
ML Case-study Interview Question: Real-Time Ride-Sharing Fraud Detection Using an ML Pipeline with Kafka & Feature Stores


Case-Study question
You have joined a large-scale ride-sharing platform as a Senior Data Scientist. The platform faces significant fraud threats involving suspicious trip publications and fraudulent bookings. The business wants a real-time scoring pipeline that flags or blocks malicious users. The team expects you to propose how to design and build a machine learning pipeline for fraud detection, ensure correct feature engineering, and guarantee label quality for training and evaluation. Outline your approach to data ingestion, feature store usage, model training, and deployment. Propose a plan to continuously improve the models over time.
Detailed solution
Overview of pipeline design
Fraud detection systems must respond in near real-time to suspicious events and also sustain high uptime. The architecture must process each incoming event, compute a fraud score, and issue corrective actions if needed. Kafka can be used as the main event backbone to capture trip publications or bookings. A separate scoring service reads from Kafka, scores each event, then writes back a fraud score event to Kafka. Downstream services consume these scores to take actions like blocking the member or canceling the trip.
Infrastructure considerations
Event-driven design helps minimize downtime risk. The scoring service can break without impacting the user’s immediate experience, since it only listens to Kafka and then writes back a fraud score. Deploying it outside the core request flow ensures faster iterations. Feature retrieval at serving relies on a dedicated feature store. This store centralizes user-specific and ride-specific features in a key-value format, which the scoring service queries in real-time before producing an output.
Features for training and serving
Matching features at training and serving is crucial. Using production-generated feature vectors as the single source of truth eliminates inconsistencies. Each time a score is computed in production, the pipeline should store the exact input feature vector in the fraud score event. Later, these logged feature vectors are used to form the training set. This prevents data leakage and ensures that the model trains on the same representation available at inference.
Feature engineering at serving time can be done with transformations that rely on the feature store. For example, to compute “days since registration”, the pipeline retrieves the user’s registration date from the feature store, calculates the difference, and encodes it as an integer. Once done, that integer is included in the production feature vector, then captured in the fraud score event.
Label quality
A reliable labeling process is critical. Labels can come from manual reviews triggered by suspicious behaviors, random samples for unbiased checking, or user-initiated appeals to restore blocked accounts. Consolidating these into one master label table ensures consistent usage across dashboards, training, and evaluation. That table should maintain a single aggregated label for each user, considering all manual reviews and final judgments.
Models trained on these labels need to avoid mixing in labels derived from the same business rules that generated the training sample, as that can bias the model or lead to circular logic. Gathering enough manual reviews to have robust ground-truth is essential. Only after collecting enough labeled examples can you reliably evaluate model performance.
Model training and iteration
Choosing an algorithm like XGBoost, scikit-learn’s RandomForestClassifier, or logistic regression depends on the data volume and complexity. For demonstration, consider a logistic regression approach with L2 regularization. A central formula for logistic regression’s probability output p of fraud given features x is:
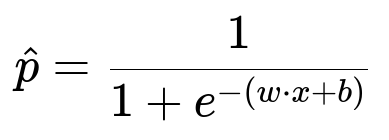
w represents model weights, x is the feature vector, and b is the bias term. For each training example, x is the same encoded vector that was used during serving. Minimizing the logistic loss function typically happens by gradient-based optimization on these labeled samples.
After training, the model’s performance should be tested on fresh data to guard against stale patterns. The final model is deployed to the scoring service. Any new features or transformations introduced must be validated in real-world traffic. This real-time feedback loop helps refine the pipeline.
Example code snippet for model inference
import joblib
import json
from kafka import KafkaConsumer
model = joblib.load("fraud_model.pkl")
consumer = KafkaConsumer('trip_publications', bootstrap_servers=['kafka_broker:9092'])
for message in consumer:
data = json.loads(message.value)
# data["features"] is the already encoded feature vector
features_vector = data["features"]
score = model.predict_proba([features_vector])[0][1]
# Produce a new event or call a downstream service with the 'score'
# ...
This pseudocode illustrates how the scoring service might listen to a Kafka topic, load a pre-trained model, and compute a fraud probability for each event.
Continuous improvement
Retraining the model regularly is critical, especially when fraud tactics evolve. Data scientists or ML engineers monitor shifts in feature distributions or label proportions. If you notice a spike in suspicious scores or a large volume of new fraudulent patterns, plan a retraining cycle. Additional transformations or new features can be introduced into the pipeline if relevant data is accessible in the feature store.
Possible follow-up questions and detailed answers
How would you handle label scarcity when few manual reviews are available?
