
ML Case-study Interview Question: XGBoost Counterfactual Forecasting for Measuring Retail Promotion Sales Uplift


Case-Study question
A large retail chain needs to evaluate the profitability of its past in-store promotions. They have historical daily sales data enriched with promotion metadata (promotion type, start date, end date). They want to quantify the incremental sales (uplift) produced by each promotion compared to what would have happened with no promotion. They have no direct baseline for non-promotion sales. They also have extensive historical sales data for periods with no promotions. They need a predictive model that retrospectively infers these “no promotion” baselines, then compares them with actual promotional sales, yielding the incremental effect. How would you build and deploy a model to accomplish this? How would you handle data quality issues, model training, and proper back-testing for something that never occurred?
Proposed Detailed Solution
Build a counterfactual forecasting system. Train on non-promotion periods and then infer hypothetical “no promotion” sales for each promotion window. Compare predicted baseline with actual promotional sales. The difference gives uplift.
Start by gathering daily sales data with clear product and date fields, then join it with promotion data. Watch for long or overlapping promotions that reduce non-promotional data. Choose a time granularity that balances interpretability (for instance, product X day) with data continuity. If data is too sparse, consider a higher level like product-family X day.
Use a two-stage approach. First, experiment with a forecasting library (Prophet) to grasp seasonality, trends, and holiday patterns. Then switch to XGBoost if you need more speed and the ability to handle non-linear feature interactions. Build features that capture temporal dynamics. Include past sales lag, day-of-week, seasonality flags, holiday flags, store-closure flags, and prior promotion presence indicators.
Train the model on periods without promotions. Then apply the trained model to promotion windows in the past. In normal forward forecasting, we train on historical data and predict future. Here, we study a prior interval with promotions. We still train on non-promotional days from the entire historical range. Then we make predictions for the promotional periods. This does not violate data leakage because we focus on explaining a past scenario. We aim to estimate a hypothetical baseline. Subtracting the predicted baseline from real observed promotional sales gives uplift.
Evaluate the model. True “no promotion” sales during actual promotion days do not exist, so direct error metrics on these days are impossible. Use cross-validation only on non-promotion days, where the ground-truth is known. Compare predicted sales vs actual sales for these non-promotion windows, then compute forecast accuracy.
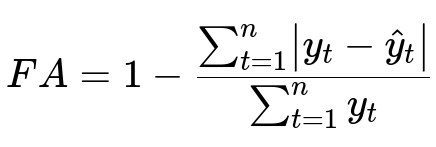
Here, y_t is actual sales on day t without promotion, and hat{y}_{t} is predicted sales on day t. The sum runs over all validation days in non-promotion periods.
If the model demonstrates strong accuracy (close to 90% or more), you can trust its counterfactual estimates. Next, interpret the uplift for each promotion. Then integrate business-level logic. Long-running promotions risk minimal non-promotion data for training. External factors like media campaigns or competitor pricing are unmodeled and can inflate or reduce predicted uplift. Include these factors if data is available.
Enhance with extra components if time allows. Measure cannibalization (the negative effect on close substitutes), halo (positive effect on complementary products), anticipation (people waiting for promotions), and storage (stockpiling enough goods to reduce future sales). These effects refine net increment. If you must forecast profitability for future promotions, feed the baseline model with predictions from a standard sales forecaster. Finally, formulate an optimization engine that tries different promotion schedules and picks the best plan for maximizing business metrics like ROI.
Example Code Snippet
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
# Assume df has columns: ['date', 'product_id', 'sales', 'promotion_flag', 'some_features', ...]
# Filter data for non-promotion rows
df_no_promo = df[df['promotion_flag'] == 0].copy()
# Prepare features and target
X = df_no_promo[['some_features', 'lag_sales_1', 'lag_sales_7', 'holiday_flag', ...]]
y = df_no_promo['sales']
# Split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, shuffle=False)
# Train XGBoost
model = xgb.XGBRegressor(n_estimators=100, max_depth=5, learning_rate=0.1)
model.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=10)
# Predict baseline on promotion periods
df_promo = df[df['promotion_flag'] == 1].copy()
X_promo = df_promo[['some_features', 'lag_sales_1', 'lag_sales_7', 'holiday_flag', ...]]
promo_baseline_pred = model.predict(X_promo)
# Calculate uplift
df_promo['uplift'] = df_promo['sales'] - promo_baseline_pred
Avoid training Prophet or XGBoost on the intervals of promotional data. Train only on clean non-promotion windows, then infer on the promotion intervals. This preserves consistency for “what if there was no promotion.”
