering. They wrote thorough test suites to ensure updates did not break existing functionality. They also set up a pipeline to gather anonymized feedback from real-world usage to refine the model and re-train as needed.
They used a straightforward but well-tested architecture:
Browser extension collects DOM text, HTML attributes, pixel positions.
Processed inputs are fed into the logistic regression model for page detection.
If it’s a checkout page, the second logistic regression model classifies each field.
The extension autofills the correct credit card number, expiration date, and security code using a unique virtual card number.
The user’s actual credit card number is not exposed to the merchant.
This architecture increases user security and streamlines checkout. The machine learning approach reduces manual coding of if-else rules for many unique merchant sites. The final system is robust, responsive, and privacy-preserving.
Below is a short Python-style code snippet that demonstrates an outline for training a simple logistic regression classifier on extracted features:
import numpy as np
from sklearn.linear_model import LogisticRegression
# Suppose 'features' is a NumPy array of shape (num_samples, num_features)
# and 'labels' is a 1D array of shape (num_samples,).
# Each row in 'features' might include tf-idf counts, pixel coordinate markers, HTML tags, etc.
clf = LogisticRegression(max_iter=1000)
clf.fit(features, labels)
# Predict on new data
predictions = clf.predict(new_features)
probabilities = clf.predict_proba(new_features)
In practice, the team built these models in a more sophisticated manner, including custom feature engineering and converting them to TensorFlow.js for edge usage. But the core principle remains the same: the model is trained to find discriminative features that signal a payment page or a credit card field.
How would you handle ongoing changes in checkout page design?
Checkout page designs evolve. Maintaining performance requires retraining whenever a significant shift occurs. A mechanism for continuous data collection is set up to track cases where the autofill fails or misclassifies. Engineers sample those failures, annotate them, and retrain. This keeps the model current. They also rely on robust text-based features (keywords like “Card Number,” “CVV,” “Exp Date”) and pixel proximity to important labels. These fundamental signals tend to remain stable even if merchants change specific HTML structures.
Why run the model at the edge instead of a server?
Edge inference helps privacy because it avoids sending sensitive information to a remote server. The user’s browser can process everything locally. That also reduces latency, since no external round-trip is needed. The extension can respond immediately as the user navigates to a page. It also scales better. Each user’s device handles the necessary computation without incurring heavy centralized server costs.
How do you ensure privacy while training?
They only gather anonymized page information and label it in controlled environments. Sensitive data (like actual user details) is not part of the training data. Engineers focus on features like text tokens, pixel layouts, and HTML attribute tags. Once deployed, the model infers locally on a user’s browser. If the extension ever sends telemetry for model improvement, it is scrubbed of personally identifiable information and aggregated. Compliance teams review that pipeline to meet internal and regulatory requirements.
Could deep learning improve results?
Deep learning can sometimes recognize complex patterns more effectively. But deep models often need large datasets and more extensive labeling. They can be harder to interpret and to deploy at the edge with limited resources. The logistic regression approach is simpler and works well when combined with text-based features, pixel information, and known patterns. If more advanced performance is needed in the future and dataset size justifies it, they might consider a lightweight convolutional neural network or a transformer-based solution. This would require careful optimization for memory and speed.
How do you deal with iFrames and embedded payment fields?
When an online checkout page places the payment field in an iFrame from a third-party processor, direct DOM inspection might be impossible. One approach is to detect iFrames referencing known payment providers and either inject the extension’s logic there or revert to a fallback experience if the iFrame is completely inaccessible. The team can partner with popular payment processors to provide extension hooks. If that is not available, they rely on any cross-window communication API or adopt partial manual strategies for those specific cases.
What if your model starts declining in accuracy over time?
Pages evolve, new keywords emerge, and site patterns shift. This leads to concept drift. The solution is to establish real-time or periodic monitoring that checks the extension’s performance. They track how often the model’s predictions match actual usage. A portion of data is flagged for labeling if suspicious patterns are observed. They then update the training dataset and retrain. They periodically evaluate the model with fresh data to confirm it still meets precision and recall standards.
How did they measure success?
They measured precision (how often the extension correctly autofilled fields) and recall (how many valid checkout pages were caught). They also tracked user feedback. If the extension missed or misfilled fields, that was logged as an error. They monitored latency, ensuring the extension responded quickly. They noted a reduction in manual rule coding and maintenance time as a major improvement. These metrics indicated a more robust and cost-effective solution that improved user experience.
Would you consider other classification algorithms?
Yes, if the dataset became large and patterns more complex, gradient boosting machines or random forests might be tested. Those can capture non-linearities more naturally than logistic regression. However, logistic regression is often sufficient for text classification tasks with good feature engineering. Speed, interpretability, and easy deployment with TensorFlow.js were key reasons for choosing it.
Why not purely rely on rules?
Rules are straightforward but become brittle when merchants change their page layouts. They also require ongoing manual maintenance. The machine learning approach generalizes to new patterns, especially with text-based features and pixel coordinate logic. It scales better across diverse merchant sites and quickly adapts through retraining, which is more efficient than rewriting rules each time.
Final Thoughts
This browser extension model uses logistic regression with tf-idf and pixel-based features for robust page detection and field classification at the edge. Running locally in the browser preserves privacy and ensures fast responses. Ongoing data labeling and retraining help adapt to new checkout page designs, improving the coverage of virtual card numbers and reducing manual engineering toil. This approach combines well-engineered features, simple but powerful models, and careful deployment practices to offer a frictionless, secure online purchasing experience.