Accurate labels come from manual investigation, which can be expensive. It helps to use random sampling to label a small subset of events so that you get an unbiased measure of fraud. Active learning can be employed to focus labeling efforts on uncertain cases (where the model is least confident). Maintaining a queue of high-risk events and another queue of random events for labeling creates a balanced set. The pipeline must store these labeled results in the master label table. This approach broadens the coverage of your labeled examples and reduces label noise.
How do you evaluate model performance without letting business rules bias the evaluation?
Separating the labeling mechanism from the business rules is key. If a user is flagged by a rule, that alone should not decide the label. The final label must come from a human-driven manual review or another authoritative source. A purely rule-based label can bias the model toward learning the rule rather than detecting underlying fraud patterns. In practice, the random sampling queue is valuable because it produces a more trustworthy ground truth. Evaluation should focus on that portion of the data. This decoupled approach ensures that performance metrics like precision or recall reflect the true detection power of the model, not just how it overlaps with old rules.
How do you keep data fresh when fraud patterns change rapidly?
Collecting fresh logs from production is the best safeguard. If the feature vector at serving is persistently streamed, then the training pipeline can rebuild a dataset using only recently gathered examples. Old data might not mirror the newest fraud patterns, so limiting the training window to, say, 30 days can help. Rolling retrains, possibly weekly or monthly, keep the model updated. Monitoring the fraction of novel cases or drift in feature distributions can prompt a fresh training cycle when changes exceed a threshold.
How do you mitigate the risk of data leakage?
One strict approach is to use exactly the same code path for feature transformations in training and inference. Relying on the final encoded vector stored in the fraud score event at serving time, then retrieving it for training, removes discrepancies. This means the training pipeline never re-computes features independently. Another safeguard is ensuring that no future information from after the label date seeps into the training example. Using point-in-time features from the feature store and logging them at the moment of inference is a good practice to stop label leakage.
What if we want advanced features that require large historical windows?
When large historical windows are essential, it may be necessary to backfill older data. However, that can cause mismatch between training and serving, because the production system only started logging features after a certain date. A practical compromise is to do backfilled features for training and rely on real-time features for validation. This approach ensures the final model is tested on data that accurately replicates how features appear in real-time. The pipeline must handle older data carefully and fill missing values systematically for examples that predate the feature’s availability.
What strategies do you use to handle system errors or outages?
Deploying the model outside the critical user path prevents system failures from blocking transactions. Even if the scoring system goes down temporarily, the rest of the product remains functional. Building an alerting system that monitors the volume of fraud score events is vital. If the scoring volume drops abnormally, that signals potential outages. Storing a queue of unprocessed Kafka messages also helps. Once the scoring service is back online, it can read the backlog of messages and compute their scores. This architecture prevents data loss and keeps reliability high.
How would you scale this solution as user volume grows?
Scaling primarily involves handling bigger Kafka throughput, more complex transformations, and larger models. Horizontal scaling of the feature store and Kafka cluster is a standard method. Multiple scoring service instances can share the load by consuming from different Kafka partitions. Monitoring CPU usage, memory consumption, and response times is important. If latency rises, you can spin up more consumer instances. For the training pipeline, distributed frameworks like Spark or Dask can handle large-scale data processing. Model parallelism or cloud-based services can speed up retraining when data volume is massive.
How do you extend or generalize this pipeline to new fraud patterns?
Modular design helps. Each new fraud pattern can prompt new features in the feature store. The pipeline automatically includes these features in the fraud score event. When training a new model, these features become available. If a new user flow emerges, ensure it generates Kafka events that capture relevant attributes. Then the same pipeline architecture applies: push those events to the scoring service, read from the feature store, and stream the output to Kafka. This standardized approach adapts to new product features or new threats.
How to handle real-time model updates?
Real-time or near-real-time updates can be done using a champion-challenger approach. The champion is the current production model. The challenger is a newly trained model. Send traffic to both models in parallel for a short time, compare results, and gather performance metrics. If the challenger outperforms on certain metrics, switch it to become the champion. This approach ensures that updates happen smoothly with minimal risk. Rolling back is easy if unexpected issues arise.
Conclusion
This fraud detection pipeline hinges on consistent feature ingestion, high-quality labels, and well-architected real-time streaming. Consolidating features in a store, ensuring the same vector is used in training and inference, and rigorously managing labels produce a resilient system. Continuous retraining and monitoring safeguard against evolving fraud patterns. This approach ensures both immediate responsiveness and long-term adaptability, which aligns with the heavy demands of a large-scale ride-sharing platform.