
ML Case-study Interview Question: Enhancing E-commerce Search Discovery with LLM-Generated Product Recommendations


Browse all the ML Case-Studies here.
Case-Study question
A grocery e-commerce platform observed that users often want both highly relevant products and discovery-driven recommendations when they search. The platform’s existing search engine retrieves direct matches in the top section, then displays loosely related items below. This sometimes shows irrelevant suggestions and misses opportunities to inspire users with substitutes or complementary products. The team introduced Large Language Models to generate new discovery-oriented products for the related items section, aiming to improve engagement and revenue while ensuring relevance. How would you design a system to achieve these goals in a production environment? Consider the data pipeline, prompt engineering, content generation, ranking, and evaluation mechanisms.
Detailed Solution
Background and Requirements
The key challenge is to suggest items that expand a user's search experience beyond direct matches. The system needs to merge LLM world knowledge with internal data. It must produce relevant, creative suggestions while maintaining strong alignment with business goals like user engagement and revenue.
Combining LLM Knowledge with Domain Data
Basic generation uses a simple prompt that requests complements and substitutes for a query. Advanced generation adds domain signals, such as most frequently bought categories or brand information, to steer the LLM. This context avoids generic suggestions and increases alignment with user preferences.
Content Generation
The system prompts the LLM to generate short lists of complementary and substitute items. Once the LLM outputs text-based concepts, the platform maps those concepts to actual products in its catalog. For example, “Chili Seasoning” is mapped to actual chili seasoning products.
Data Pipeline
Offline batch processing runs daily. It reads query logs and metadata, creates prompts for each query, calls the LLM, parses the response, then maps each recommended item to real products. A final post-processing step removes duplicates or irrelevant products. The results are stored in a key-value store, indexed by query, for fast retrieval at runtime.
Below is a simplified Python snippet that shows how the offline pipeline might be structured:
import requests
def generate_llm_content(queries, prompt_template, llm_api_url):
results = {}
for q_data in queries:
query_str = q_data['query']
domain_signals = q_data['domain_signals']
prompt = prompt_template.format(query_str=query_str,
domain_signals=domain_signals)
llm_response = requests.post(llm_api_url, json={'prompt': prompt})
if llm_response.status_code == 200:
parsed_content = parse_llm_output(llm_response.json())
results[query_str] = parsed_content
return results
def map_to_catalog(llm_items, catalog_search_func):
mapped = []
for item in llm_items:
best_products = catalog_search_func(item) # returns a list of product objects
mapped.append(best_products)
return mapped
# Offline job
def run_offline_pipeline():
queries_with_data = load_queries_and_domain_data()
prompt_template = load_prompt_template()
llm_results = generate_llm_content(queries_with_data, prompt_template, llm_api_url='...')
final_output = {}
for q, content in llm_results.items():
product_lists = map_to_catalog(content['items'], catalog_search_func=search_catalog)
cleaned = post_process(product_lists)
final_output[q] = cleaned
save_to_store(final_output)
Ranking and Placement
When new items and carousels are shown, the platform must decide how to rank them relative to core search results. A common approach is to compute a combined score that balances relevance, user engagement, and business objectives.
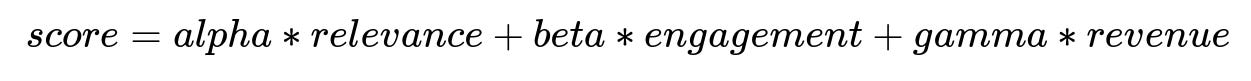
Where alpha, beta, and gamma are learned weights. relevance is how closely a product matches the query. engagement captures user interactions. revenue is the product’s contribution to business goals. The system uses these parameters to arrange results and decide where to show them on the page.
Evaluation
Evaluating discovery-oriented suggestions is more complex than checking direct relevance. One technique is to use an LLM to judge how inspirational or on-topic a recommendation list is. Another method is to measure A/B test metrics like add-to-cart rates, conversions, or engagement with the new suggested items.
Observed Impact
Adding LLM-driven recommendations increases user browsing time, cross-sells complementary items, and improves cart size. By analyzing next-query behavior (for instance, searching for a dipping sauce after searching for “dumplings”), the system grows more aware of real-world user patterns and provides better suggestions. This stronger alignment with user needs leads to measurable lifts in user engagement and revenue.
Potential Follow-Up Question 1
How would you address the risk of irrelevant or hallucinated recommendations appearing in production?
Answer and Explanation
LLMs can produce suggestions misaligned with actual product inventory. To counter this, apply a strict product-mapping layer that queries the real catalog. Unmatched items are filtered out. For example, if the LLM proposes “Dragonfruit Candy” but none exist, that recommendation is dropped. You can also maintain a quality assurance check using an automated or semi-automated pipeline that rejects items falling below certain engagement or inventory thresholds. Regular offline reviews and sampling help prune unwanted outputs.
Potential Follow-Up Question 2
How would you handle high-latency issues if you relied on LLM generation at query time?
Answer and Explanation
Running generation offline in batch mode is crucial. Store results in a key-value system for instant lookup during live traffic. The offline pipeline updates daily (or more frequently if needed), ensuring fresh suggestions without real-time LLM calls. This keeps search latency low. If near-real-time updates are required, consider incremental refreshes for trending queries or adopt a caching layer and selectively regenerate only for critical queries.
Potential Follow-Up Question 3
How can you evaluate the effectiveness of these new carousels without relying solely on direct relevance metrics?
Answer and Explanation
Discovery-oriented content aims to spark user interest, so standard relevance measures fall short. Use online experimentation to track engagement metrics like click-through rates, add-to-cart rates, and conversions. Track repeated interactions with recommended items over time. Cohort-based analyses can reveal if certain user segments respond better. You can also apply methods that sample real user feedback, including short surveys or star ratings for recommended products, and feed that data into your iterative improvement cycle.
Potential Follow-Up Question 4
What would you do if the advanced prompt still fails to steer the LLM correctly for certain niche queries?
Answer and Explanation
Enhance the domain signals or add more specialized examples to the prompt. For queries with unusual attributes or brand names, reference historical session data on next-converted search terms. Inject additional store or brand context into the LLM. If the LLM continues generating poor suggestions for certain queries, create a fallback system that either short-circuits to manual recommendations or falls back to a rules-based approach. Over time, fine-tune the prompts or use a specialized model that better captures niche domain knowledge.
Potential Follow-Up Question 5
How would you extend this system to further optimize inventory constraints?
Answer and Explanation
For items that sell out or have limited stock, tie your product-mapping layer to real-time inventory checks. If a recommended product goes out of stock, the system either demotes or removes it. If certain categories consistently go in and out of stock, maintain specialized logic or micro-models that incorporate inventory signals to reduce frustration. This can run as a final filter during retrieval and ranking. Re-rank or replace out-of-stock items with in-stock alternatives, maintaining an optimal user experience.