Additional Implementation Notes
Combine classical time-series domain knowledge (seasonality and holiday effects) with local store information. Validate your final approach on non-promotion windows via cross-validation, so the accuracy metric remains meaningful. If promotion periods are frequent or overlapping, reduce the modeling granularity or switch to product-family to get stable daily patterns.
How would you incorporate cannibalization and halo effects?
Model them by grouping related items into the same system. For cannibalization, measure how a promotion on one product affects similar products. For halo, measure how often customers buy complementary items alongside the promoted product. Build interaction features that track the presence of a promotion on one product while modeling the sales of another. This expands the baseline model to multiple correlated time series.
What if promotions run for many days, leaving limited training data?
Aggregate the data at product-family level or weekly level to increase the share of non-promotional windows. Another idea is ignoring overly long promotions that hamper model training. Consider ignoring products that are constantly in promotion or skip those with insufficient baseline windows.
How can you prove the method is unbiased if we never see real “no promotion” sales?
Use back-testing with cross-validation only on non-promotion windows. Compare predictions and actuals on those segments. If the model aligns well (accuracy near 90%), trust its baseline for promotion windows. The real “no promotion” sales during actual promotion intervals remain unknown, but the model’s error on known windows is the best gauge.
How do you optimize future promotions once you have a baseline?
Feed future predictions from a standard sales forecaster into your baseline model for hypothetical “no promotion” sales. Subtract from predicted “promotion sales” that you estimate from a separate model or business rules. Identify promotion setups (discount depth, start date, end date) that maximize uplift minus costs. Then run an optimization routine to search for the best combination of promotion parameters.
How do you deploy this?
Package the training pipeline (data cleaning, feature creation, model fitting) into a reproducible script or notebook. Schedule it periodically. Store results in a robust environment or data warehouse. Offer a user-facing interface that shows each past promotion’s baseline and uplift. For future promotions, expose an interface to input planned promotion parameters and return estimated ROI. Automate retraining periodically to capture shifting demand trends.
Use thorough documentation, consistent code reviews, and performance monitoring. Log actual vs predicted results for each promotion, so the business sees the incremental revenue or shortfall. This ensures iterative improvement.
What steps reduce risk of data leakage?
Never train on actual promotion data for baseline forecasting. Correctly handle time lags. Avoid using future sales as a feature for the same time step. Ensure no overlap of promotional signals in the training set for baseline estimation. Stick with purely non-promotion windows for training.
Could you handle external factors like media campaigns?
Yes, if the data is available. Add these campaigns as external features. Label each date with a flag indicating presence of a major advertising effort. Let the model learn how these external factors boost baseline. Unmodeled external factors might cause over- or under-estimates of uplift, so external variables help refine accuracy.
How do you handle intermittent or low-volume sales?
Aggregate or cluster items. Products with near-zero daily sales cannot train stable time-series models. Summarize them at a category or brand level to smooth out data. This reduces granularity but keeps forecasts more consistent.
How would you explain the model to non-technical stakeholders?
Use simple visuals showing actual vs baseline sales on a time chart. Highlight differences during promotion days. Emphasize that the baseline is predicted from periods without promotions. Show how the forecast accuracy on non-promotion days is strong. Provide narrative that incremental sales reflect the net gain from running the promotion.
How do you assess ROI?
Multiply uplift by profit margin. If incremental revenue minus promotion costs (discount margin, marketing expenses) is positive, the promotion is profitable. Summarize at product level or roll up to store or region.
Conclusion
Build a robust counterfactual baseline model using historical non-promotion data. Generate a reliable baseline. Compare that with actual sales to isolate promotional uplift. Refine the approach by modeling cannibalization, halo, anticipation, and storage. Proceed to forecasting future promotions with stacked models, then optimize the entire promotion plan.